12 Анализ категориальных данных
До этого мы все время работали с линейными моделями, где целевая (зависимая) переменная была количественной. И линейные регрессионные модели, и ANOVA модели относятся к общим линейным омделям (general linear models). Но что делать, если цеелвая переменнаая – категориальная? Уже нельзя строить линейные модели? Общие линейные – нет, а обобщенные – можно! Модели с категориальными предикторами включаются в обобщенные линейные модели generalized linear modela (не перепутайте…)
12.1 Логистическая регрессия
К логистической регрессии относится семейство моделей, где целевая переменная может принимать значения 1 или 0. То есть она принадлежит распределению Бернулли. Можно поизучать его на шайниапп, котрый сделал Антон Ангельгардт https://angelgardt.shinyapps.io/binomial_app/
Но если мы посмотрим на классическое уравнение регрессии, можем заметить проблему:
\(\hat y = b_0 + b_1 \times x_1\)
В левой части уравнения у нас стоят только значения \(\hat y={1;0}\), когда как в правой – множество непрерывных значений от минус бесконечности до бесконечности.
Чтобы ее решить, перейдем сначала к вероятностям: вместо значений 0 и 1 будем использовать вероятность для, например, 1.
\(p_1= b_0 + b_1 \times x_1\),
\(p_1 \in [0;1]\)
Уже лучше, но мы все еще остались в границах от 0 до 1. Чтобы все-таки превратить это уравнение в уже привычную нам линейную регрессию с количественной ЗП, сделаем логарифмическую трансформацию шансов – перейдем от вероятности к шансам для каждого исхода, 0 и 1, и посчитаем логарифм от них. Вероятность наступления исхода тогда станет обратной этому логарифму величиной.
\(odds_1 = \frac{p_1}{p_0} = \frac{p_1}{1 - p_1}\),
\(p_1 \in [0;1]\)
\(ln(odds_1) = logit(p_1) = ln(\frac{p_1}{1 - p_1}) = b_0 + b_1 \times x_1\),
\(p_1 = \frac{e^{b_0 + b_1 x}}{1 + e^{b_0 + b_1 x}}\),
\(ln(\frac{p_1}{1 - p_1}) \in (-\infty;\infty)\)
Здесь сильно упрощена математика, вслед за курсом Анатолия Карпова на степике не будем вдаваться в подробности. Здесь важно, что мы постарались применить одинаковое преобразование к обеим частям уравнения, поэтому вероятность теперь считается по функции с экспонентой (эта функция, к слову, очень важна в машинном обучении и называется сигма-функцией или сигмоидой из-за ее вида) – то есть, по определению логарифма, это показатель степени, в которую нужно возвести основание логарифма, чтобы получить данное число (\(ln(p_1) = b_0 + b_1 \times x_1\)).
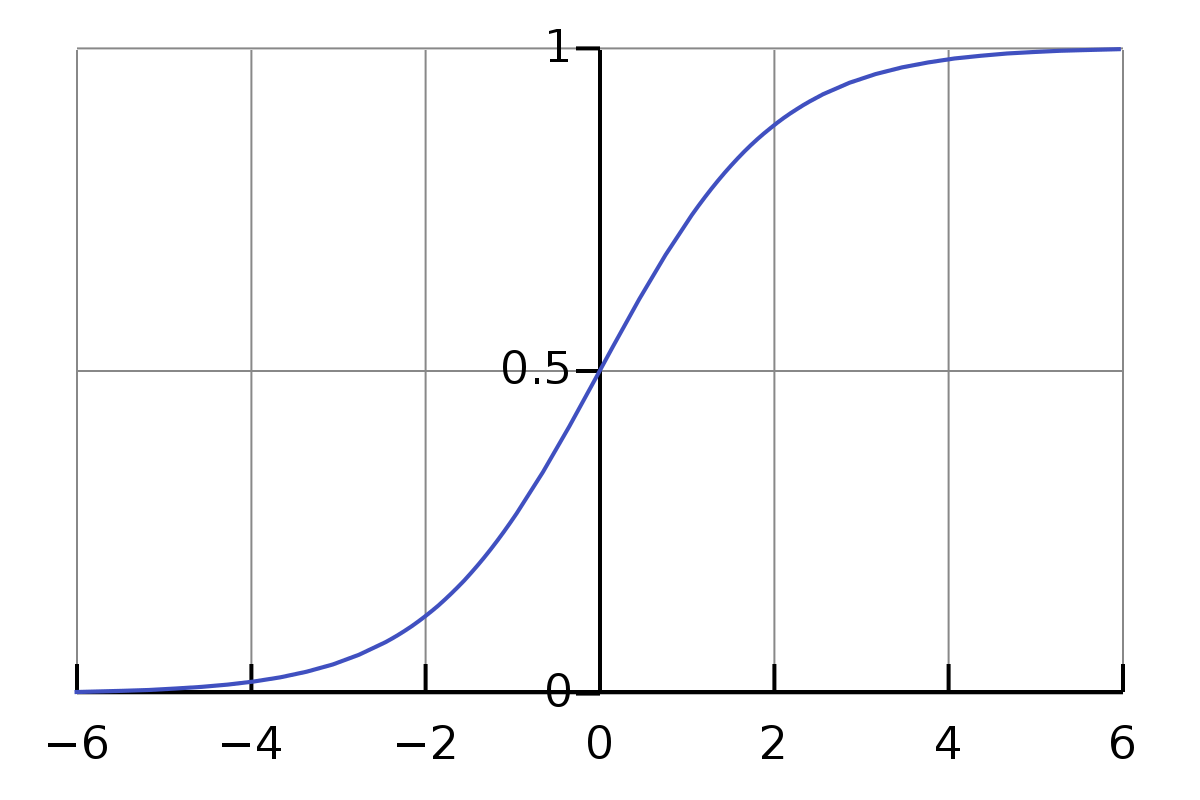
Сначала построим просто модель только с интерсептом, которая будет показывать, каковы шансы, что студент заплатит за курс на Udemy сами по себе, без учета каких-либо переменных – то есть, по сути, это тот же самый анализ, что и хи-квадрат – мы берем только частоты и строим на них модель.
! Важный момент! R считает за референс (первое значение, то, что будет в числителе) всегда наименьшее значение, то есть шансы будут считаться для 0, а не для 1. Если мы имеем дело с не числовыми значениями, то можем перезадать их с помощью функции relevel().
udemy_sample %>%
glm(is_paid ~1, ., family = binomial) ->logmodel1
summary(logmodel1)##
## Call:
## glm(formula = is_paid ~ 1, family = binomial, data = .)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## 2.409e-06 2.409e-06 2.409e-06 2.409e-06 2.409e-06
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 26.57 17055.25 0.002 0.999
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 0.0000e+00 on 435 degrees of freedom
## Residual deviance: 2.5295e-09 on 435 degrees of freedom
## AIC: 2
##
## Number of Fisher Scoring iterations: 25Интерсепт здесь получился равен 26.566069 – и есть натуральный логарифм шансов для оплаты. Посчитаем саму вероятность: \(p = \frac{exp^{26.56}}{1+exp^{26.56}}\)
Это число получилось равно 692204438686. То есть, шансы, что студенты НЕ заплят за курс (0) весьма высокие…
Теперь посчитаем, как влияет на оплату цена курса
udemy_sample %>%
glm(is_paid ~ price_log, ., family = binomial) ->logmodel2
summary(logmodel2)##
## Call:
## glm(formula = is_paid ~ price_log, family = binomial, data = .)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## 2.409e-06 2.409e-06 2.409e-06 2.409e-06 2.409e-06
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 2.657e+01 7.149e+04 0 1
## price_log -5.674e-08 1.821e+04 0 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 0.0000e+00 on 435 degrees of freedom
## Residual deviance: 2.5295e-09 on 434 degrees of freedom
## AIC: 4
##
## Number of Fisher Scoring iterations: 2512.2 Хи-квадрат
Хи-квадратом мы обычно проверяем коррялцию категориальных переменных между собой: порядковых, если у нас не шкала Лайерта или мало возможных значений, и метод корреляции Спирмена не подходит, или номинальных, где корреляцию Спирмена провести уже невозможно.
Например, давайте проверим гипотезу о том, что наличие или отсутствие интернета в квартире связано с наличием или отсутствием романтических отношений. Предположим, что португальские школьники, у кого дома есть интернет, реже вступают в романтические отношения, по сравнению с теми, у кого интернета нет. Для этого будем использовать метод хи-квадрат. НП – наличие или отсутствие интернета (переменная internet), ЗП – наличие или отсутствие романтических отношений (romantic).
chisq.test(students$internet, students$romantic, correct=FALSE)##
## Pearson's Chi-squared test
##
## data: students$internet and students$romantic
## X-squared = 3.9258, df = 1, p-value = 0.04755Сравниваем полученное p-value с выбранным уровнем α=0.05. p-value < α, значит, вероятность получить такую связь между переменными при условии, если на самом деле ее нет, меньше нашего допустимого уровня ложноположительных результатов, мы отвергаем нулевую гипотезу и делаем вывод о наличии корреляционной связи.
Хи-квадрат чаще всего визуализируют уже знакомым по корреляции Спирмена мозаичным графиком. Указываем НП как x=product(НП), и ЗП как fill = ЗП.
library(ggmosaic)
students %>%
ggplot(aes()) +
geom_mosaic(aes(x = product(internet), fill = romantic)) +
scale_fill_viridis(discrete=TRUE) +
theme_minimal()