10 Сравнение средних по группам
10.1 T-тест
Первым из статистических критериев мы рассмотрим один из самых простых вариантов – т-тест.
Это статистический критерий, распределение которого относится к семейству Т-распределений – очень похоже на нормальное, но с более приподнятыми хвостами. Используется для сравнения средних двух групп, измеренных в метрической (количественной) шкале. Для остальных шкал т-тест не подходит (хотя признаки, измеренные по шкале Лайкерта, например, по шкале от 1 до 5, иногда могут приписываться к количественным измерениям, но в рамках этого курса мы не будем это затрагивать)
Нулевая и альтернативная гипотезы:
\(H_0\): \(\mu_1 = \mu_2\)
\(H_1\): \(\mu_1 \neq \mu_2\)
Вернемся к данным про студентов и нашим вопросам и разберем теперь следующий вопрос:
- Отличается ли статистически значимо средний балл по математике у тех, кто чаще или реже пропускает занятия?
| student | school | sex | age | address | famsize | Pstatus | Medu | Fedu | Mjob | Fjob | reason | guardian | traveltime | studytime | failures | schoolsup | famsup | paid_mat | activities | nursery | higher | internet | romantic | famrel | freetime | goout | Dalc | Walc | health | absences_mat | G1_mat | G2_mat | G3_mat | paid_por | absences_por | G1_por | G2_por | G3_por | G_mat | G_por | absences_mat_groups | absences_por_groups |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id1 | GP | F | 18 | U | GT3 | A | 4 | 4 | at_home | teacher | course | mother | 2 | 2 | 0 | yes | no | no | no | yes | yes | no | no | 4 | 3 | 4 | 1 | 1 | 3 | 6 | 5 | 6 | 6 | no | 4 | 0 | 11 | 11 | 5.666667 | 7.333333 | middle | less |
| id2 | GP | F | 17 | U | GT3 | T | 1 | 1 | at_home | other | course | father | 1 | 2 | 0 | no | yes | no | no | no | yes | yes | no | 5 | 3 | 3 | 1 | 1 | 3 | 4 | 5 | 5 | 6 | no | 2 | 9 | 11 | 11 | 5.333333 | 10.333333 | less | less |
| id4 | GP | F | 15 | U | GT3 | T | 4 | 2 | health | services | home | mother | 1 | 3 | 0 | no | yes | yes | yes | yes | yes | yes | yes | 3 | 2 | 2 | 1 | 1 | 5 | 2 | 15 | 14 | 15 | no | 0 | 14 | 14 | 14 | 14.666667 | 14.000000 | less | less |
| id5 | GP | F | 16 | U | GT3 | T | 3 | 3 | other | other | home | father | 1 | 2 | 0 | no | yes | yes | no | yes | yes | no | no | 4 | 3 | 2 | 1 | 2 | 5 | 4 | 6 | 10 | 10 | no | 0 | 11 | 13 | 13 | 8.666667 | 12.333333 | less | less |
| id6 | GP | M | 16 | U | LE3 | T | 4 | 3 | services | other | reputation | mother | 1 | 2 | 0 | no | yes | yes | yes | yes | yes | yes | no | 5 | 4 | 2 | 1 | 2 | 5 | 10 | 15 | 15 | 15 | no | 6 | 12 | 12 | 13 | 15.000000 | 12.333333 | middle | middle |
| id7 | GP | M | 16 | U | LE3 | T | 2 | 2 | other | other | home | mother | 1 | 2 | 0 | no | no | no | no | yes | yes | yes | no | 4 | 4 | 4 | 1 | 1 | 3 | 0 | 12 | 12 | 11 | no | 0 | 13 | 12 | 13 | 11.666667 | 12.666667 | less | less |
| id8 | GP | F | 17 | U | GT3 | A | 4 | 4 | other | teacher | home | mother | 2 | 2 | 0 | yes | yes | no | no | yes | yes | no | no | 4 | 1 | 4 | 1 | 1 | 1 | 6 | 6 | 5 | 6 | no | 2 | 10 | 13 | 13 | 5.666667 | 12.000000 | middle | less |
| id9 | GP | M | 15 | U | LE3 | A | 3 | 2 | services | other | home | mother | 1 | 2 | 0 | no | yes | yes | no | yes | yes | yes | no | 4 | 2 | 2 | 1 | 1 | 1 | 0 | 16 | 18 | 19 | no | 0 | 15 | 16 | 17 | 17.666667 | 16.000000 | less | less |
| id10 | GP | M | 15 | U | GT3 | T | 3 | 4 | other | other | home | mother | 1 | 2 | 0 | no | yes | yes | yes | yes | yes | yes | no | 5 | 5 | 1 | 1 | 1 | 5 | 0 | 14 | 15 | 15 | no | 0 | 12 | 12 | 13 | 14.666667 | 12.333333 | less | less |
| id11 | GP | F | 15 | U | GT3 | T | 4 | 4 | teacher | health | reputation | mother | 1 | 2 | 0 | no | yes | yes | no | yes | yes | yes | no | 3 | 3 | 3 | 1 | 2 | 2 | 0 | 10 | 8 | 9 | no | 2 | 14 | 14 | 14 | 9.000000 | 14.000000 | less | less |
Мы уже обсуждали в предыдущей главе, что ЗП здесь – средний балл по математике (колонка G_mat), НП – количество пропусков занятий по этом предмету (absences_mat). И ЗП, и НП – количественные, закодированы в шкале отношений. Значит, можем пользоваться той веткой статистических тестов, которая подходит для количественных ЗП.
Пройдем по алгоритму выбора статистического теста: https://miro.com/app/board/uXjVOxmKhr8=/?share_link_id=245423331470
Помимо основных отраженных ответвлений, видим, что для каждого критерия существует ряд допущений.
Допущения (assumptions) – это утверждения про характер наших данных, без соблюдения которых параметрические тесты будут работать некорректно (поэтому их никто и не любит).
10.1.1 Допущения для т-теста
- Данные распределены нормально (или, если измеряемый признак является случайной велиичной, в группах больше 30 наблюдений) – обсуждали эту проверку здесь
- Дисперсии однородны (гомогенны) – проверяется с помощью теста Ливеня (Homogeneity of Variance test, он же Levene’s test).
10.1.2 Непараметрические аналоги
В случае, если допущения нормальности и однородности дисперсий нарушаются, мы не можем использовать т-тест.
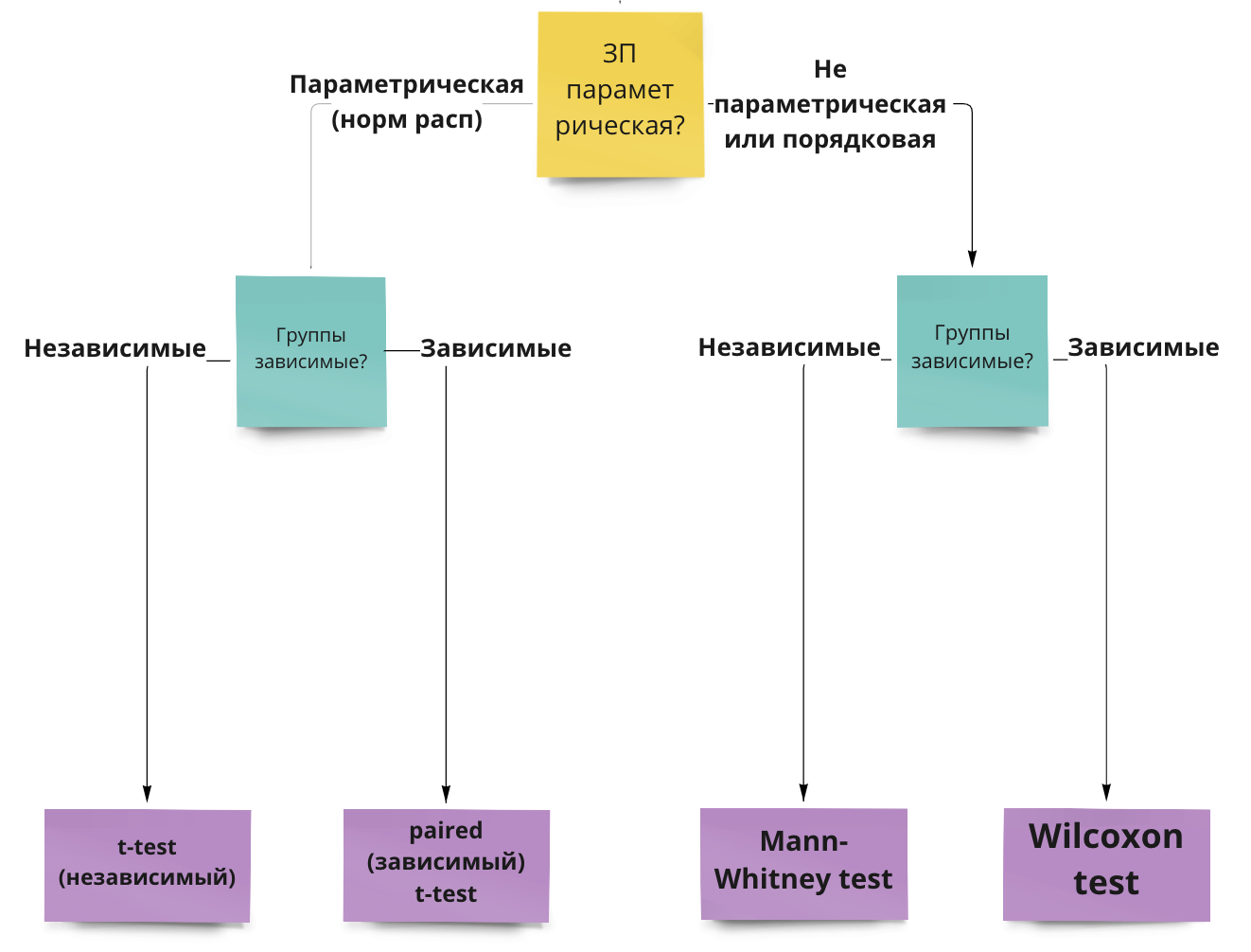
10.1.3 Независимые и парные тесты
Тут тоже все довольно просто:
- Если у нас независимые выборки, то мы используем независмый т-тест или его непараметрический аналог – тест Манна-Уитни.
- Если выборки зависимые, то мы используем парный т-тест или его непараметрический аналог – тест Вилкоксона.
Обилие наименований может быть пугающим, но по сути, это один и тот же тест с небольшими поправками – просто в разных названиях увековечено больше статистиков!
10.1.4 Вычисление т-теста и непараметрических аналогов
Средний балл и стандартное отклонение в группах тех, кто прогуливает меньше всего (на паре мы назвали их прихожанами):
## # A tibble: 1 × 3
## mean sd n
## <dbl> <dbl> <int>
## 1 11.2 3.70 207Средний балл в группах прогулищиков:
## # A tibble: 1 × 3
## mean sd n
## <dbl> <dbl> <int>
## 1 10.2 3.52 22students %>%
filter(absences_mat_groups != "middle") -> students_2
t.test(students_2$G_mat ~ students_2$absences_mat_groups, paired = FALSE)##
## Welch Two Sample t-test
##
## data: students_2$G_mat by students_2$absences_mat_groups
## t = 1.2839, df = 26.204, p-value = 0.2104
## alternative hypothesis: true difference in means between group less and group more is not equal to 0
## 95 percent confidence interval:
## -0.6112609 2.6475660
## sample estimates:
## mean in group less mean in group more
## 11.23027 10.21212
10.2 ANOVA (дисперсионный анализ)
ANOVA (ANalysis Of VAriance) – статистический критерий, распределение и ключевая статистика которого относятся к семейству F-распределений. Это то чуть скошенное влево распределение, уже сильно отличающееся от нормального. На этом распределении мы (точнее специально обученные программы) будут располагать F-значение, которое будет вычисляться. Этот критерий используется, когда зависимая переменная (ЗП) измерена в метрической (количественной) шкале, а независимые переменные (НП) – категориальные (порядковые или номинативные). ANOVA применяется, когда число проводимых сравниваемых становится больше двух – то есть, либо это одна НП, которая может принимать три значения (уровня), либо число НП больше или равно двум.
ANOVA используется тогда, когда число сравнений, которые нам нужно сделать, становится больше двух. Можно сделать и два сравнения с помощью ANOVA, но это будет бессмысленно, так как по сути это старый добрый т-тест.
Нулевая и альтернативные гипотеза для ANOVA:
\(H_0\): \(\mu_1 = \mu_2 = ... =\mu_n\)
\(H_1\): Есть хотя бы одно неравенство: \(\mu_1 \neq \mu_2 \neq ... \neq \mu_n\)
Как вообще получается, что нам нужно сделать больше двух сравнений?
10.2.1 Факторы и уровни
Фактором или предиктором в линейных моделях и дисперсионном анализе называется независимая переменная.
Как правило, мы применяем ANOVA для сравнения групп, поэтому эта независимая переменная – категориальная, она принимает конечное число значений. Значений НП – это те группы, которые мы сравниваем между собой, они называются уровнями НП или уровнями фактора.

В зависимости от числа НП и уровней НП можно конкретизировать экспериментальный план и план для ANOVA:

10.2.2 Почему он дисперсионный
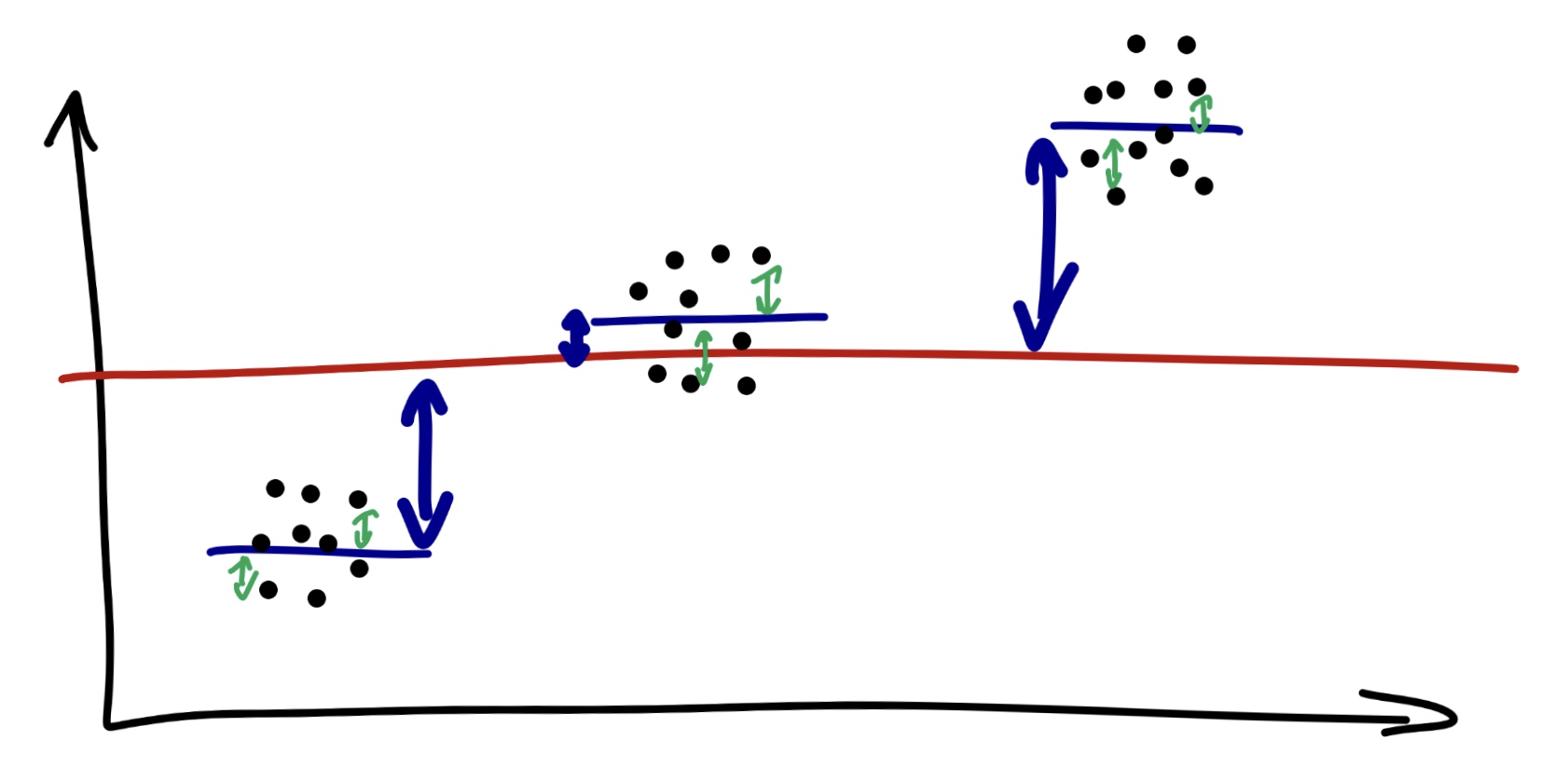
Чтобы перейти к непосредственно анализу, надо немного разобраться, что это воообще за метод, и почему он называется дисперсионным, хотя предположения мы строим, как и в большинстве статистических критериев, относительно средних значений по группам. Дело в том, что этот метод действительно учитывает дисперсию, а точнее, разницу дисперсий. Математика ANOVA основана на том, что при объединении нескольких выборок с примерно одинаковой дисперсией, но разными средним, дисперсия увеличивается пропорционально средним этих значений. Это связано с тем, что всю дисперсию можно разделить на межгрупповую и внутригрупповую. Если окажется, что дисперсия между группами больше, чем внутри, то можно сделать вывод в пользу различий между группами. Для того, чтобы зафиксировать различия между группами, внутригрупповая дисперсия здесь должна быть как можно меньше: чем она меньше внутри групп и больше между групп, тем более серьезный вывод об отличиях групп мы сможем сделать.
F-значение считается, по сути, как отношение дисперсий двух групп.
В качесте дисперсии для математики ANOVA обычно берется только ее числитель, без деления на число элементов в группе (а саму дисперсию мы считали здесь. Числитель дисперсии без знаменателя – это сумма квадратов (Sum of Squares)
\(D = \frac{\sum_{i=1}^{n} (x_i - \overline{x})^2}{n}\)
Заодно вспомним, что стандартное отклонение – это корень из дисперсии:
\(\sigma = \frac{\sum_{i=1}^{n} (x_i - \overline{x})}{\sqrt{n}}\)
А сумма кавдратов – это числитель дисперсии, SST (Sum of Squares Total):
\(SST = \sum_{i=1}^{n} (x_i - \overline{x})^2\)
Общая сумма квадратов SST складывается из межгрупповой суммы квадратов (SSE, Sum of Squares Explained или SSB, Sum of Squares Between groups) и внутригрупповой (SSR, Sum of Squares Random или SSW, Sum of Squares Within groups)
\(SST = SSE + SSR\)
Предположим, что у нас есть m групп по n наблюдений в каждой из них (для простоты возьмем равные по численности группы). Тогда общая сумма квадратов (дисперсия без знаменателя) равна:
\(SST = \sum_{i=1}^{m \times n} (x_i - \bar x)^2\)
Как вычислить межгрупповую и внутригрупповую сумму квадратов?
\(SSE = \sum_{j=1}^m (\bar x_j - \bar x)^2\)
\(df_{SSE} = m-1\), m – количество групп
\(SSR = \sum_{j=1}^m\sum_{i=1}^n (x_{ij} - \bar x_j)^2\)
\(df_{SSR} = m \times n - m\), n – количество элементов во группе, m – число групп
Желаемый результат здесь – наименьшее значение SSR (внутригрупповой) и наибольшее SSE (межгрупповой).
Отсюда логически вытекает один из важных показателей для интпреретации результатов ANOVA:
\(R^2 = \frac{SSE}{SST} = 1 - \frac{SSR}{SST}\) – процент объясненной факторами дисперсии (коэффициент детерминации), то есть то, насколько хорошо наши факторы объясняют изменчивость данных.
А до подсчета F-значения остается один шаг – посчитать средние суммы квадратов, то есть поделить их на число степененй свобооды для каждой суммы квадратов (точно так же, как мы делили дисперсию на число наблюдений! Возвращаемся к ее смыслу)
\(MSE = \frac{SSE}{df_{SSE}} = \frac{SSE}{m-1}\)
\(MSR = \frac{SSR}{df_{SSR}} = \frac{SSR}{m \times n - m}\)
И можем посчитать F-значение, которое будем располагать на F-распределении (напомню, что за нас обычно это делают специально обученные машины)
\(F = \frac{MSE}{MSR} = \frac{SSE \times (m \times n - m)}{(m-1) \times SSR}\)
10.2.3 F-распределение (Фишера)
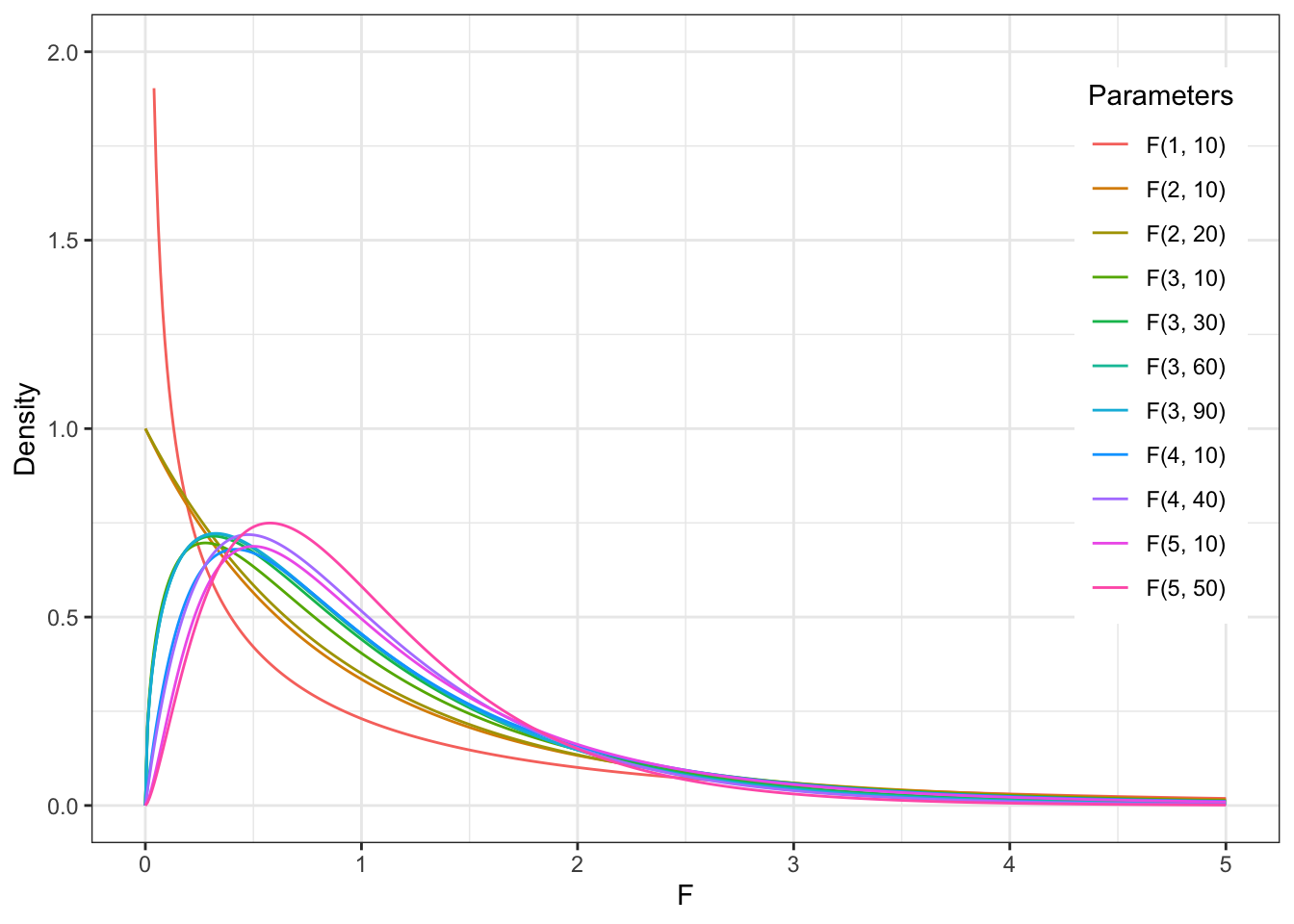
F-распределение или распределение Фишера – это распределение величины, которая высчитывается как отношение средних квадратов внутригрупповой и межгрупповой изменчивости (очень похоже на дисперсию) и включает туда рассчитанное количество степеней свободы для внутригрупповой и межгрупповой изменчивости. При очень большой выборке, большом значении степеней свободы, оно тоже будет походить на нормальное!
При малом числе степеней свободы (малой выборке) F-распределение визуально отличается от нормального – но для проверки допущения это не имеет никакого значения, так как это распределение F-статистик, а не зависимой переменной – к ним все еще действует допущение о нормальности или большог ообъема выборки.
10.2.4 Допущения для ANOVA
Пройдем по алгоритму выбора статистического теста: https://miro.com/app/board/uXjVOxmKhr8=/?share_link_id=245423331470
Помимо основных отраженных ответвлений, для каждого критерия существует ряд допущений.
Допущения (assumptions) – это утверждения про характер наших данных, без соблюдения которых параметрические тесты будут работать некорректно (поэтому их никто и не любит).
- Данные распределены нормально (или, если измеряемый признак является случайной велиичной, в группах больше 30 наблюдений) – обсуждали эту проверку здесь
- Если независимые – дисперсии однородны (гомогенны), проверяется с помощью теста Левеня (Levene’s Test of Homogeneity of Variance), если зависимые группы – сферичность дисперсий, проверяется с помощью теста на сферичноость (Sphericity test, Mauchly test)
10.2.5 Непараметрические аналоги
В случае, если допущения нормальности (помним, что это скорее про большое число наблюдений в выборке и визуально значительное отличие от гауссианы) и однородности дисперсий нарушаются, мы не можем использовать ANOVA, и нужно использовать непараметрические аналоги .
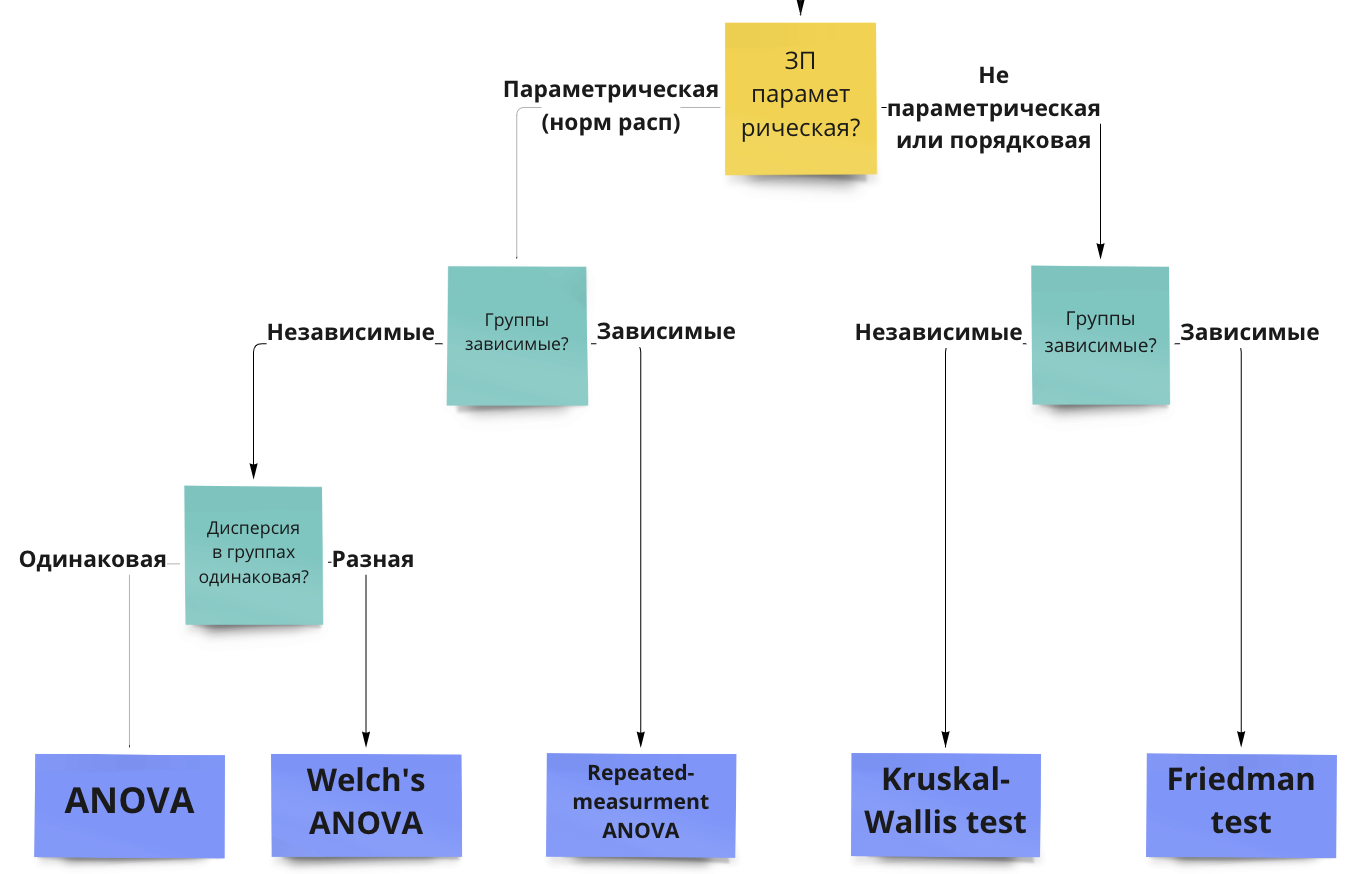
10.2.6 Просто ANOVA и с повторными измерениями
Тут тоже все довольно просто:
- Если у нас независимые выборки, то мы используем ANOVA или его непараметрический аналог – тест Краскелла-Уоллиса.
- Если выборки зависимые, то мы используем ANOVA c повторными измерениями (repeated measures) или его непараметрический аналог – тест Фридмана.
Обилие наименований может быть пугающим, но по сути, это один и тот же тест с небольшими поправками – просто в разных названиях увековечено больше статистиков!
10.2.7 Нелинейные эффекты
Большое преимущество в сравнении трех и более групп – такие сравнения позволяют выявить нелинейные эффекты.

10.2.8 Многофакторый ANOVA и взаимодействие факторов
Многофакторный ANOVA – тот же ANOVA, только когда у нас больше одной независимой переменной (фактора). Многофакторный ANOVA обычно обозначается примерно так: \(ANOVA \ 2 \times 3\) – это значит, что у нас два фактора, 2 уровня в первом фактора и 3 уровня во втором.
Многофакторный ANOVA интересен тем, что позволяет изучать еще и взаимодействие этих НП. Нелийность одного фактора может накладываться на нелинейность другого, или эффект фактора может проявиться только в определенных специальных условиях – за этим нужен многофакторный дизайн. Например, мы исследуем ту же концентрацию кофеина на внимание, даем испытуемым выпить 1 или 2 кружки кофе, а еще хотим поизучать этот эффект в зависимости от времени суток, в которое испытуемые выписывают кофе. Может оказаться, что эффект кофеина на внимание растет с увеличением концентрации кофе, но это происходит только в утренние часы – а в вечернее время не обнаруживается разница во внимании, 1 и 2 кружки кофе действует абсолютно оодинаково. Это назвается взаимодействием фактором и проявляется, когда у нас в исследовании 2 и более НП.
Визуально взаимодействие проявляется так: если нарисовать график зависимой переменной от одного из факторов и поместить на этот график линию, соответствующую другому фактору, то если линии окажутся не параллельны – то можно говорить о наличии взаимодействия.
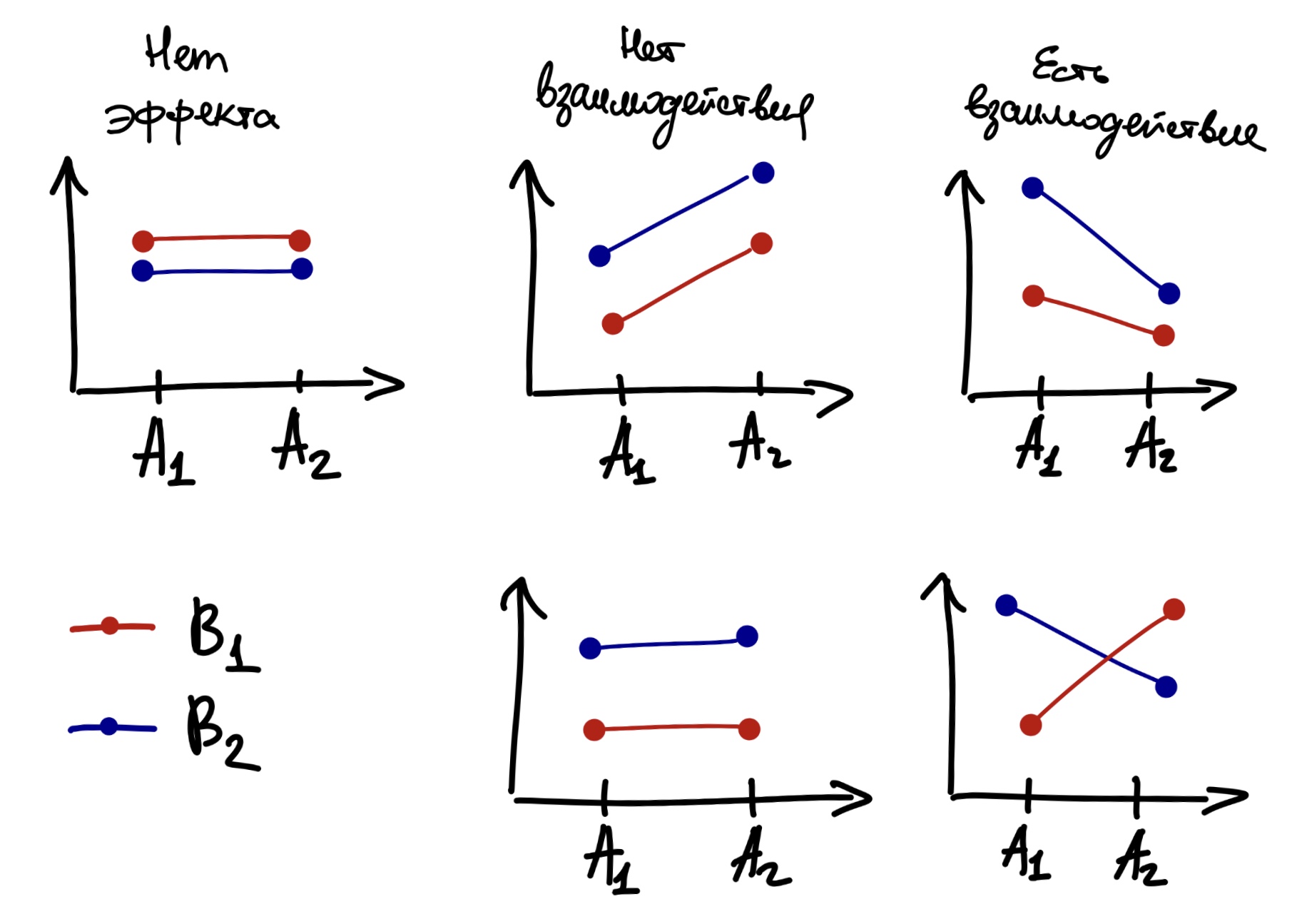 Картинка отсюда
Картинка отсюда
В случае нескольких факторов (независимых переменных), расчет и логика применения ANOVA точно такие же, добавляется только еще один фактор и взаимодействие первогоо фактора со вторым:
\(SST = SSE_{factor1} + SSE_{factor2} + SSE_{factor1} \times SSE_{factor2} +SSR\)
10.2.9 Пост-хоки и множественные сравнения
Допустим, мы провели ANOVA (любой из его видов), сравнили полученное p-значение с \(\alpha\), и оказалось, что p-значение < \(\alpha\), и мы можем отвергнуть нулевую гипотезу \(H_0\) в пользу альтернативной \(H_1\). Значит ли это, что отличаются средние во всех группах? Или может быть так, что \(\mu_1 = \mu_2\) и \(\mu_1 \neq \mu_3\)? Может.
ANOVA говорит, что в каких-то группах есть значимые отличия между средними, но не говорит, в каких именно. А чтобы узнать, в каких группах есть значимые отличия, нужно провести серию пост-хок (post hoc), апостериорных тестов. Это просто попарные т-тесты (разбирали их здесь) для сравнения каждого уровня НП с каждым, но уже с поправкой на множественные сравнения.
Что это за поправки? Они нужны нам, чтобы ибежать увеличения ошибки первого рода. Оказывается, что если мы на оодних и тех же данных будем тестировать несколько гипотез, то вероятность случайно получить статистически значимые различия будет увеличиваться пропорционально количеству тестируемых гипотез, то есть сделанных сравнений! Это происхоодит потому, что нарушается важное предположение о независимости наших выводов.
И вероятность сделать ложноположительный вывод будет уже никак не 0.05, а гораздо больше. Чтобы этого избежать, вводятся поправки на множественные сравнения, которые корректируют уровень \(\alpha\) и занижают его.
Самые популярные поправки:
- Бонферонни
- Тьюки
- FDR
Попарные пост-хок тесты нужны, когда результаты ANOVA оказались значимыми – это следующий шаг, чтобы разобраться, какие именно уровни факторов или их взаимодействия внесли значимость. Если ANOVA не значим, то последующие попарные сравнения не нужны – у нас совсем ничего не значимо (вспоминаем, что нулевой гипотезой для ANOVA является наличие хотя бы одного отличающегося среднего), так что и сравнивать нечего.
10.2.10 Вычисление ANOVA и непараметрических аналогов
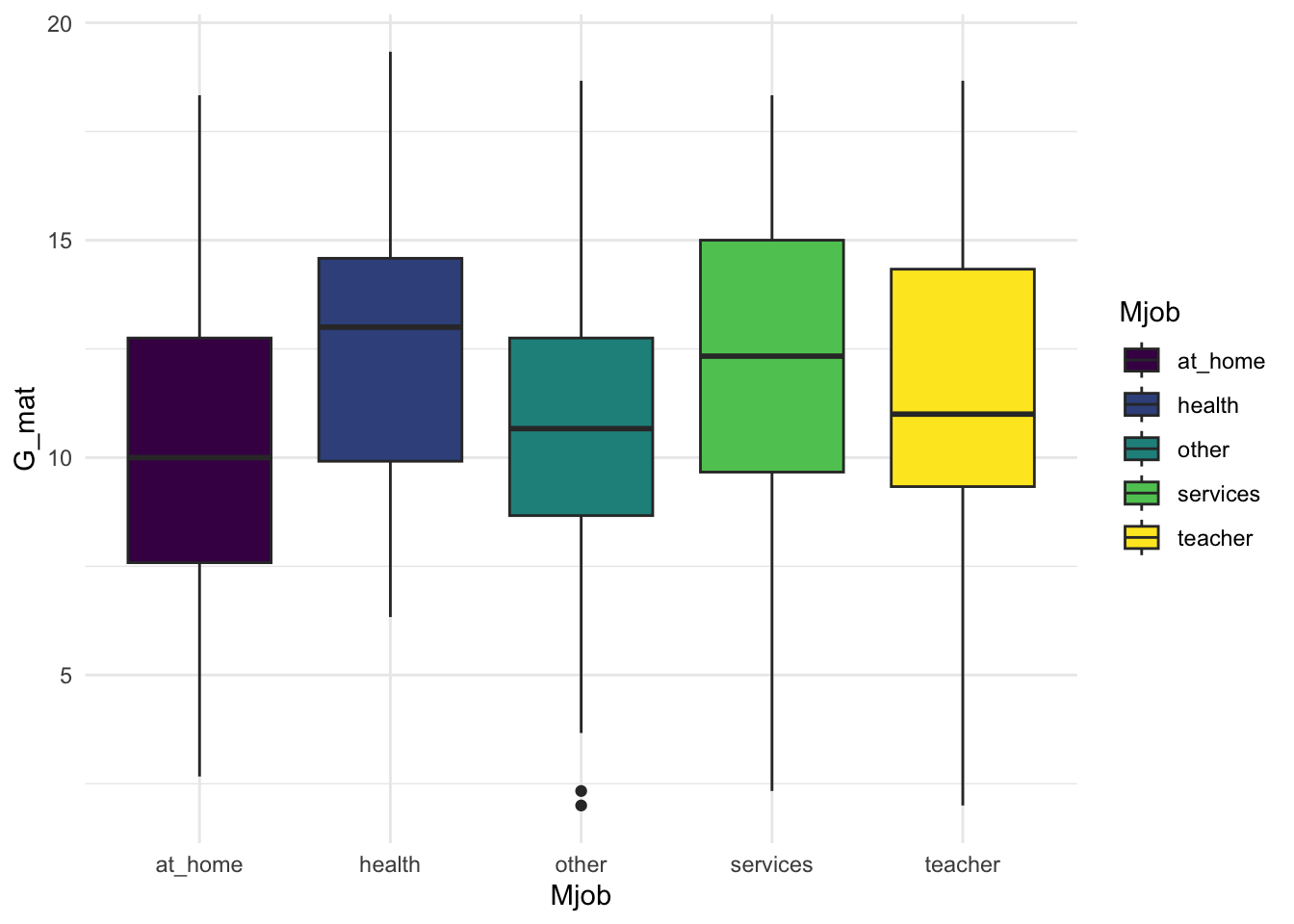
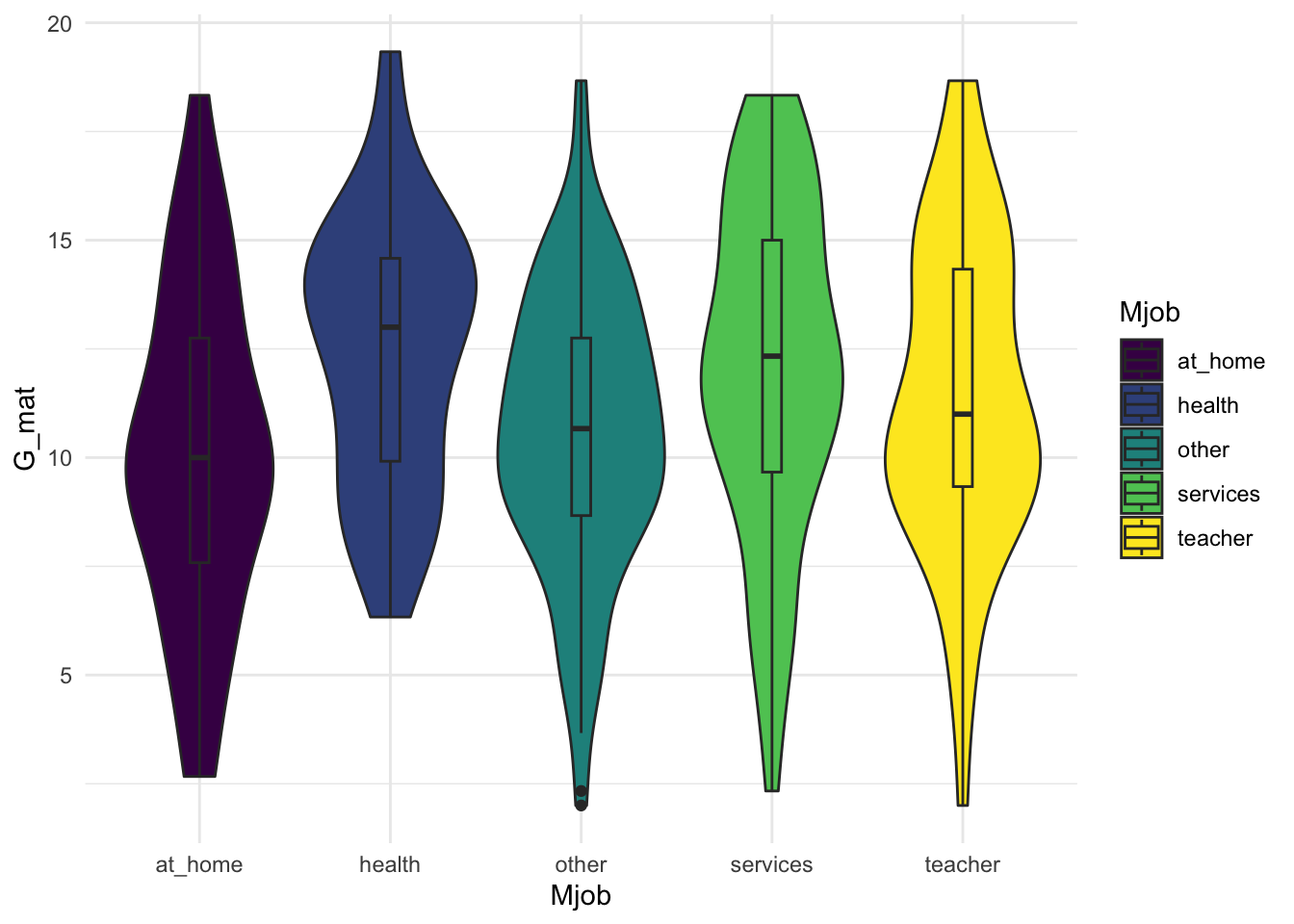
Посмотрим опять на данные и поисследуем зависимость балла по математике (переменная G_mat) от работы матери (переменная Mjob).
| student | school | sex | age | address | famsize | Pstatus | Medu | Fedu | Mjob | Fjob | reason | guardian | traveltime | studytime | failures | schoolsup | famsup | paid_mat | activities | nursery | higher | internet | romantic | famrel | freetime | goout | Dalc | Walc | health | absences_mat | G1_mat | G2_mat | G3_mat | paid_por | absences_por | G1_por | G2_por | G3_por | G_mat | G_por | absences_mat_groups | absences_por_groups |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id1 | GP | F | 18 | U | GT3 | A | 4 | 4 | at_home | teacher | course | mother | 2 | 2 | 0 | yes | no | no | no | yes | yes | no | no | 4 | 3 | 4 | 1 | 1 | 3 | 6 | 5 | 6 | 6 | no | 4 | 0 | 11 | 11 | 5.666667 | 7.333333 | middle | less |
| id2 | GP | F | 17 | U | GT3 | T | 1 | 1 | at_home | other | course | father | 1 | 2 | 0 | no | yes | no | no | no | yes | yes | no | 5 | 3 | 3 | 1 | 1 | 3 | 4 | 5 | 5 | 6 | no | 2 | 9 | 11 | 11 | 5.333333 | 10.333333 | less | less |
| id4 | GP | F | 15 | U | GT3 | T | 4 | 2 | health | services | home | mother | 1 | 3 | 0 | no | yes | yes | yes | yes | yes | yes | yes | 3 | 2 | 2 | 1 | 1 | 5 | 2 | 15 | 14 | 15 | no | 0 | 14 | 14 | 14 | 14.666667 | 14.000000 | less | less |
| id5 | GP | F | 16 | U | GT3 | T | 3 | 3 | other | other | home | father | 1 | 2 | 0 | no | yes | yes | no | yes | yes | no | no | 4 | 3 | 2 | 1 | 2 | 5 | 4 | 6 | 10 | 10 | no | 0 | 11 | 13 | 13 | 8.666667 | 12.333333 | less | less |
| id6 | GP | M | 16 | U | LE3 | T | 4 | 3 | services | other | reputation | mother | 1 | 2 | 0 | no | yes | yes | yes | yes | yes | yes | no | 5 | 4 | 2 | 1 | 2 | 5 | 10 | 15 | 15 | 15 | no | 6 | 12 | 12 | 13 | 15.000000 | 12.333333 | middle | middle |
| id7 | GP | M | 16 | U | LE3 | T | 2 | 2 | other | other | home | mother | 1 | 2 | 0 | no | no | no | no | yes | yes | yes | no | 4 | 4 | 4 | 1 | 1 | 3 | 0 | 12 | 12 | 11 | no | 0 | 13 | 12 | 13 | 11.666667 | 12.666667 | less | less |
| id8 | GP | F | 17 | U | GT3 | A | 4 | 4 | other | teacher | home | mother | 2 | 2 | 0 | yes | yes | no | no | yes | yes | no | no | 4 | 1 | 4 | 1 | 1 | 1 | 6 | 6 | 5 | 6 | no | 2 | 10 | 13 | 13 | 5.666667 | 12.000000 | middle | less |
| id9 | GP | M | 15 | U | LE3 | A | 3 | 2 | services | other | home | mother | 1 | 2 | 0 | no | yes | yes | no | yes | yes | yes | no | 4 | 2 | 2 | 1 | 1 | 1 | 0 | 16 | 18 | 19 | no | 0 | 15 | 16 | 17 | 17.666667 | 16.000000 | less | less |
| id10 | GP | M | 15 | U | GT3 | T | 3 | 4 | other | other | home | mother | 1 | 2 | 0 | no | yes | yes | yes | yes | yes | yes | no | 5 | 5 | 1 | 1 | 1 | 5 | 0 | 14 | 15 | 15 | no | 0 | 12 | 12 | 13 | 14.666667 | 12.333333 | less | less |
| id11 | GP | F | 15 | U | GT3 | T | 4 | 4 | teacher | health | reputation | mother | 1 | 2 | 0 | no | yes | yes | no | yes | yes | yes | no | 3 | 3 | 3 | 1 | 2 | 2 | 0 | 10 | 8 | 9 | no | 2 | 14 | 14 | 14 | 9.000000 | 14.000000 | less | less |
- Формулируем эмпирическю гипотезу. Уже обсуждали, что ЗП здесь –
G_mat, количественная непрерывная. НП –Mjob, категориальная номинативная, включает 5 уровней.
G_mat ~ Mjob
- Формулируем нулевую гипотезу:
\(H_0\): \(\mu_r = \mu_u\)
\(H_1\): \(\mu_r \neq \mu_u\)
Зафиксируем, что будем проверять гипотезу на уровне \(\alpha = 0.05\)
Выберем статистический критерий для проверки. Сделаем проверку ЗП на нормальность и сравним дисперсии двух выборок.
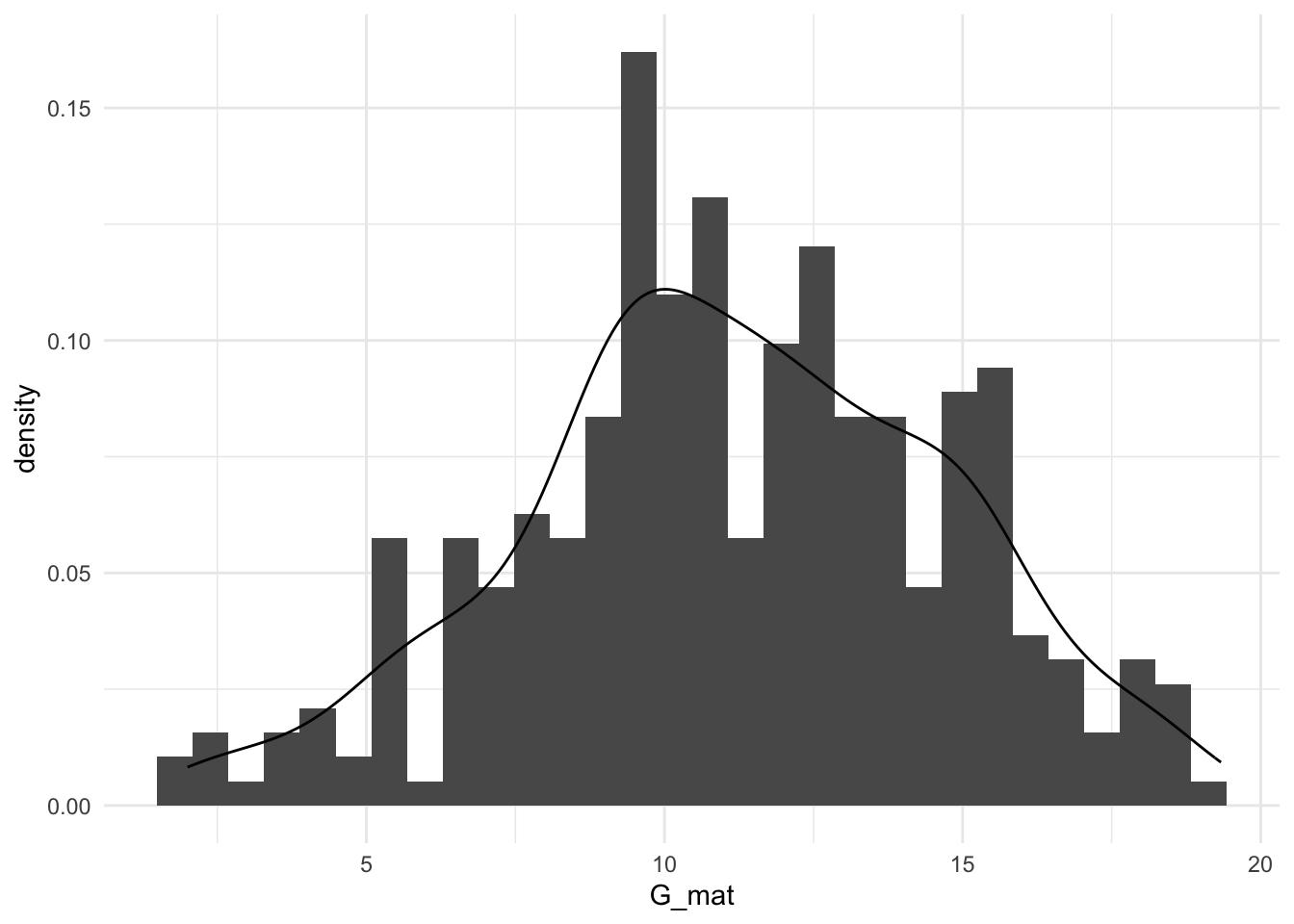
- В нашем случае критерий – однофакторный ANOVA с независимыми выборками. Вычислим его
library("ez")
model_abs_mat_ez <- ezANOVA(data = students, dv = G_mat, wid = student,
between = Mjob)
model_abs_mat_ez## $ANOVA
## Effect DFn DFd F p p<.05 ges
## 1 Mjob 4 315 4.132617 0.00280909 * 0.04986108
##
## $`Levene's Test for Homogeneity of Variance`
## DFn DFd SSn SSd F p p<.05
## 1 4 315 12.53941 1434.182 0.6885308 0.6003484- Как интпрерпретировать результаты? Ключевая для нас статистика – это F-значение
Еще хорошую и более поробную главу (даже две) про ANOVA написал мой друг и коллега Антон Ангельгардт, если интересно углубиться, можно почитать его материал. https://angelgardt.github.io/SFDA2022/book/oneway-anova.html
model_abs_mat_ez <- ezANOVA(data = students, dv = G_mat, wid = student,
between = Mjob)
model_abs_mat_ez## $ANOVA
## Effect DFn DFd F p p<.05 ges
## 1 Mjob 4 315 4.132617 0.00280909 * 0.04986108
##
## $`Levene's Test for Homogeneity of Variance`
## DFn DFd SSn SSd F p p<.05
## 1 4 315 12.53941 1434.182 0.6885308 0.6003484summary(model_abs_mat_ez)## Length Class Mode
## ANOVA 7 data.frame list
## Levene's Test for Homogeneity of Variance 7 data.frame list