5 Распределения
Что такое распределение? Мы постоянно употребляем это слово.
Говоря о распределениях, мы имеем в виду закон распределения случайной величины – соответствие между возможными значениями этой величины из области ее допустимых значений и: вероятностями этих значений – для дискретной величины, либо плотностью вероятности – для непрерывной величины.
5.1 Виды распределений
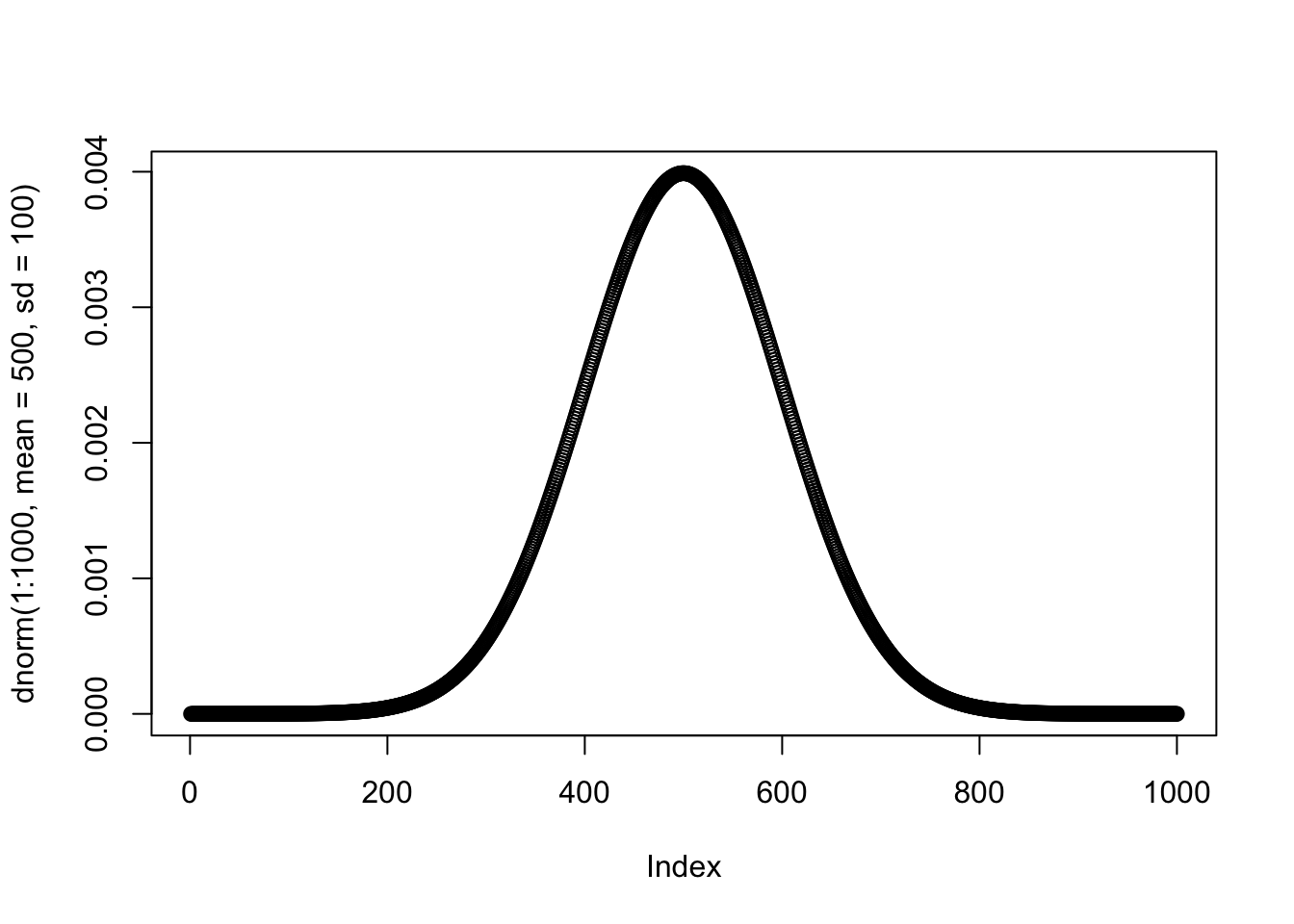
Законы распределений вероятностей можно вывести совсем не для всех величин! Но так сложилось, что некоторые закономерности, распределения вероятностей мы можем описать формулами, как в физике: сила тяжести (сила, с которой Земля притягивает все теля) прямо пропорциональная массе объекта, взятая с коэффициентом ускорения свободного падения \(F = m*g\). Мы это заметили относительно окружающего мира и вывели закон (не лично мы, а вообще представители планеты Земля). Точно так же и с распределниями: мы заметили, что вероятности распределения некоторых случайных величин подчиняются определенным законам, и записали их. Например, доказано, что непрерывные случайные величины, на которые действует множество случайных факторов (например, рост, вес и тд), распределяются в соответствии с распределением Гаусса, оно же – нормальное распределение. Его формула:
\(P(x) = \frac{e^{-(x - \mu)^{2}/(2\sigma^{2}) }} {\sigma\sqrt{2\pi}}\)
Или, например, экспоненциальное распределение:
\(P(x)= \lambda \times e^{-\lambda x}\)
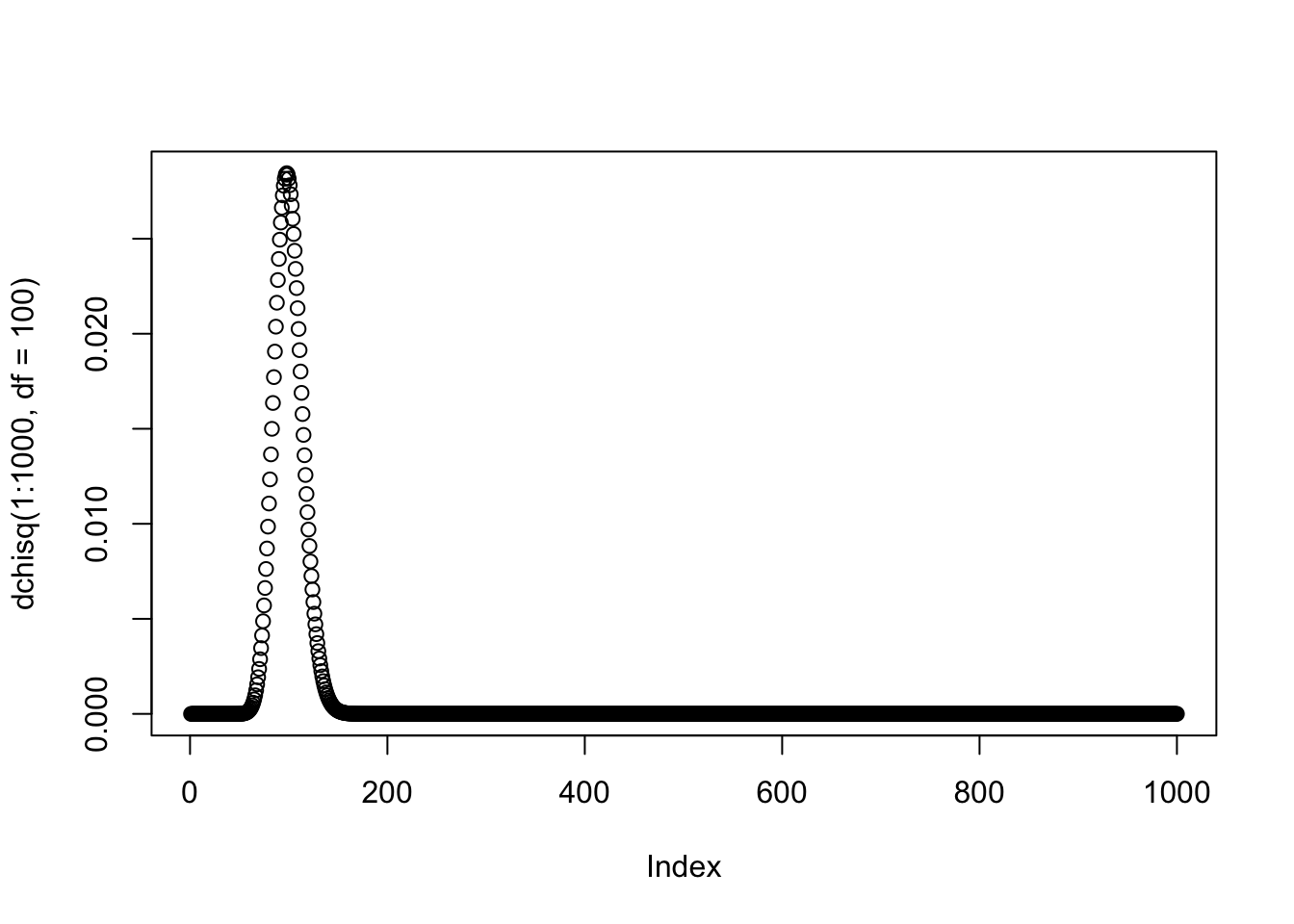
 χ2-распределение:
χ2-распределение:
\(P(x)= \lambda \times e^{-\lambda x}\)
Или, например, биномиальное распределение:
\(P(k | n, p) = \frac{n!}{k!(n-k)!} \times p^k \times (1-p)^{n-k} = {n \choose k} \times p^k \times (1-p)^{n-k}\)
 Посмотреть и ужаснуться можно тут http://www.math.wm.edu/~leemis/chart/UDR/UDR.html. Нам, к счастью, ничего из этого не понадобится.
Посмотреть и ужаснуться можно тут http://www.math.wm.edu/~leemis/chart/UDR/UDR.html. Нам, к счастью, ничего из этого не понадобится.
Менее пугающая версия https://www.johndcook.com/blog/distribution_chart/#normal
5.2 Функции распределения
Выше мы познакомились с плотностью вероятностью, зафиксируем все применимые к вероятности функции, которые бывают полезны:
- функция плотности вероятности (probability density function) для непрерывных СВ (например, рост, вес) и функция вероятности (probability mass function) для дискретных СВ (например, количество заболевших) – самая простая базовая функция, часто обозначается буквой
d* - функция накопленной вероятности / плотности вероятности (cumulative distribution function) для непреревных СВ, часто обозначается буквой
p* - квантильная функция (quantile function), она же обратная функция накопленной плотности распределения, об этом попозже, часто обозначается буквой
q*Функция плотности вероятности (cumulative distribution function; cdf)
Зачем они нужны?
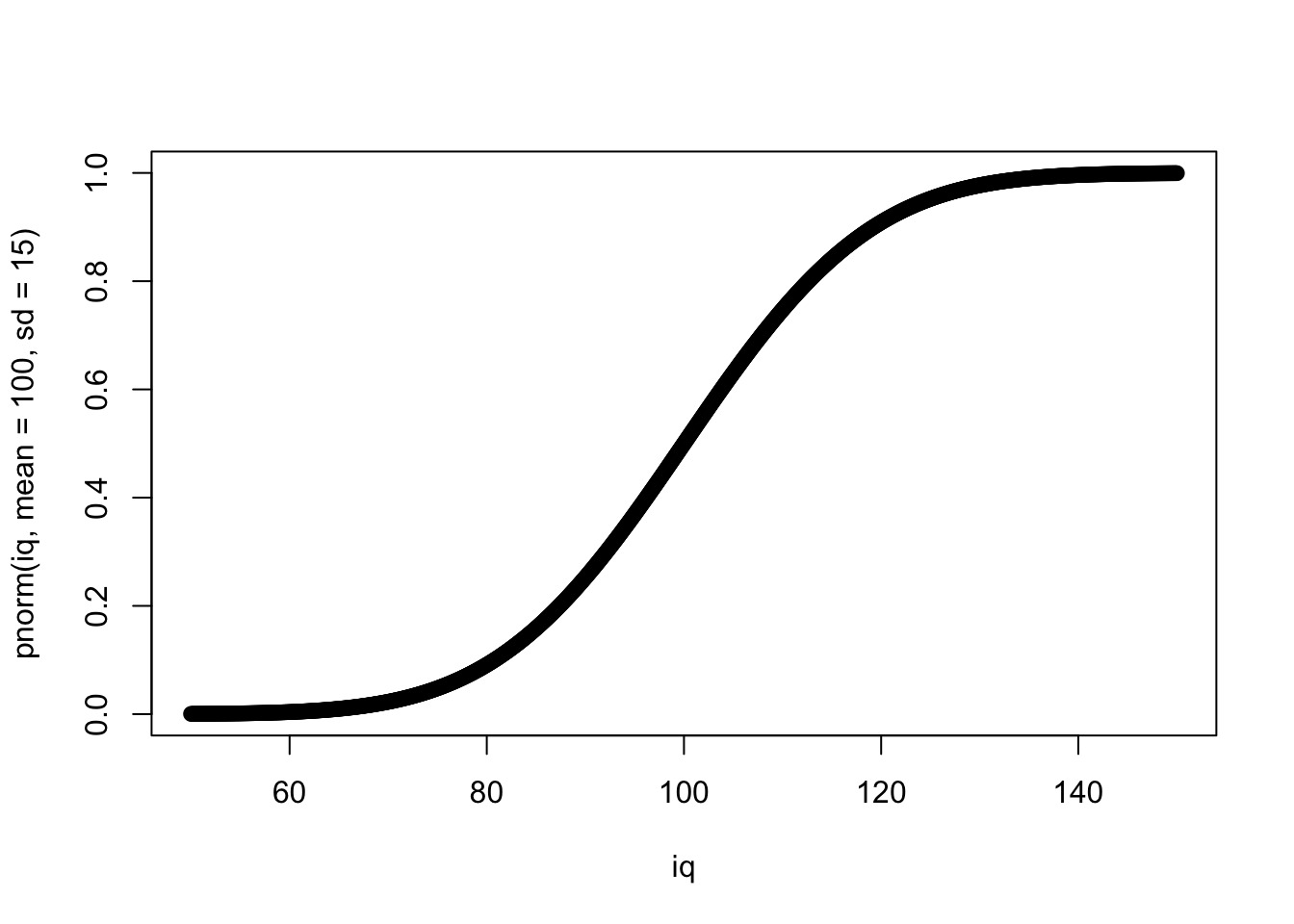
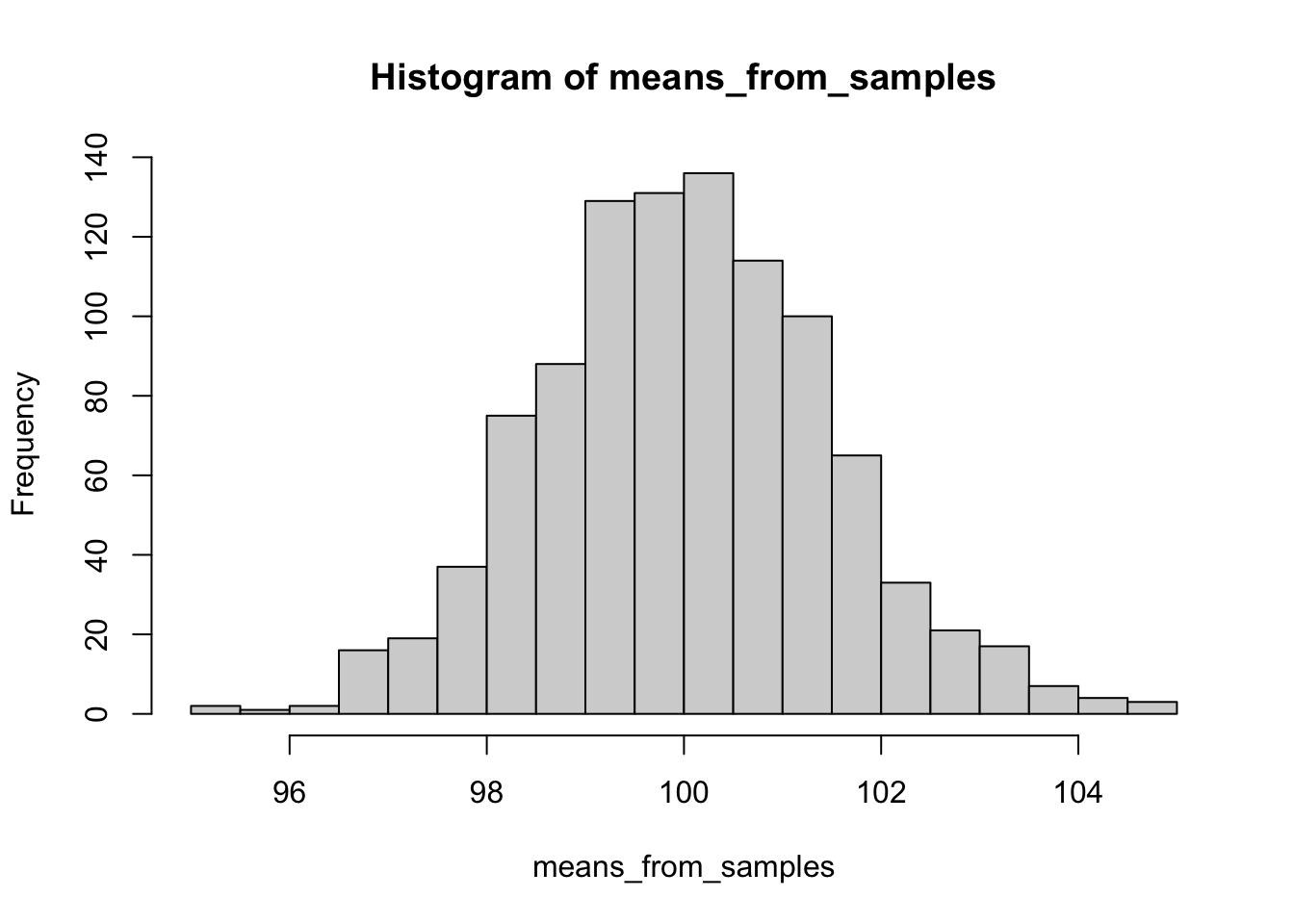
Разберемся на примере тестов на IQ.
Функция плотности вероятности (probability density function)
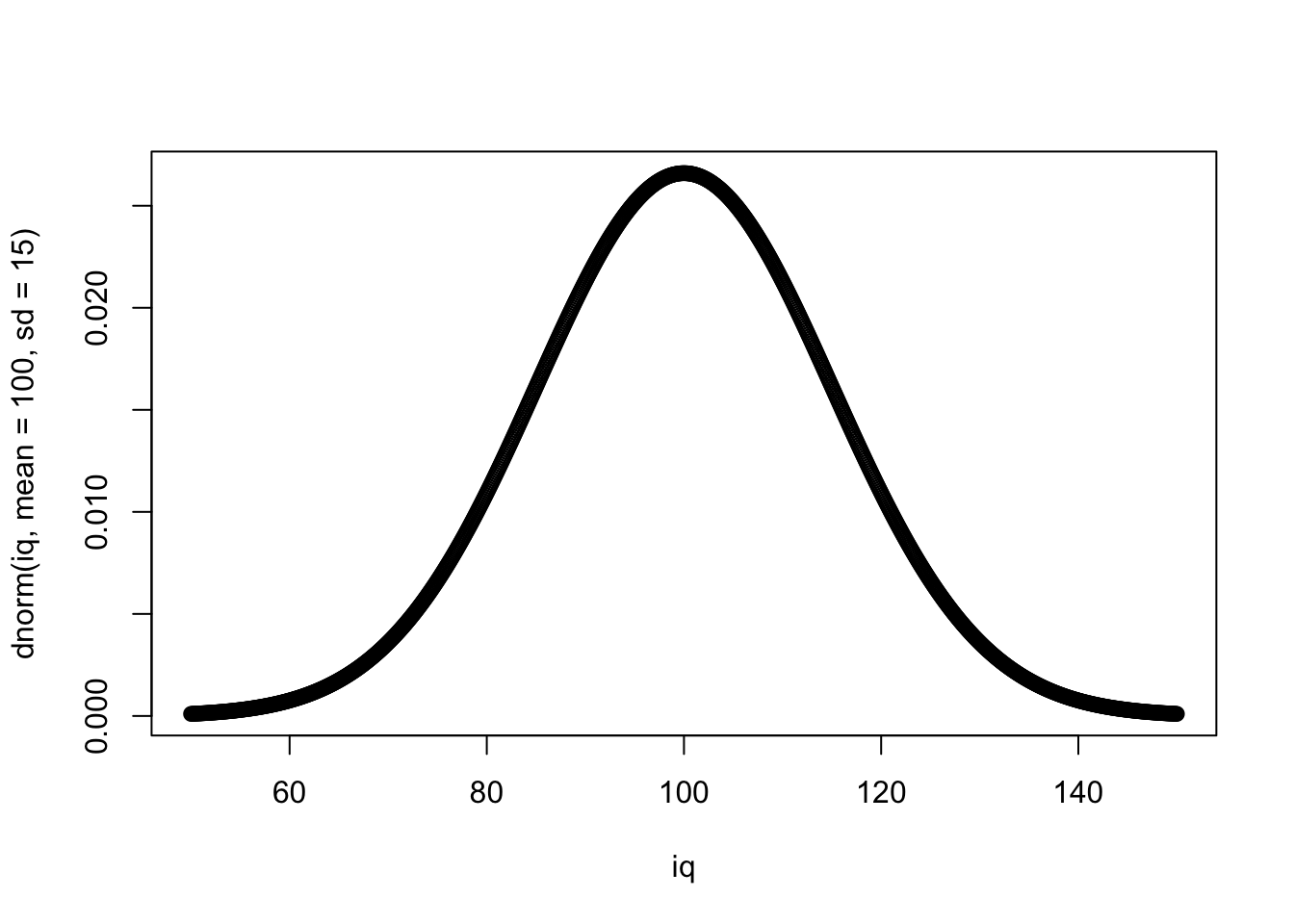
Функция накопленной плотности (cumulative distribution function; cdf)