14 Введение в анализ данных в R
Эта книжка написана с помощью языка программирования и обработки данных R и пакета Bookdown в среде работы с данными RStudio.
Чтобы начать в ней работать, нужно скачать и установить сам язык R https://cran.r-project.org/ и скачать и установить RStudio, среду для работы https://posit.co/downloads/.
14.1 Данные и переменные
Данные – это информация, представленная в форме, пригодной для хранения и обработки человеком или информационными системами (ISO/IEC/IEEE 24765-2010). Если данные представлены в форме для обработки информационными системами, они формализованы.
Переменная – это оболочка, которую мы задаем, чтобы хранить в ней данные и выполнять операции с ними. У переменной есть название и те данные, которая она хранит.
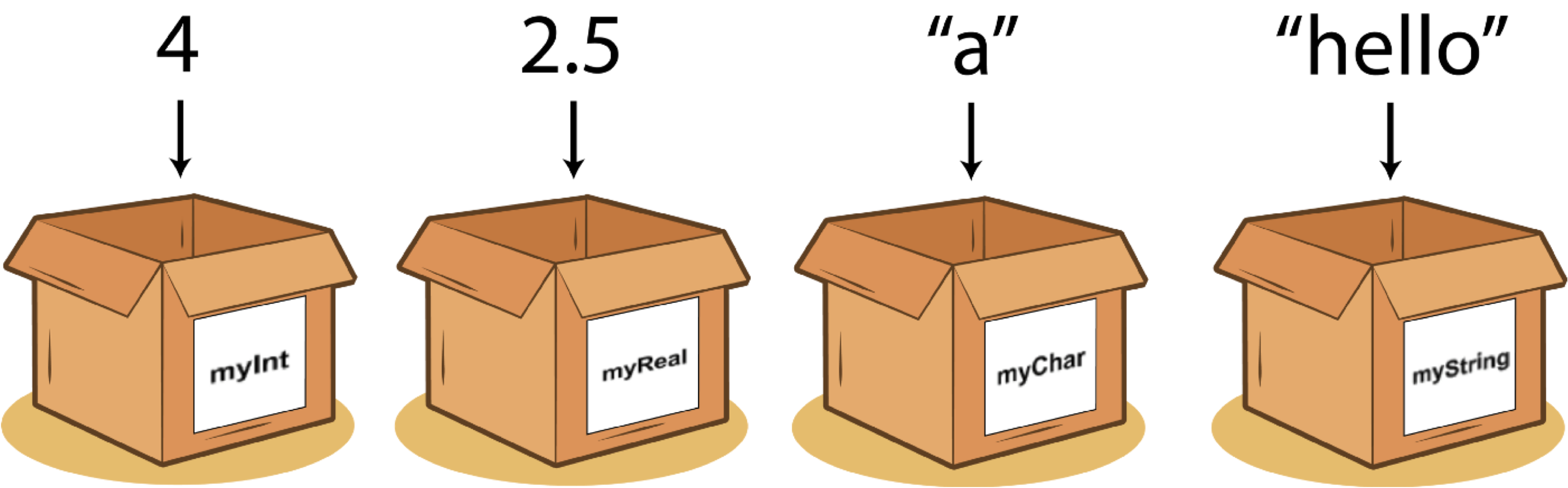
14.1.1 Основные типы данных
- Числовой (целые числа – integer или numeric, вещественные числа – real, числа с плавающей точкой (дробные) – float)
- Текстовый (character, если один символ, или string – много символов)
- Логический (logical или boolean – принимает только значения True / False)
- NA – пропущенные значения (not available)
- NaN – not a number, результат выполнения невозможной числовой операции (например, деление на 0)
14.1.2 Основные структуры данных
- Вектор (vector) – одномерный массив одного типа данных
- Массив (array) – многомерный массив одного типа данных, состоящий из векторов одной длины
- Матрица (matrix) – двумерный массив только числовых данных
- Список (list) – по сути, многомерный массив, но может состоять из векторов разной длины и иметь данные разных типв
- Данные, датафрейм (dataframe) – по сути, cписок, но все вектора одной длины
 https://practicum.yandex.ru/blog/10-osnovnyh-struktur-dannyh/
https://practicum.yandex.ru/blog/10-osnovnyh-struktur-dannyh/
14.2 Операции с переменными и функции
В зависимости от того, с переменными какого типа мы работаем, мы можем выполнять с ними разные операции.
Операция – это выполнение каких-либо действий над данными. То, что выполняет это действие, называется оператором или функцией. Разница между ними в том, что оператор выполняет атомарные (единичные и простые действия), например, оператором может быть знак сложения, деления, больше или меньше и тд. Функция делает более сложные действия: например, создать вектор с помощью функции c(), прочитать данные с помощью функции read_csv(), отфильтровать данные с помощью функции select(). Обратите внимание, что при вызове функции после ее названия всегда ставятся круглые скобки.
| Тип данных | Возможные атомарные операции |
|---|---|
| Числовой | = (присвоение), +, -, /, *, % |
| Текстовый | = (присвоение),+ (конкатенация), поиск по определенному символу |
| Логический | = (присвоение),>, <, == (равно), != (не равно) |
# создание векторов -------------------------------------------------------
c(1, 2, 3, 4, 5) # c() -- это функция, которая создает вектор, вне зависимости от типа данных## [1] 1 2 3 4 5# Числовые векторы -------------------------------------------------------
c(1, 2, 3, 4, 5, 7, 21, 143)## [1] 1 2 3 4 5 7 21 143vector1 <- c(1, 2, 3, 4, 5) # vector1 -- название переменной, 1, 2, 3, 4, 5 -- аргументы функции с()
age <- c(18, 22, 25, 20, 21)
1:10 # функция : создает числовой вектор от 1 до 10 только с шагом 1## [1] 1 2 3 4 5 6 7 8 9 10## [1] 10 9 8 7 6 5 4 3 2 1## [1] 2 4 6 8 10## [1] 1 3 5 7 9# Текстовые векторы -------------------------------------------------------
answers <- c("нет", "да", "да", "да", "нет")
#пример приведения типов -- TRUE и FALSE превратились в 1 и 0
c(1, 2, 3, 4, 5, TRUE, FALSE)## [1] 1 2 3 4 5 1 0## [1] "1" "2" "3" "4" "5" "1" "0"# Логические вектора и приведение типов ------------------------------------------------------
condition <- c(TRUE, FALSE, TRUE, TRUE, FALSE) #логический вектор
#примеры приведения типов, когда в векторе встречаются разные типы данных -- R приводит их к одному
c(1, 2, 3, 4, TRUE, FALSE)## [1] 1 2 3 4 1 0## [1] 1 2 3 4 5 6## [1] "1" "10" "3" "-4" "зеленый" "карий"## [1] FALSE## [1] FALSE## [1] FALSE## [1] TRUE## [1] TRUE## [1] TRUE#функция, которая выполняет действия в зависимости от условия ...если ... то:
# ifelse() содержит 3 аргумента: ( условие; что делать, если условие верно;
# что делать, если условие ложно)
ifelse(a < b, a+b, "а не меньше b")## [1] 15# датафрейм ---------------------------------------------------------------
eye_color <- c("green", "brown", "grey", "blue", "red")
data <- data.frame(vector1, age, answers, condition, eye_color) #функция data.frame() создает датафрейм (табличку с данными) из существующих векторов
View(data) # функция View() открвает эту табличку в отдельной вкладке (то же, что и по клику иконки в окне Environment)
data$age # отбираем колонку из датафрейма: название_датафрейма$название_колонки## [1] 18 22 25 20 21# описательные визуализации
hist(data$age, breaks = c(18, 22, 27))
lines(density(data$age)) #добавляет график плотности вероятности на гистограмму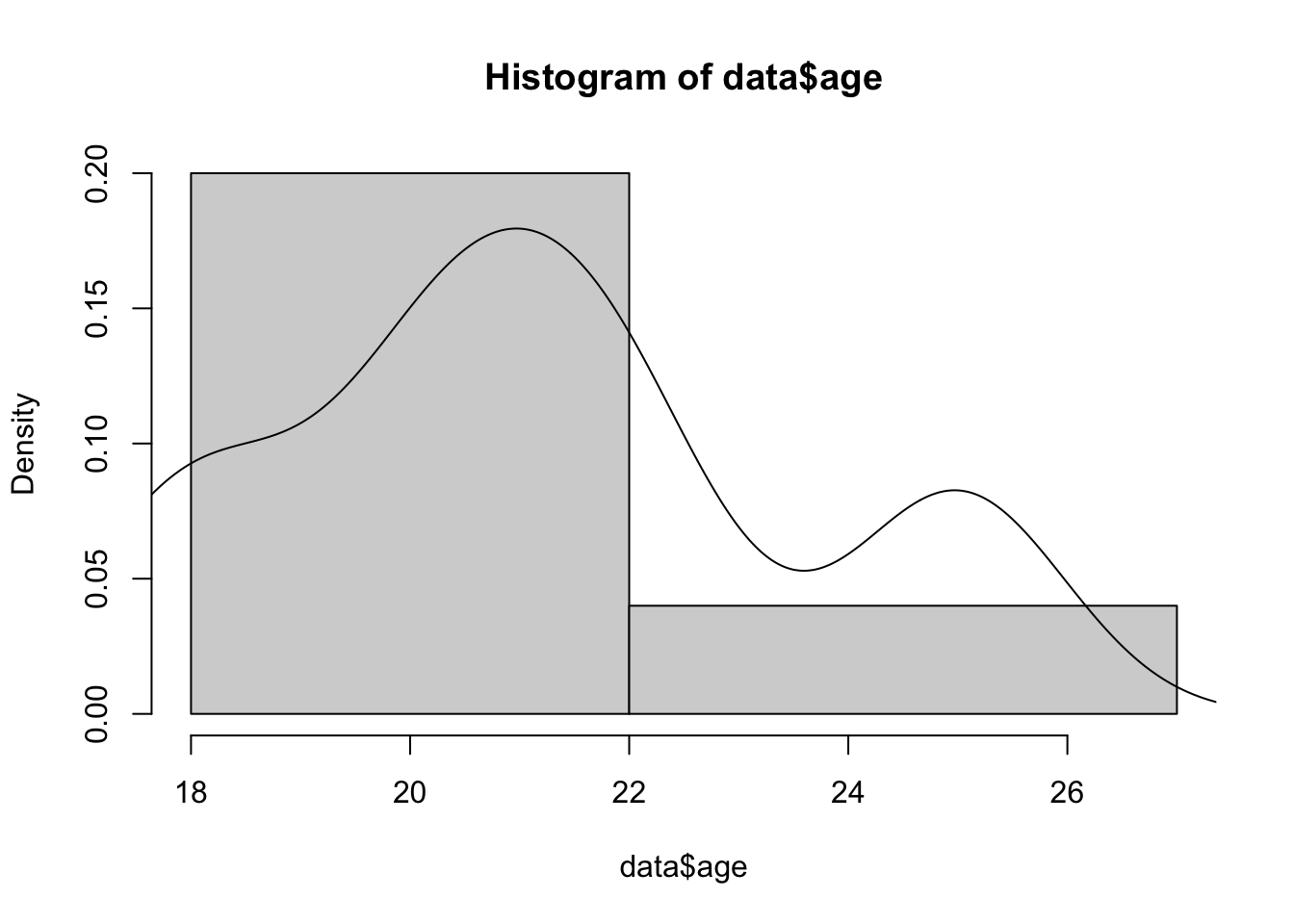
## [1] 21.2## [1] 2.588436## [1] 2.6## [1] 18## [1] 25## [1] 18 25## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 18.0 20.0 21.0 21.2 22.0 25.014.3 Начало работы в среде
В этом учебнике я буду приводить задания для тренировки в любой среде работы с данными и код работы с данными в R.
Для большинства интересных операций в R нам понадобятся дополнительные пакеты – набор функций, которые уже кто-то написал за нас (то же самое, как, например, import numpy as np в питоне). Нам в основном понадобится пакет tidyverse, дословно – “вселенная чистых данных`. Сразу скажу, что все помеченной символом # – это комментарии, наши подсказки, которые не будут исполняться. Их важно всего оставлять для себя, чтобы не забыть, что вообще здесь происходит.
Чтобы пакет заработал, его нужно 1. установить и 2. подключить
Установить пакет достаточно всего один раз после установки R, подключать через library нужно всегда, когда открываем RStudio. Ошибка вида “could not find function” в 99% случаев говорит о том, что пакет, из которого она используется, не подключен.
14.4 Начало работы с данными
Мы будем работать с данными World Happiness Report за 2016 год https://www.kaggle.com/datasets/unsdsn/world-happiness. Это Всемирный доклад о счастье https://en.wikipedia.org/wiki/World_Happiness_Report , которой показывает, как жители разных стран оценивают свой уровень счастья. Их можно скачать так же по ссылке https://raw.githubusercontent.com/elenary/StatsForDA/main/2016.csv (правой кнопкой мыши в открывшемся файле - Сохранить как). В данных за 2016 год, с которыми мы будем работать, участвую 157 стран. Кстати, вы можете скачать данные за разные года и посмотреть, как менялось количество стран-участниц? Чуть позже мы научимся делать это с помощью кода. Здесь есть следующие переменные:
- Happiness Rank - позиция в рейтинге
- Happiness Score - абсолютное значение, набранное по уровню счастья
- SE - стандартная ошибка
- Economy - ВВП на душу населения
- Family - Социальная поддержка, ощущение семье
- Health - Продолжительность жизни
- Freedom - Свободы
- Trust (Goverment Corruption) - воспринимаемый уровень коррупции
- Generosity - сколько жертвуют на благотворительность
- Dystopia - страна-антиутопия, где самые низкие показатели по всем парметрам из существующих
Economy, Family, Health, Freedom, Trust, Generosity – 6 показателей, по которым считается уровень счастья.
Чтобы совершать операции с данными, их сначала нужно прочитать, загрузить в среду работы с данными. В современных традициях R это проще всего сделать с помощью функции read_csv() из пакета tidyverse. Не забывайте, что любой вызов функции сопровождается круглыми скобками, в которые передаются аргументы. В функции read_csv()в скобках нужно передать путь к файлу, который мы хотим прочитать.Его можно скопировать через свойства файла. Но чтобы не заморачиваться с путем, проще всего положить файл с данными в ту же папку, где и лежит наш сам файл с кодом (для этого его нужно сохранить). А самое элегентное и используемое решение – создать проект File - New Project, и хранить все файл в папке проекта, это уберагает от большого числа ошибок. Про импорт файлов очень подробно расписано у Ивана Позднякова https://pozdniakov.github.io/tidy_stats/030-import_data.html
whr <- read_csv("2016.csv") # читаем данные
View(whr) # просматриваем, что получилось передать в объект с названием whr Теперь я хочу поизучать эти данные. Помните, с чего мы начинаем изучение данных? С описательных статистик
Я могу отобрать все переменные по одной и посчитать для них среднее и стандартное отклонение – это то, что в Jamovi находится во вкладке Descriptives. Так как колонка существует не в вакууме, а внутри датасета, то нам необходимо как-то указать, что нас интересует конкретная колонка внутри конкретного датасета. Пока что проще всего это сделать – с помощью значка $:
## [1] 1.16374 1.14524 1.18326 1.12690 1.13464 1.09610 1.02912 1.17278 1.10476
## [10] 1.08764 0.99537 1.08383 1.04782 1.02152 1.08113 1.09774 1.03938 1.05249
## [19] 1.16157 1.03999 0.71460 0.86758 1.08672 0.90587 0.98912 1.06612 1.00793
## [28] 0.87114 1.03143 1.09879 1.02169 1.00508 1.04477 0.84829 0.92624 0.87964
## [37] 1.12945 0.83309 0.87119 0.77866 0.87758 0.94397 0.98569 1.03302 1.08268
## [46] 0.80975 0.88025 0.89521 1.16810 1.04167 0.85974 0.68655 1.06054 0.95544
## [55] 0.83132 1.05261 1.04685 0.72194 0.83779 1.06411 1.04993 0.81826 1.05613
## [64] 0.81255 1.03817 0.75695 0.95076 0.95025 0.70697 1.11111 0.72803 1.05163
## [73] 0.96372 0.60809 0.87021 0.33613 0.66062 0.87717 0.87625 0.86216 0.76042
## [82] 0.87877 0.79381 0.90836 0.95434 0.81329 0.64367 0.74173 0.99496 0.38595
## [91] 0.93164 0.26135 0.64184 0.94367 0.78236 0.79117 0.75862 0.43165 0.75473
## [100] 0.75602 1.08983 0.54970 0.64498 0.75596 0.38857 0.63760 0.69699 0.71629
## [109] 0.50163 0.24749 0.62800 0.59205 0.70362 0.62542 0.37932 0.96053 0.84783
## [118] 0.29247 0.69981 0.49813 0.62477 0.76240 1.01413 0.49353 0.80676 0.19249
## [127] 0.47799 0.77416 0.92542 0.84142 0.71478 0.14700 0.81928 0.72368 0.86333
## [136] 0.29561 0.89186 0.60323 0.57576 0.53750 0.66366 0.60530 0.18519 0.63178
## [145] 0.63054 0.90981 0.47493 0.46115 0.77623 0.50353 0.31090 0.61586 0.10419
## [154] 0.11037 0.00000 0.14866 0.23442Или можем вспомнить, что датафрейм имеет два измерения, как и двумерный массив, и можем обратиться по индексу (в квадртных скобках): номер строки (первое число) и номер колонки (второе число). Если нас интересует не конкретная строка, а все строки, то на месте этого индекс ничего не ставится, как бы пропускаем его.
## # A tibble: 157 × 1
## Family
## <dbl>
## 1 1.16
## 2 1.15
## 3 1.18
## 4 1.13
## 5 1.13
## 6 1.10
## 7 1.03
## 8 1.17
## 9 1.10
## 10 1.09
## # ℹ 147 more rowsОбратите внимание на выдачу: как вы думаете, какым структурам данных принадлежат результаты первого и второго способа?
Посчитаем среднее и стандартное отклонение для этой колонки
## [1] 0.7936211## [1] 0.266705714.5 Задания после семинара 2
- Прочитайте в среде, в которой вы работаете, данные WHR за 2016 год (в R – используйте функцию
read_csv()из пакетаtidyverse). - Посчитайте среднее, стандартное отклонение, медиану и размах (разброс от максимального до минимального значения) по всем 6 показателям, составляющим уровень счастья (Economy, Family, Health, Freedom, Trust, Generosity). Что можно сказать про них? Где самый большой размах? Где среднее и медиана оказались близко друг к другу, а где не очень? (для подсчета медианы и размаха в R нужно будет немножко поучиться гуглить или использовать другие материалы)
- Постройте гистограмму и график плотности вероятности для всех 6 показателей, составляющим уровень счастья.
14.6 Предобработка данных
После того, как мы считали данные данные в переменную (мы использовали функцию read_csv() для этого), часто нужно эти данные сначала предобработать. Во-первых, данные сами по себе могут быть не очень хорошего качества, и их нужно почистить. Во-вторых, мы никогда не работаем со всей табличкй сразу – мы отбираем данные, например, определенную колонку, и часто нам нужны не все данные, а только соответствующие определенным условиям (например, нам нужно отобрать время реакции в группе, где испытуемые употребляли кофеин, а не плацебо).
В предобработку данных чаще всего входит:
- Отбор определенных колонок
- Фильтрация – отбор определенных строк, удовлетворяющих определенным условиям
- Создание новых колонок и заполнение их в соответствии с определенными услвиями
- Работа с пропущенными значениями – удаление или замена на какое-либо (например, среднее) значение
Пойдем по порядку.
14.6.1 Отбор колонок
Любое почти всегда можно сделать разными способами. Чаще всего не существует правильного, если работает – значит, правильно. Но некоторые решения бывает более оптимальными в разных контекстах. Рассмотрим разные способы отбора колонок. Обратите внимание, чем они различаются?
Сразу комментарий – когда мы делаем операцию присвоения <-, у нас ничего не выводится в консоль. Чтобы посмотреть, что мы присвоили переменной, можно вывести ее по названию или, если речь про данные – посмотреть с помощью функции View(). Если вы только пробуете написать операцию – не спешите присваивать ее в переменную! Так мы сразу будем видеть результат в консоли, и если он ошибочный, это будет понятно.
Отбор в базовом R по названию колонки
## [1] 7.526 7.509 7.501 7.498 7.413 7.404 7.339 7.334 7.313 7.291 7.267 7.119
## [13] 7.104 7.087 7.039 6.994 6.952 6.929 6.907 6.871 6.778 6.739 6.725 6.705
## [25] 6.701 6.650 6.596 6.573 6.545 6.488 6.481 6.478 6.474 6.379 6.379 6.375
## [37] 6.361 6.355 6.324 6.269 6.239 6.218 6.168 6.084 6.078 6.068 6.005 5.992
## [49] 5.987 5.977 5.976 5.956 5.921 5.919 5.897 5.856 5.835 5.835 5.822 5.813
## [61] 5.802 5.771 5.768 5.743 5.658 5.648 5.615 5.560 5.546 5.538 5.528 5.517
## [73] 5.510 5.488 5.458 5.440 5.401 5.389 5.314 5.303 5.291 5.279 5.245 5.196
## [85] 5.185 5.177 5.163 5.161 5.155 5.151 5.145 5.132 5.129 5.123 5.121 5.061
## [97] 5.057 5.045 5.033 4.996 4.907 4.876 4.875 4.871 4.813 4.795 4.793 4.754
## [109] 4.655 4.643 4.635 4.575 4.574 4.513 4.508 4.459 4.415 4.404 4.395 4.362
## [121] 4.360 4.356 4.324 4.276 4.272 4.252 4.236 4.219 4.217 4.201 4.193 4.156
## [133] 4.139 4.121 4.073 4.028 3.974 3.956 3.916 3.907 3.866 3.856 3.832 3.763
## [145] 3.739 3.739 3.724 3.695 3.666 3.622 3.607 3.515 3.484 3.360 3.303 3.069
## [157] 2.905## num [1:157] 7.53 7.51 7.5 7.5 7.41 ...Отбор в базовом R по индексу
Индекс – это номер элемента в структуре данных. Мы говорили про них, когда обсуждали многомерные массивы: в одномерной структуре, например, векторе, индекс будет состоять из одного числа, в двумернй (например, матрице или датафрейме) – индекс состоит из двух чисел, разделенных запятой, в трехмерной – из трех, и так далее. Индекс в R всегда пишется в квадратных скобках, например, чтобы узнать, что находится во второй строчке третьего столбца, индекс элемента будет [2,3].
Сначала идет номер строки, затем – номер столбца. Если мы хотим вывести все строки или все столбцы – на месте этого индекса ничего не ставится. Например, если я хочу вывести все строки из третьей колонки, я напишу [,3]
## # A tibble: 157 × 1
## `Happiness Score`
## <dbl>
## 1 7.53
## 2 7.51
## 3 7.50
## 4 7.50
## 5 7.41
## 6 7.40
## 7 7.34
## 8 7.33
## 9 7.31
## 10 7.29
## # ℹ 147 more rows## tibble [157 × 1] (S3: tbl_df/tbl/data.frame)
## $ Happiness Score: num [1:157] 7.53 7.51 7.5 7.5 7.41 ...Отбор с помощью пакета tidyverse по названию
Сначала пара важных моментов отнсосительно работы с пакетом и кульурой написания кода tidyverse. Последовательность операций в рамках одной задачи пишется построчно с переносом на следующую строку в виде пайпа %>% – символа, который позволяет испльзовать в качестве аргумента функции следующей строки то, что получилось в результате выполнения предыдущей. На первой строке в пайп передаются сами данные, то есть название переменной, в которую мы их записали. Далее на каждой следующей строке в качестве первого аргумента функции в скобках будет применяться результат выполнения предыдущей. Подробнее про tidyverse https://pozdniakov.github.io/tidy_stats/110-tidyverse_basic.html и про пайпы https://pozdniakov.github.io/tidy_stats/110-tidyverse_basic.html
Внутри tidyverse используется такая структура данных, как tibble(https://tibble.tidyverse.org/). Тиббл – это модицифированный датафрейм, о чем мы уже говорили, когда обсуждали структуры данных
Вывод в датафрейм (тиббл):
## # A tibble: 157 × 1
## `Happiness Score`
## <dbl>
## 1 7.53
## 2 7.51
## 3 7.50
## 4 7.50
## 5 7.41
## 6 7.40
## 7 7.34
## 8 7.33
## 9 7.31
## 10 7.29
## # ℹ 147 more rows## tibble [157 × 1] (S3: tbl_df/tbl/data.frame)
## $ Happiness Score: num [1:157] 7.53 7.51 7.5 7.5 7.41 ...С помощью функции select() мы можем вытаскивать даже не одну колонку, а несколько:
## # A tibble: 157 × 2
## Country `Happiness Score`
## <chr> <dbl>
## 1 Denmark 7.53
## 2 Switzerland 7.51
## 3 Iceland 7.50
## 4 Norway 7.50
## 5 Finland 7.41
## 6 Canada 7.40
## 7 Netherlands 7.34
## 8 New Zealand 7.33
## 9 Australia 7.31
## 10 Sweden 7.29
## # ℹ 147 more rowsОтбор с помощью пакета tidyverse по названию
Обратите внимание – предыдущий вывод так же является тибблом, а не вектором. Чтобы вывести в вектор, надо выполнить еще один шаг с помощью функции pull(), которая как бы “вытягивает” значения из тиббла:
var4 <- whr %>%
select(`Happiness Score`) %>%
pull() #вытягивает числовые значения и превращает в числовой вектор
var4## [1] 7.526 7.509 7.501 7.498 7.413 7.404 7.339 7.334 7.313 7.291 7.267 7.119
## [13] 7.104 7.087 7.039 6.994 6.952 6.929 6.907 6.871 6.778 6.739 6.725 6.705
## [25] 6.701 6.650 6.596 6.573 6.545 6.488 6.481 6.478 6.474 6.379 6.379 6.375
## [37] 6.361 6.355 6.324 6.269 6.239 6.218 6.168 6.084 6.078 6.068 6.005 5.992
## [49] 5.987 5.977 5.976 5.956 5.921 5.919 5.897 5.856 5.835 5.835 5.822 5.813
## [61] 5.802 5.771 5.768 5.743 5.658 5.648 5.615 5.560 5.546 5.538 5.528 5.517
## [73] 5.510 5.488 5.458 5.440 5.401 5.389 5.314 5.303 5.291 5.279 5.245 5.196
## [85] 5.185 5.177 5.163 5.161 5.155 5.151 5.145 5.132 5.129 5.123 5.121 5.061
## [97] 5.057 5.045 5.033 4.996 4.907 4.876 4.875 4.871 4.813 4.795 4.793 4.754
## [109] 4.655 4.643 4.635 4.575 4.574 4.513 4.508 4.459 4.415 4.404 4.395 4.362
## [121] 4.360 4.356 4.324 4.276 4.272 4.252 4.236 4.219 4.217 4.201 4.193 4.156
## [133] 4.139 4.121 4.073 4.028 3.974 3.956 3.916 3.907 3.866 3.856 3.832 3.763
## [145] 3.739 3.739 3.724 3.695 3.666 3.622 3.607 3.515 3.484 3.360 3.303 3.069
## [157] 2.905## num [1:157] 7.53 7.51 7.5 7.5 7.41 ...В этом случае мы можем даже в этом же пайпе посчитать медиану или среднее:
## [1] 5.314А так будет ошибка
14.6.2 Фильтрация (отбор строк)
Очень часто встает задача фильтрации строк: когда нужны не все данные, а удовлетворяющие какому-либо условию
## # A tibble: 10 × 13
## Country Region `Happiness Rank` `Happiness Score` Lower Confidence Int…¹
## <chr> <chr> <dbl> <dbl> <dbl>
## 1 Denmark Wester… 1 7.53 7.46
## 2 Switzerland Wester… 2 7.51 7.43
## 3 Iceland Wester… 3 7.50 7.33
## 4 Norway Wester… 4 7.50 7.42
## 5 Finland Wester… 5 7.41 7.35
## 6 Canada North … 6 7.40 7.34
## 7 Netherlands Wester… 7 7.34 7.28
## 8 New Zealand Austra… 8 7.33 7.26
## 9 Australia Austra… 9 7.31 7.24
## 10 Sweden Wester… 10 7.29 7.23
## # ℹ abbreviated name: ¹`Lower Confidence Interval`
## # ℹ 8 more variables: `Upper Confidence Interval` <dbl>,
## # `Economy (GDP per Capita)` <dbl>, Family <dbl>,
## # `Health (Life Expectancy)` <dbl>, Freedom <dbl>,
## # `Trust (Government Corruption)` <dbl>, Generosity <dbl>,
## # `Dystopia Residual` <dbl>## # A tibble: 10 × 13
## Country Region `Happiness Rank` `Happiness Score` Lower Confidence Int…¹
## <chr> <chr> <dbl> <dbl> <dbl>
## 1 Denmark Wester… 1 7.53 7.46
## 2 Switzerland Wester… 2 7.51 7.43
## 3 Iceland Wester… 3 7.50 7.33
## 4 Norway Wester… 4 7.50 7.42
## 5 Finland Wester… 5 7.41 7.35
## 6 Canada North … 6 7.40 7.34
## 7 Netherlands Wester… 7 7.34 7.28
## 8 New Zealand Austra… 8 7.33 7.26
## 9 Australia Austra… 9 7.31 7.24
## 10 Sweden Wester… 10 7.29 7.23
## # ℹ abbreviated name: ¹`Lower Confidence Interval`
## # ℹ 8 more variables: `Upper Confidence Interval` <dbl>,
## # `Economy (GDP per Capita)` <dbl>, Family <dbl>,
## # `Health (Life Expectancy)` <dbl>, Freedom <dbl>,
## # `Trust (Government Corruption)` <dbl>, Generosity <dbl>,
## # `Dystopia Residual` <dbl>## # A tibble: 29 × 13
## Country Region `Happiness Rank` `Happiness Score` Lower Confidence Int…¹
## <chr> <chr> <dbl> <dbl> <dbl>
## 1 Czech Repub… Centr… 27 6.60 6.52
## 2 Slovakia Centr… 45 6.08 6.00
## 3 Uzbekistan Centr… 49 5.99 5.90
## 4 Kazakhstan Centr… 54 5.92 5.84
## 5 Moldova Centr… 55 5.90 5.82
## 6 Russia Centr… 56 5.86 5.79
## 7 Poland Centr… 57 5.84 5.75
## 8 Lithuania Centr… 60 5.81 5.73
## 9 Belarus Centr… 61 5.80 5.72
## 10 Slovenia Centr… 63 5.77 5.68
## # ℹ 19 more rows
## # ℹ abbreviated name: ¹`Lower Confidence Interval`
## # ℹ 8 more variables: `Upper Confidence Interval` <dbl>,
## # `Economy (GDP per Capita)` <dbl>, Family <dbl>,
## # `Health (Life Expectancy)` <dbl>, Freedom <dbl>,
## # `Trust (Government Corruption)` <dbl>, Generosity <dbl>,
## # `Dystopia Residual` <dbl>А теперь отфильтруем эти значения и возьмем только те значения Happiness Score, которые соответствуют Центральной и восточной Европе
## # A tibble: 29 × 1
## `Happiness Score`
## <dbl>
## 1 6.60
## 2 6.08
## 3 5.99
## 4 5.92
## 5 5.90
## 6 5.86
## 7 5.84
## 8 5.81
## 9 5.80
## 10 5.77
## # ℹ 19 more rows.. и “вытащим” эти значения в числовой вектор, чтобы с ними было проще всего работать
## [1] 6.596 6.078 5.987 5.919 5.897 5.856 5.835 5.813 5.802 5.768 5.658 5.560
## [13] 5.528 5.517 5.488 5.401 5.291 5.185 5.177 5.163 5.161 5.145 5.121 4.996
## [25] 4.655 4.360 4.324 4.252 4.217И посчитаем среднее
whr %>%
filter(Region == "Central and Eastern Europe") %>%
select(`Happiness Score`) %>%
pull() %>%
mean()## [1] 5.37069Теперь можем сравнить средний Happiness Score по всем странам (считали его ранее) и только по Центральной и восточной Европе. Что можно про них сказать?
Или посмотрим, какие страны находятся в топе-10 по Happiness Rank
## # A tibble: 10 × 13
## Country Region `Happiness Rank` `Happiness Score` Lower Confidence Int…¹
## <chr> <chr> <dbl> <dbl> <dbl>
## 1 Denmark Wester… 1 7.53 7.46
## 2 Switzerland Wester… 2 7.51 7.43
## 3 Iceland Wester… 3 7.50 7.33
## 4 Norway Wester… 4 7.50 7.42
## 5 Finland Wester… 5 7.41 7.35
## 6 Canada North … 6 7.40 7.34
## 7 Netherlands Wester… 7 7.34 7.28
## 8 New Zealand Austra… 8 7.33 7.26
## 9 Australia Austra… 9 7.31 7.24
## 10 Sweden Wester… 10 7.29 7.23
## # ℹ abbreviated name: ¹`Lower Confidence Interval`
## # ℹ 8 more variables: `Upper Confidence Interval` <dbl>,
## # `Economy (GDP per Capita)` <dbl>, Family <dbl>,
## # `Health (Life Expectancy)` <dbl>, Freedom <dbl>,
## # `Trust (Government Corruption)` <dbl>, Generosity <dbl>,
## # `Dystopia Residual` <dbl>Если нам нужно выполнить несколько условий одновременно (например, странны с Happiness Score не менее 10, но более 7), то мы можем пользоваться логическим “и” и логическим “или” (разница между ними в том, что “и” отбирает только те строки, которые удовлетворяют И первому, И второму условию, а “или” отбирает строки, которые удовлетворяют любому из условий, ИЛИ первому, ИЛИ второму)
14.6.3 Создание колонок
Часто возникает задача перекодировать переменную – например, разбить непрерывные значения на группы, чтобы посмотреть различия между ними.
Например, продолжая предыдущий пример с фильтрацией первых 10 в рейтинге стран: для сравнения показателей, вклдывающихся в уровень счастья, нас может интересовать, отличаются ли “топовые” страны от всех остальных. Для этого нам проще создать отдельную колонку, которая служит индикатором, является ли страна “топовой”. Разберем, что это значит: нам нужно 1) создать новую колонку и 2) записать в нее значения, удовлятворяющие определенному условию. (1) достигается с помощью функции mutate() (как бы “измени” датафрейм, “примутируй” к нему колонку), а (2) достигается очень похожим на фильтрацию способом – с помощью функции ifelse (пример выше)
На паре топовые и не топовые страны превратились в hehe и not hehe, так и оставим.
whr_top <- whr %>%
mutate("Rank Category" = ifelse(`Happiness Rank` <=10, "hehe", "not hehe"))
View(whr_top)Если выведем датафрейм, увидим, что на последнем месте появилась новая колонка Rank Category.
Новые значения могут соответствовать и какой-либо математической операции, например, создадим новую колонку, показывающую, во сколько раз уровень счастья в стране превышает значения страны-дистопии:
14.6.4 Работа с пропущенными значениями (NA)
Как уже говорилось в разделе про типы данных, есть отдельный тип данных, который кодирует пропущенные значения – NA, Not Available. Это особенный тип, потому что из-за пропущенных значений мы не можем оценить данные целиком. Такие ситуации встречаются крайне часто, поэтому придуманы специальные способы обращения с NA.
Для изучения этого раздела нам понадобятся данные 2016-2 по ссылке https://raw.githubusercontent.com/elenary/StatsForDA/main/2016-2.csv (правая кнопка мыши – сохранить как)
Первая важная функция работы с промущенными значениями – это is.na(), проверка того, является ли каждый элемент вектора или датафрейма NA, и механизмы подсчета количества таких значений.
## [1] FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE TRUE FALSE FALSE FALSE
## [13] TRUE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [25] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [37] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [49] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [61] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [73] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [85] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [97] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [109] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [121] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [133] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [145] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [157] FALSE#помним, что TRUE -- это 1, а FALSE -- 0. Поэтому можем перевести результаты в числовой вектор
as.numeric(is.na(whr_new$`Happiness Score`))## [1] 0 0 0 0 0 0 1 1 1 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
## [38] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
## [75] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
## [112] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
## [149] 0 0 0 0 0 0 0 0 0## [1] 5## [1] 5Одна из больших проблем с этими значениями – они мешают производить вычисления. Когда часть данных отсутствует, невозможно сказать, каково среднее выборки.
## [1] NA## [1] NAТак происходит, потому что невозможно прибавить, вычесть или даже сравнить с чем-то значение, которое недоступно
## [1] NA## [1] NA## [1] NAДля этого пропущенные значения обычно удаляют из рассмотрения. Например, с помощью функции na.omit() в базовом R или с помощью drop_na() в нотации tifdyverse. Важно! В зависимости от того, к чему мы применяем эту функции, мы либо удаляем NA из отобранной нами колонки, либо, если применяем ко всему датафрейму – удалятся все строки, в которых есть NA хотя бы в одной из колонок.
## [1] 7.526 7.509 7.501 7.498 7.413 7.404 NA NA NA 7.291 7.267 7.119
## [13] NA 7.087 NA 6.994 6.952 6.929 6.907 6.871 6.778 6.739 6.725 6.705
## [25] 6.701 6.650 6.596 6.573 6.545 6.488 6.481 6.478 6.474 6.379 6.379 6.375
## [37] 6.361 6.355 6.324 6.269 6.239 6.218 6.168 6.084 6.078 6.068 6.005 5.992
## [49] 5.987 5.977 5.976 5.956 5.921 5.919 5.897 5.856 5.835 5.835 5.822 5.813
## [61] 5.802 5.771 5.768 5.743 5.658 5.648 5.615 5.560 5.546 5.538 5.528 5.517
## [73] 5.510 5.488 5.458 5.440 5.401 5.389 5.314 5.303 5.291 5.279 5.245 5.196
## [85] 5.185 5.177 5.163 5.161 5.155 5.151 5.145 5.132 5.129 5.123 5.121 5.061
## [97] 5.057 5.045 5.033 4.996 4.907 4.876 4.875 4.871 4.813 4.795 4.793 4.754
## [109] 4.655 4.643 4.635 4.575 4.574 4.513 4.508 4.459 4.415 4.404 4.395 4.362
## [121] 4.360 4.356 4.324 4.276 4.272 4.252 4.236 4.219 4.217 4.201 4.193 4.156
## [133] 4.139 4.121 4.073 4.028 3.974 3.956 3.916 3.907 3.866 3.856 3.832 3.763
## [145] 3.739 3.739 3.724 3.695 3.666 3.622 3.607 3.515 3.484 3.360 3.303 3.069
## [157] 2.905## [1] NA## [1] 5.321539## [1] NA## [1] 5.321539# обратите внимание -- так тоже работает, но среднее другое! Почему?
whr_new %>%
drop_na() %>%
select(`Happiness Score`) %>%
pull() %>%
mean()## [1] 5.266447Для работы конкретно с описательным статистиками и аггрегирующими функциями вроде суммы еще есть один лайфхак работы с пропущенными значениями – аргумент na.rm = TRUE внутри функций mean(), median(), sum(). na.rm = TRUE буквально значит “na remove = true”
## [1] 5.321539## [1] 5.32153914.6.5 Сортировка
Еще одна часто встречающая задача – отсортировать датафрейм по возрастанию или убыванию одной переменной.
Когда у нас есть только один вектор (числовой или текстовый), а не вся табличка данных, мы можем сделать это так средствами базового R:
## [1] 2.905 3.069 3.303 3.360 3.484 3.515 3.607 3.622 3.666 3.695 3.724 3.739
## [13] 3.739 3.763 3.832 3.856 3.866 3.907 3.916 3.956 3.974 4.028 4.073 4.121
## [25] 4.139 4.156 4.193 4.201 4.217 4.219 4.236 4.252 4.272 4.276 4.324 4.356
## [37] 4.360 4.362 4.395 4.404 4.415 4.459 4.508 4.513 4.574 4.575 4.635 4.643
## [49] 4.655 4.754 4.793 4.795 4.813 4.871 4.875 4.876 4.907 4.996 5.033 5.045
## [61] 5.057 5.061 5.121 5.123 5.129 5.132 5.145 5.151 5.155 5.161 5.163 5.177
## [73] 5.185 5.196 5.245 5.279 5.291 5.303 5.314 5.389 5.401 5.440 5.458 5.488
## [85] 5.510 5.517 5.528 5.538 5.546 5.560 5.615 5.648 5.658 5.743 5.768 5.771
## [97] 5.802 5.813 5.822 5.835 5.835 5.856 5.897 5.919 5.921 5.956 5.976 5.977
## [109] 5.987 5.992 6.005 6.068 6.078 6.084 6.168 6.218 6.239 6.269 6.324 6.355
## [121] 6.361 6.375 6.379 6.379 6.474 6.478 6.481 6.488 6.545 6.573 6.596 6.650
## [133] 6.701 6.705 6.725 6.739 6.778 6.871 6.907 6.929 6.952 6.994 7.087 7.119
## [145] 7.267 7.291 7.404 7.413 7.498 7.501 7.509 7.526## [1] 7.526 7.509 7.501 7.498 7.413 7.404 7.291 7.267 7.119 7.087 6.994 6.952
## [13] 6.929 6.907 6.871 6.778 6.739 6.725 6.705 6.701 6.650 6.596 6.573 6.545
## [25] 6.488 6.481 6.478 6.474 6.379 6.379 6.375 6.361 6.355 6.324 6.269 6.239
## [37] 6.218 6.168 6.084 6.078 6.068 6.005 5.992 5.987 5.977 5.976 5.956 5.921
## [49] 5.919 5.897 5.856 5.835 5.835 5.822 5.813 5.802 5.771 5.768 5.743 5.658
## [61] 5.648 5.615 5.560 5.546 5.538 5.528 5.517 5.510 5.488 5.458 5.440 5.401
## [73] 5.389 5.314 5.303 5.291 5.279 5.245 5.196 5.185 5.177 5.163 5.161 5.155
## [85] 5.151 5.145 5.132 5.129 5.123 5.121 5.061 5.057 5.045 5.033 4.996 4.907
## [97] 4.876 4.875 4.871 4.813 4.795 4.793 4.754 4.655 4.643 4.635 4.575 4.574
## [109] 4.513 4.508 4.459 4.415 4.404 4.395 4.362 4.360 4.356 4.324 4.276 4.272
## [121] 4.252 4.236 4.219 4.217 4.201 4.193 4.156 4.139 4.121 4.073 4.028 3.974
## [133] 3.956 3.916 3.907 3.866 3.856 3.832 3.763 3.739 3.739 3.724 3.695 3.666
## [145] 3.622 3.607 3.515 3.484 3.360 3.303 3.069 2.905Если нам нужно отсортировать всю табличку по какой-то колонке, придется прибегнуть к тайдиверс и отсортировать таблицу с помощью функции arrange(), где в качестве аргумента передается название колонки, по которой будем делать сортировку. А если нам нужно указать, что сортировка должна быть по убыванию, от большого к меньшего – необходимо вставить аргумент desc()
## # A tibble: 132 × 13
## Country Region `Happiness Rank` `Happiness Score` Lower Confidence Int…¹
## <chr> <chr> <dbl> <dbl> <dbl>
## 1 Sudan Sub-S… 133 4.14 3.93
## 2 Angola Sub-S… 141 3.87 3.75
## 3 Burundi Sub-S… 157 2.90 2.73
## 4 Greece Weste… 99 5.03 4.93
## 5 Syria Middl… 156 3.07 2.94
## 6 Bosnia and … Centr… 87 5.16 5.06
## 7 Haiti Latin… 136 4.03 3.89
## 8 Mauritania Sub-S… 130 4.20 4.13
## 9 Ukraine Centr… 123 4.32 4.24
## 10 Madagascar Sub-S… 148 3.70 3.62
## # ℹ 122 more rows
## # ℹ abbreviated name: ¹`Lower Confidence Interval`
## # ℹ 8 more variables: `Upper Confidence Interval` <dbl>,
## # `Economy (GDP per Capita)` <dbl>, Family <dbl>,
## # `Health (Life Expectancy)` <dbl>, Freedom <dbl>,
## # `Trust (Government Corruption)` <dbl>, Generosity <dbl>,
## # `Dystopia Residual` <dbl>whr_new %>%
drop_na() %>%
arrange(`Trust (Government Corruption)`) # сорировка всей таблицы по колонке Trust## # A tibble: 132 × 13
## Country Region `Happiness Rank` `Happiness Score` Lower Confidence Int…¹
## <chr> <chr> <dbl> <dbl> <dbl>
## 1 Bosnia and … Centr… 87 5.16 5.06
## 2 Bulgaria Centr… 129 4.22 4.10
## 3 Romania Centr… 71 5.53 5.43
## 4 Trinidad an… Latin… 43 6.17 5.95
## 5 Portugal Weste… 94 5.12 5.03
## 6 Lithuania Centr… 60 5.81 5.73
## 7 Ukraine Centr… 123 4.32 4.24
## 8 Moldova Centr… 55 5.90 5.82
## 9 Italy Weste… 50 5.98 5.90
## 10 China Easte… 83 5.24 5.20
## # ℹ 122 more rows
## # ℹ abbreviated name: ¹`Lower Confidence Interval`
## # ℹ 8 more variables: `Upper Confidence Interval` <dbl>,
## # `Economy (GDP per Capita)` <dbl>, Family <dbl>,
## # `Health (Life Expectancy)` <dbl>, Freedom <dbl>,
## # `Trust (Government Corruption)` <dbl>, Generosity <dbl>,
## # `Dystopia Residual` <dbl>whr_new %>%
drop_na() %>%
arrange(desc(`Happiness Score`)) # сортировка всей таблицы по колонке Happiness Score по убыванию## # A tibble: 132 × 13
## Country Region `Happiness Rank` `Happiness Score` Lower Confidence Int…¹
## <chr> <chr> <dbl> <dbl> <dbl>
## 1 Denmark Wester… 1 7.53 7.46
## 2 Switzerland Wester… 2 7.51 7.43
## 3 Iceland Wester… 3 7.50 7.33
## 4 Sweden Wester… 10 7.29 7.23
## 5 Austria Wester… 12 7.12 7.04
## 6 Germany Wester… 16 6.99 6.93
## 7 Brazil Latin … 17 6.95 6.88
## 8 Ireland Wester… 19 6.91 6.84
## 9 Luxembourg Wester… 20 6.87 6.80
## 10 Mexico Latin … 21 6.78 6.68
## # ℹ 122 more rows
## # ℹ abbreviated name: ¹`Lower Confidence Interval`
## # ℹ 8 more variables: `Upper Confidence Interval` <dbl>,
## # `Economy (GDP per Capita)` <dbl>, Family <dbl>,
## # `Health (Life Expectancy)` <dbl>, Freedom <dbl>,
## # `Trust (Government Corruption)` <dbl>, Generosity <dbl>,
## # `Dystopia Residual` <dbl>Выбрать одну колонку и отсортировать ее мы тоже можем, мы уже умеет выбирать одну колонку – нужно сначала применить функцию select():
whr_new %>%
drop_na() %>%
select(`Happiness Score`) %>%
arrange(`Happiness Score`) # сортировка одной колонки по возрастанию## # A tibble: 132 × 1
## `Happiness Score`
## <dbl>
## 1 2.90
## 2 3.07
## 3 3.30
## 4 3.36
## 5 3.48
## 6 3.52
## 7 3.62
## 8 3.67
## 9 3.70
## 10 3.74
## # ℹ 122 more rowswhr_new %>%
drop_na() %>%
select(`Happiness Score`) %>%
arrange(desc(`Happiness Score`)) # сортировка одной колонки по колонке по убыванию## # A tibble: 132 × 1
## `Happiness Score`
## <dbl>
## 1 7.53
## 2 7.51
## 3 7.50
## 4 7.29
## 5 7.12
## 6 6.99
## 7 6.95
## 8 6.91
## 9 6.87
## 10 6.78
## # ℹ 122 more rows14.7 Задания после семинара 3
- Выполните все примеры, которые есть в этом разделе, убедитесь, что все работает верно.
- Посмотрите, какие страны находятся на местах с 1 по 10 и с 147 по 157 (в выводе должно быть по две колонки:
RegionиHappiness Rank) - Сравните средний показатель экономики
Economy (GDP per Capita)и уровень счастьяHappiness Scoreв странах Восточной и центральной (Central and Eastern Europe) и Западной Европы (Western Europe). Что можно сказать про них? Где показатель экономики выше? Где люди чувствуют себя счастливее? - Сравните средний показатель экономики
Economy (GDP per Capita)и уровень счастьяHappiness Scoreв странах Западной Европы (Western Europe) и Южной Азии (Southern Asia). Что можно сказать про них? Где показатель экономики выше? Где люди чувствуют себя счастливее? - (Только для тех, кто работает в R) Посчитайте средний
Happiness Scoreпо всем странам и выведете страны, которые лежат в границах ± 1 от среднегоHappiness Score(в выводе должно быть по две колонки:RegionиHappiness Score) Подсказка: возможно, будет проще посчитать среднее отдельно и сначала сохранить его в переменную - Создайте колонку, в которой будет содержаться информация, в текущей стране
Happiness Scoreвыше или ниже среднего значения (колонка может быть заполнена, например, значениями upper и lower или любыми другими обозначениями)
14.8 Описательные статистики и агрегация
14.8.1 Описательные статистики
Мы уже немножко считали описательные статистики в самом начале работы с данными, чтобы было пободрее продвигаться. Теперь давайте остановимся на них поподробнее.
Самые частые описательные статистики из мер центральной тенденции – среднее, медиана и мода. Среднее и медиану мы уже строили, а как построить моду?
## [1] 5.321539## [1] 5.285## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 2.905 4.387 5.285 5.322 6.105 7.526 5Так получилось, что в R нет специальной функции для моды. У этого есть и логическая причина – жанные, с которыми мы в основном работаем – количественные непрерывные, и мы обсуждали, что для такого рода данных понятие моды немного искуственно. Но нам все равно бывает нужно посчитать моду. Поэтому можно либо написать функцию для ее расчета самостоятельно, либо воспользоваться готовой функцией из пакета. Я погуглила, что можно сделать, и вам рекомендую всегда так делать в таких ситуациях – и выбрала функцию mlv() (most likely value) из пакета modeest
## Warning: argument 'method' is missing. Data are supposed to be continuous.
## Default method 'shorth' is used## [1] 5.239092## [1] "Sub-Saharan Africa"Либо, можно воспользоваться простой функцией table(), которая считает количество значений указанной переменной.
##
## Australia and New Zealand Central and Eastern Europe
## 2 29
## Eastern Asia Latin America and Caribbean
## 6 24
## Middle East and Northern Africa North America
## 19 2
## Southeastern Asia Southern Asia
## 9 7
## Sub-Saharan Africa Western Europe
## 38 21Помимо мер центральной тенденции можем посчитать меры изменчивости – минимальное и максимальное, размах, стандартное отклонение, дисперсию, межквартильный размах.
## [1] 2.905## [1] 7.526## [1] 2.905 7.526## [1] 1.108958## [1] 1.229787## [1] 1.71825Мы так же рассчитывали описательные статистики с помощью функции summary(). Есть более продвинутые функции, которые считают большое количество описательных статистик сразу. Например, часто используется функция skim() из пакета skimr – помимо мер центральной тенденции и всех четырех квартителей, она считает стандартное отклонение и даже строит маленькую гистограммку.
summary(whr_new$Happiness Score)
## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 2.905 4.387 5.285 5.322 6.105 7.526 5| Name | whr_new$Happiness Score |
| Number of rows | 157 |
| Number of columns | 1 |
| _______________________ | |
| Column type frequency: | |
| numeric | 1 |
| ________________________ | |
| Group variables | None |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| data | 5 | 0.97 | 5.32 | 1.11 | 2.9 | 4.39 | 5.28 | 6.1 | 7.53 | ▂▆▇▇▃ |
14.8.2 Агрегация данных
Что произошло, когда мы смотрели частоту выпадения значений с помощью table()? Данные сгруппировались по значениям переменной Region, которую мы указали, и было посчитано количество значений в каждой группе. Когда мы группируем данные по значениям переменной и производим какой-либо расчет для группы, это называется агрегацией данных.
Это полезно, чтобы посчитать те же описательные статистики по группам, например, посчитаем среднее для переменных Freedom и Trust в зависимости от региона:
## # A tibble: 8 × 2
## Region mean_score
## <chr> <dbl>
## 1 Central and Eastern Europe 5.40
## 2 Eastern Asia 5.62
## 3 Latin America and Caribbean 6.01
## 4 Middle East and Northern Africa 5.39
## 5 Southeastern Asia 5.16
## 6 Southern Asia 4.56
## 7 Sub-Saharan Africa 4.16
## 8 Western Europe 6.55whr_new %>%
drop_na() %>%
group_by(Region) %>%
summarise(mean_score = mean(`Happiness Score`), mean_freedom = mean(Freedom),
mean_trust = mean(`Trust (Government Corruption)`)) %>%
arrange(desc(mean_score))## # A tibble: 8 × 4
## Region mean_score mean_freedom mean_trust
## <chr> <dbl> <dbl> <dbl>
## 1 Western Europe 6.55 0.452 0.213
## 2 Latin America and Caribbean 6.01 0.419 0.105
## 3 Eastern Asia 5.62 0.387 0.118
## 4 Central and Eastern Europe 5.40 0.292 0.0770
## 5 Middle East and Northern Africa 5.39 0.316 0.178
## 6 Southeastern Asia 5.16 0.495 0.124
## 7 Southern Asia 4.56 0.350 0.105
## 8 Sub-Saharan Africa 4.16 0.324 0.12514.9 Визуализации
Мы уже строили простенькие визуализации – простую гистограмму и простой график плотноти веростности средствами базового R.
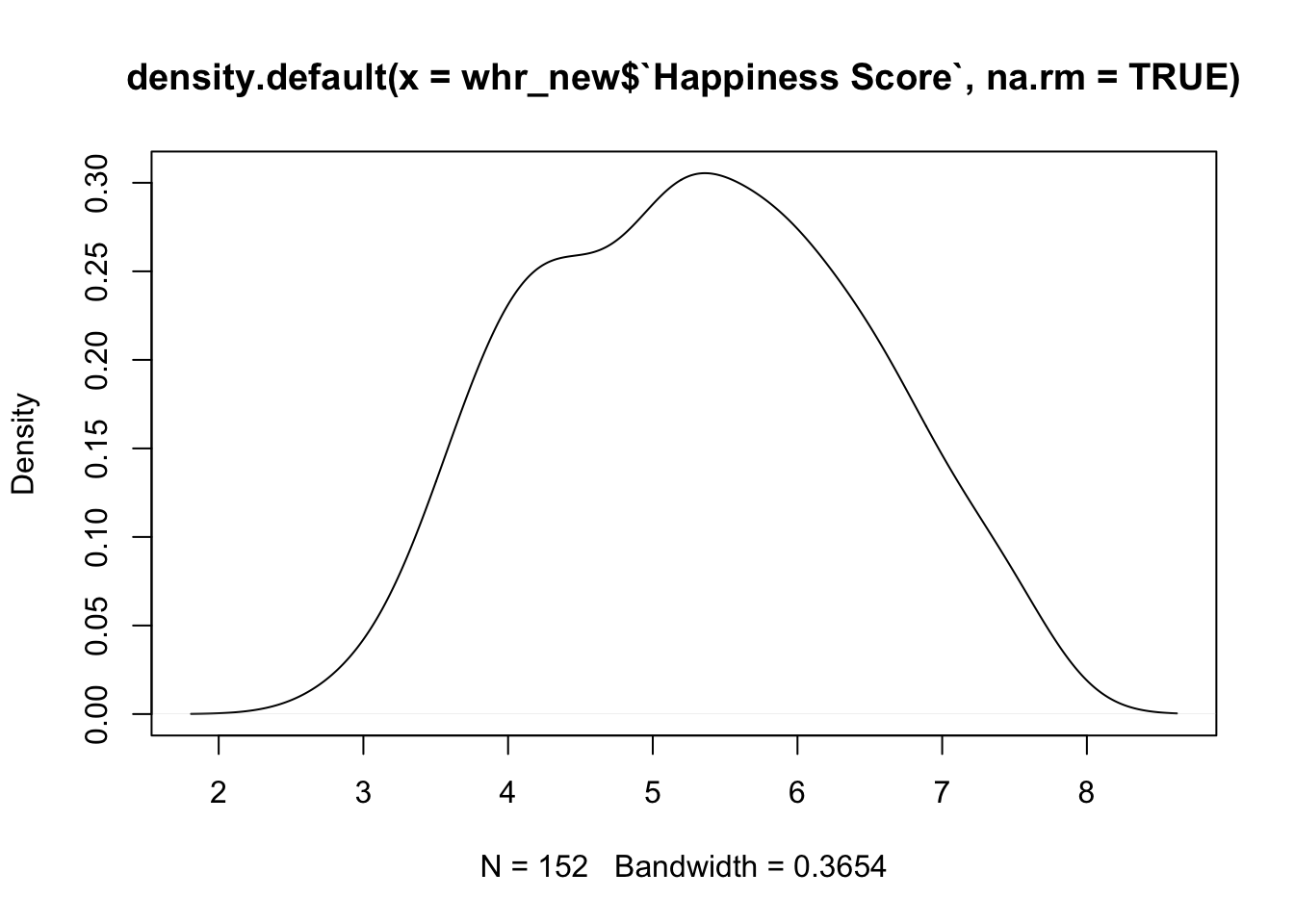
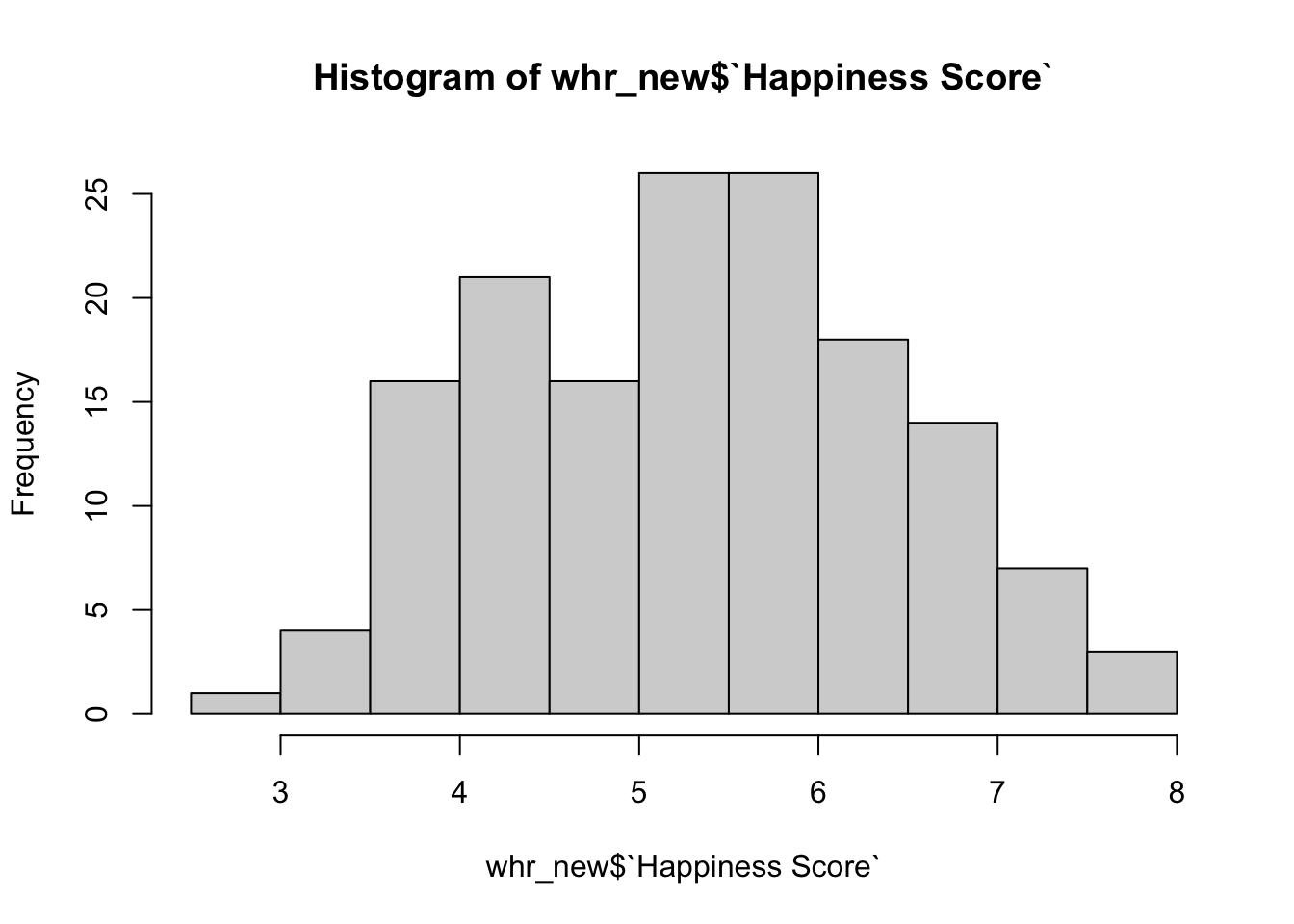
Эти визуализации верны, но они стандартные и выглядят не очень красиво. А меж тем визуализации очень важны – от их качества зависит понятность представления данных, с помощью визуилизаций можно даже манипулировать данными. В скриптовых языках огромное количество инструментов для работы с визуализациями. В питоне это matplotlib. А теперь добро пожаловать в ggplot2 – вселенную графиков в R https://ggplot2.tidyverse.org/
Например, можно нарисовать такой график, или такой. Все это достигается средствами пакета ggplot2, который уже интегрирован в tidyverse.
{kind=link}
“gg” в названии пакета означает Grammar of graphics. Подробно можно почитать, например, у Ивана Позднякова https://pozdniakov.github.io/tidy_stats/230-ggplot2.html
Принцип состоит из рисовки графиком по слоям. Обязательные слои:
- данные (data)
- эстетики (aes) или mapping – то, как наши данные “натягиваются” на график
- геомы (geom) – геометрические объекты, которые будем рисовать (например, гистограмма или барплот)
Вспомогательные слои:
- статистики (stats) – нужно ли посчитать какие-то агрегированные статистики прямо на графике
- система координат (coord) – можно повернуть систему координат на 90 градусов или вообще заменить ее на полярную
- темы (theme) – системы оформления, одно из самых приятных
 Изображение из The Grammar of Graphics
Изображение из The Grammar of Graphics
ggplot отлично интегрируется с тайдиверс, но он появился, оформился и распространился раньше, поэтому вместо значка пайпа %>% там +.
Нарисуем ту же гистограмму, но уже покрасивее:
## Warning: Removed 5 rows containing non-finite values (`stat_bin()`).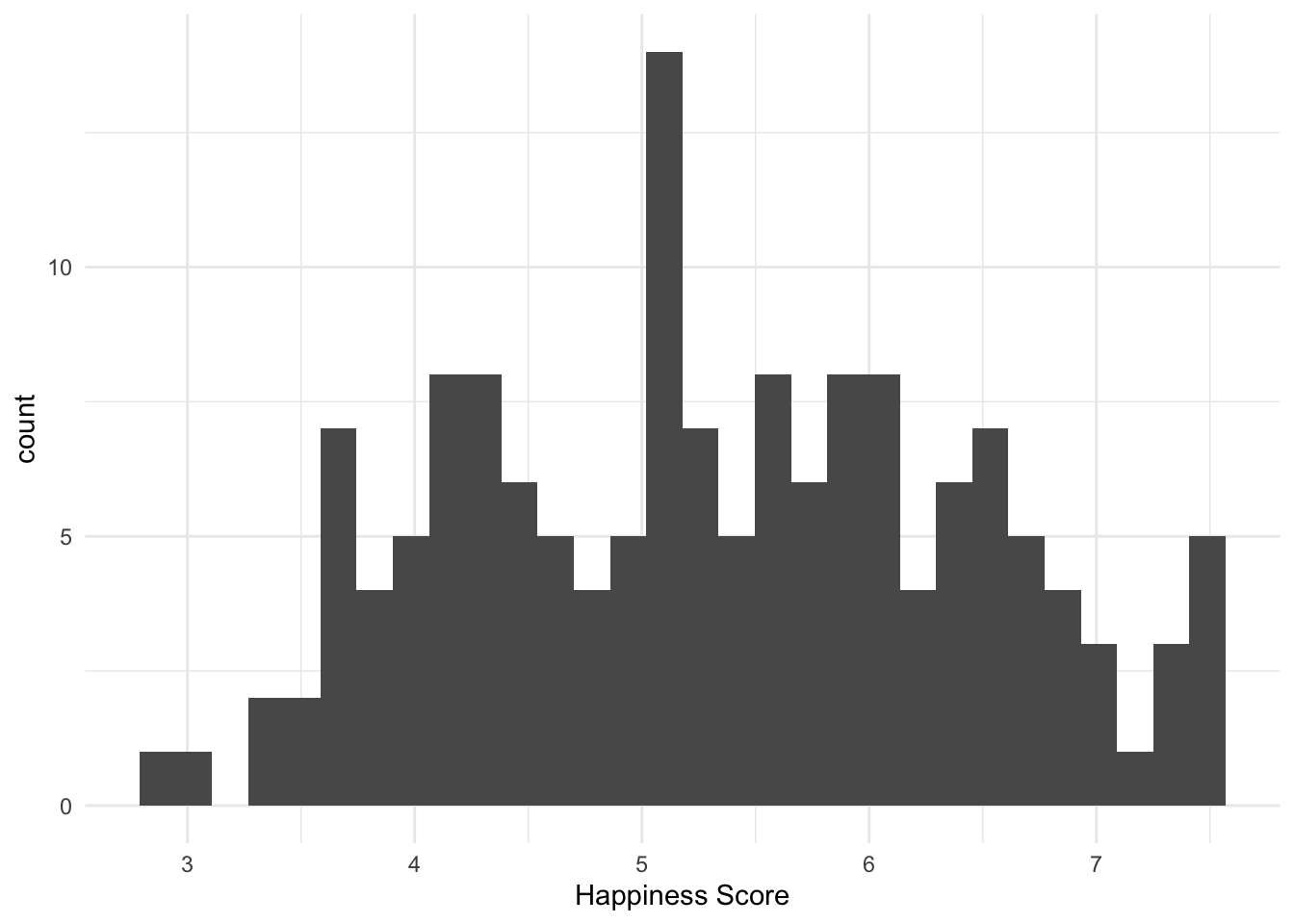
# Можем регулировать ширину "кирпичика"
whr_new %>%
ggplot(aes(x = `Happiness Score`)) +
geom_histogram(binwidth = 0.5) +
theme_minimal()## Warning: Removed 5 rows containing non-finite values (`stat_bin()`).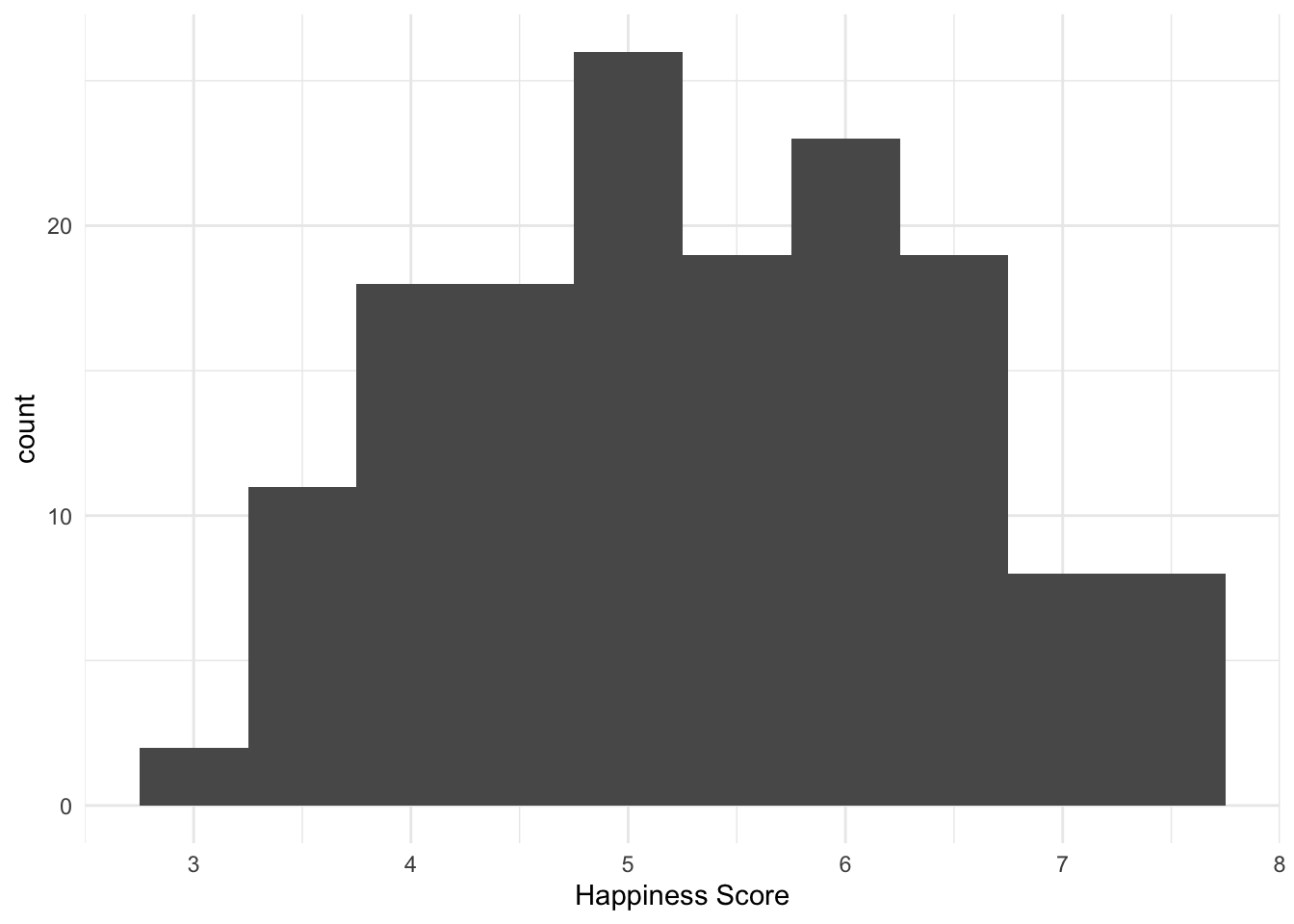
Можем менять цвета у двух вещей: заливки и контура, как и обычно у фигур в паверпоинте или ворде. Для заливки используется аругмент fill, для контура – color. У некоторых геомов есть только контур – как, например, диаграмма рассеяния, так как точки не имеют заливки.
# раскрасим заливку (fill) в розовый, а линии (color) в фиолетовый
# можем использовать не слова вроде pink и violet, а коды цветов в 16-ричной системе, например "#355C7D"
whr_new %>%
ggplot(aes(x =`Happiness Score`)) +
geom_histogram(fill = "pink", color = "violet", binwidth = 0.5) +
theme_minimal()## Warning: Removed 5 rows containing non-finite values (`stat_bin()`).
# добавим 50% прозрачности
whr_new %>%
ggplot(aes(x =`Happiness Score`)) +
geom_histogram(fill = "pink", color = "violet", alpha = 0.5, binwidth = 0.5) +
theme_minimal()## Warning: Removed 5 rows containing non-finite values (`stat_bin()`).
Построим аналогичный график плотности вероятности
## Warning: Removed 5 rows containing non-finite values (`stat_density()`).
# раскрасим линию в фиолетовый
whr_new %>%
ggplot(aes(x =`Happiness Score`)) +
geom_density(color = "violet") +
theme_minimal()## Warning: Removed 5 rows containing non-finite values (`stat_density()`).
# поменяем тип линии на пунктир (соответствие типов линий и кодов
# можно погуглить или посмотреть в читшите)
whr_new %>%
ggplot(aes(x =`Happiness Score`)) +
geom_density(color = "violet", linetype = 5) +
theme_minimal()## Warning: Removed 5 rows containing non-finite values (`stat_density()`).
#добавили заливку и прозрачность
whr_new %>%
ggplot(aes(x =`Happiness Score`)) +
geom_density(color = "violet", fill = "pink", linetype = 5, alpha = 0.5) +
theme_minimal()## Warning: Removed 5 rows containing non-finite values (`stat_density()`).
Все эти графики были описательными – для исследования одной переменной. А теперь выведем диаграмму рассеяния, в которой показано распределение одной переменной в заивисимости от значений другой.
## Warning: Removed 5 rows containing missing values (`geom_point()`).
И можем даже раскрасить точки на этом графике в зависимости от значений третьей переменной! Например, региона. Все ровно так же, как и с цветами до этого: если хотим залить фигуру в зависимости от значений третьей переменной, то для раскраски используется аругмент fill, если покрасить контур – то color (как контур и заливка в ворде или паверпоинт). Но с той разницей, что теперь fill color задаются внутри аестетик, так как это все еще про “натягивание совы на глобус”, то есть наших данных на график.
whr_new %>%
ggplot(aes(x = `Happiness Score`, y = Freedom, color = Region)) +
geom_point() +
theme_minimal()## Warning: Removed 5 rows containing missing values (`geom_point()`).
Существует огромное количество дополнительных штук для более красивых визуализаций в ggplot, чтобы делать что-то по-настоящему невероятное. Мы, конечно, не успеем познакомиться с ними в рамках курса, но вот, например, дополнительный пакет с палетками, сделанными по фильмам Уэса Андерсена:) Если мы хотим раскрасить наш график не просто в цвета по умолчанию, а в какие-то особенные – есть пакет, в которые собрали цветовые схемы из этих фильмов! Сначала его нужно привычно поставить через install.packages(), подключить через library(), а далее добавить одну строчку с добавлением шкалы scale_fill_manual() или scale_color_manual() – опять же, в зависимости от того, хотим мы делать заливку этими палетками или контур.
# install.packages("wesanderson")
library(wesanderson)
whr %>%
filter(Region %in% c("Western Europe", "Eastern Asia", "Sub-Saharan Africa")) %>% #здесь я фильтрую часть строк, входящих только в три региона, чтобы на графике были только три цвета и не было цветового взрыва, так как регионов в данных много
ggplot(aes(x = `Happiness Score`, y = `Trust (Government Corruption)`,
fill = Region)) +
geom_boxplot() +
theme_minimal() +
scale_fill_manual(values = wes_palette("Royal1"))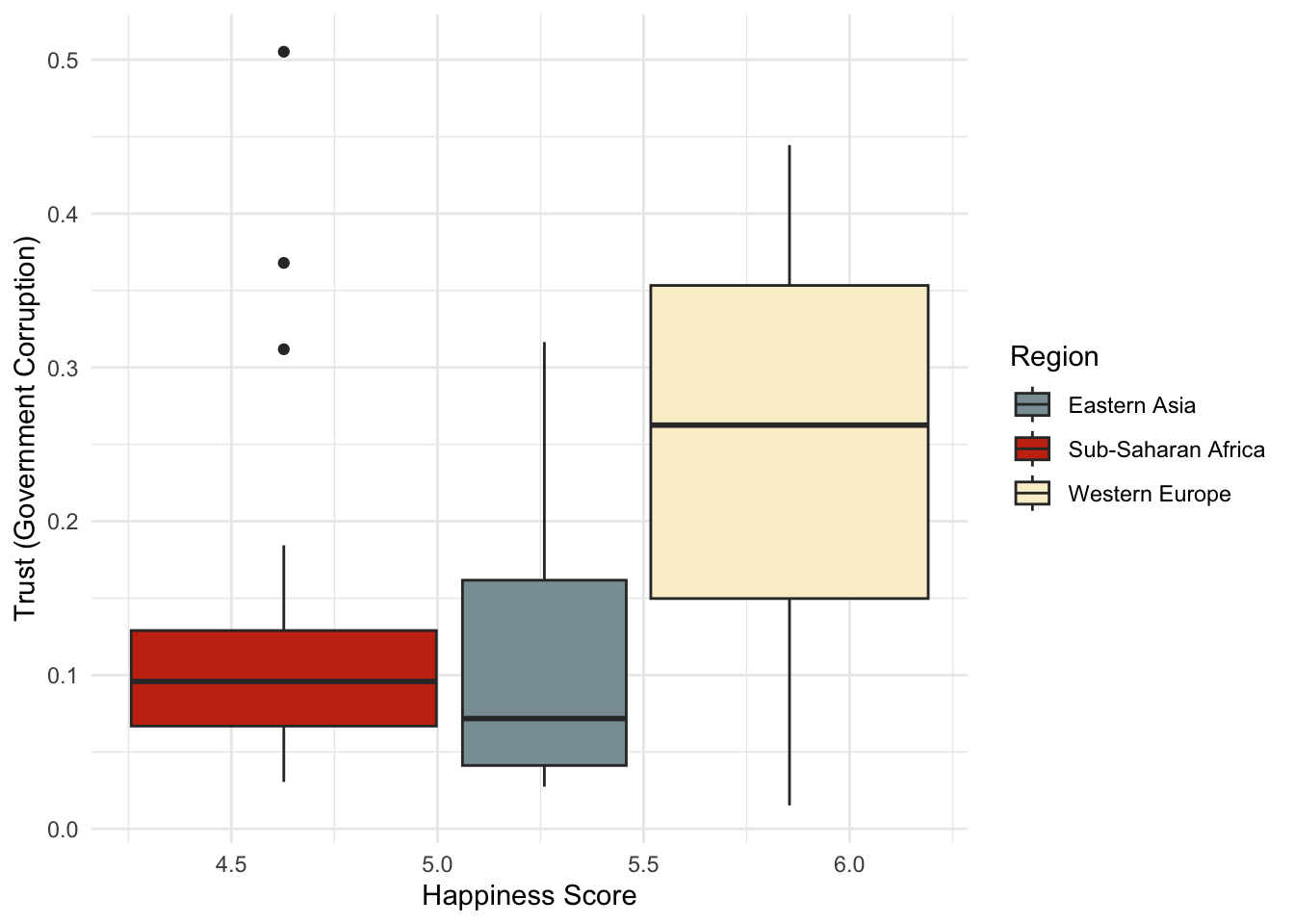
14.10 Задания после семинара 4
Для заданий используется датасет 2016-2
- Выполните все примеры, которые есть в этом разделе, убедитесь, что все работает верно.
- Посчитайте, сколько всего суммарно NA в колонках
Economy (GDP per Capita),Family,Health (Life Expectancy),Freedom,Trust (Government Corruption),Generosity(задание можно сделать разными способами, подойдет любой, дающий верный овтет) - Посчитайте описательные статистики для колонок
Economy (GDP per Capita),Family,Freedom: среднее, медиану, моду, стандартное отклонение, дисперсию и межквартильный размах, а также (только для тех, кто работает в R) вычислите значения для 1 и 3 квартилей. Ответы должны быть отличны отNA(один из способов узнать значения по квартилям – например, с помощью отдельных общих функций для описательных статистик). - Используя созданную в прошлой домашке колонку co значениями
upperиlowerв зависимости от значенийHappiness Score, посчитайте среднее и стандартное отклонения внутри этих групп (upperиlower) для колонокEconomy (GDP per Capita),Family,Freedom. (Только для тех, кто работает в R) Сравните полученные средние значения со значениями для 1 и 3 квартилей из предыдущего задания. Что можно сказать про них? - Постройте графики плотности вероятности для переменных
FamilyиFreedom, (только для тех, кто работает в R) используя как минимум 2 отличиные от дефолтных настройки (тему, цвет, тип линии, прозрачность и тд.) Примеры можно погуглить или посмотреть в читшите - Постройте диаграмму рассеяния для переменной
Familyпо переменнойFreedomи (только для тех, кто работает в R) раскрасьте точки в зависимости от значений переменной с upper и lower, созданной в прошлой домашке. - Посчитайте коэффициент корреляции между переменными
FamilyиFreedom.
14.11 Проверка гипотез
Пришло время перейти к тому, ради чего мы изучали статистику весь прошлый семестр – проверке гипотез.
Я собрала в один датасет все новые колонки, которые мы создавали, чтобы использовать их, если понадобятся.
whr %>%
mutate("top20" = ifelse(`Happiness Rank`<=20, "hehe", "not hehe"),
"mean_position" = ifelse(`Happiness Score`>= mean(`Happiness Score`, na.rm = TRUE), "upper", "lower")) -> whr_testsПеред применением статистических тестов стоит повторить раздел про статистический вывод целиком и алгоритм тестирования гипотез в частности. Мы не применяем тесты сразу! Сначала у нас должна быть осмысленная гипотеза, понимание о том, каковы \(H_0\) и \(H_1\), выбранный уровень значимости \(\alpha\) и рассчитанное на основании статистической мощности \(power\) необходимое количество данных. Здесь мы работаем уже с готовыми данными, поэтому не можем влиять на количество данных, но все остальные пункты мы должны учитывать.
14.11.1 Корреляционный тест
Первое, с чем потренируемся – корреляционный тест
Сначала проверяем допущения к применимости корреляционного теста
#Смотрим наличие линейной зависимости
whr_tests %>%
ggplot(aes(x = Family, y = `Happiness Score`)) +
geom_point(color = "#355C7D") +
theme_minimal()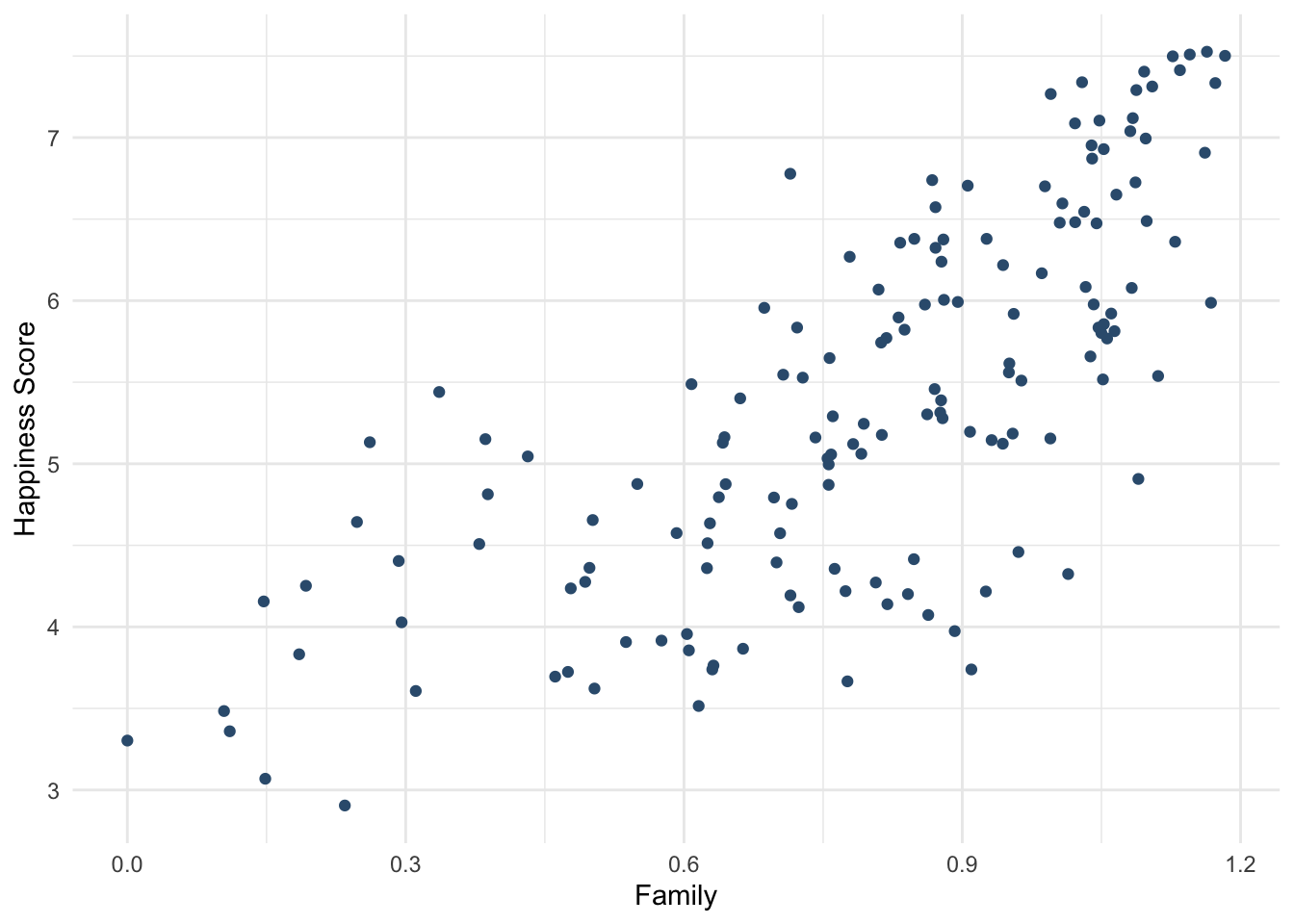
# смотрим, как распределены переменные, которые хотим прокоррелировать
whr_tests %>%
ggplot(aes(x = Family, y = `Happiness Score`)) +
geom_point(color = "#355C7D") +
theme_minimal()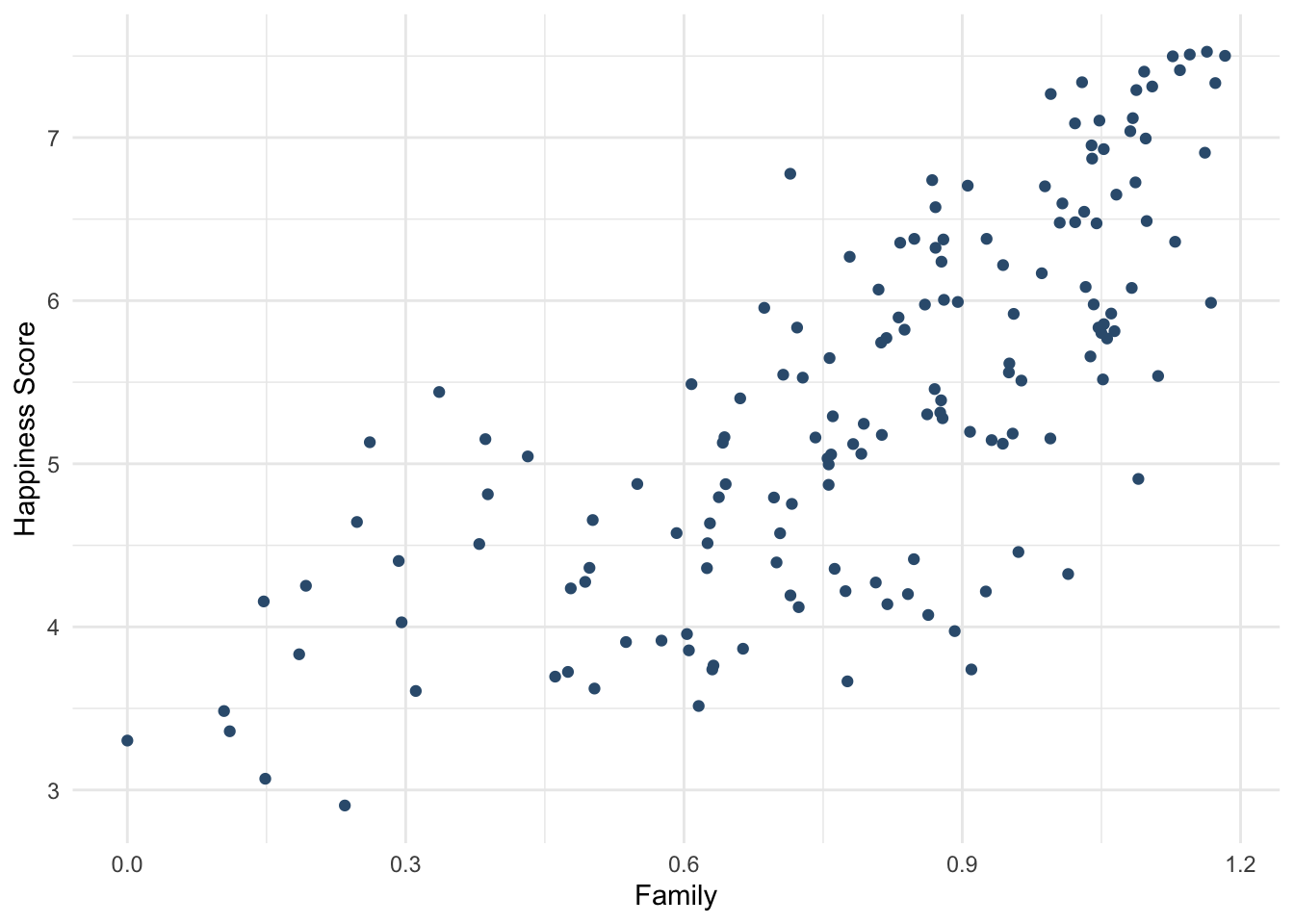
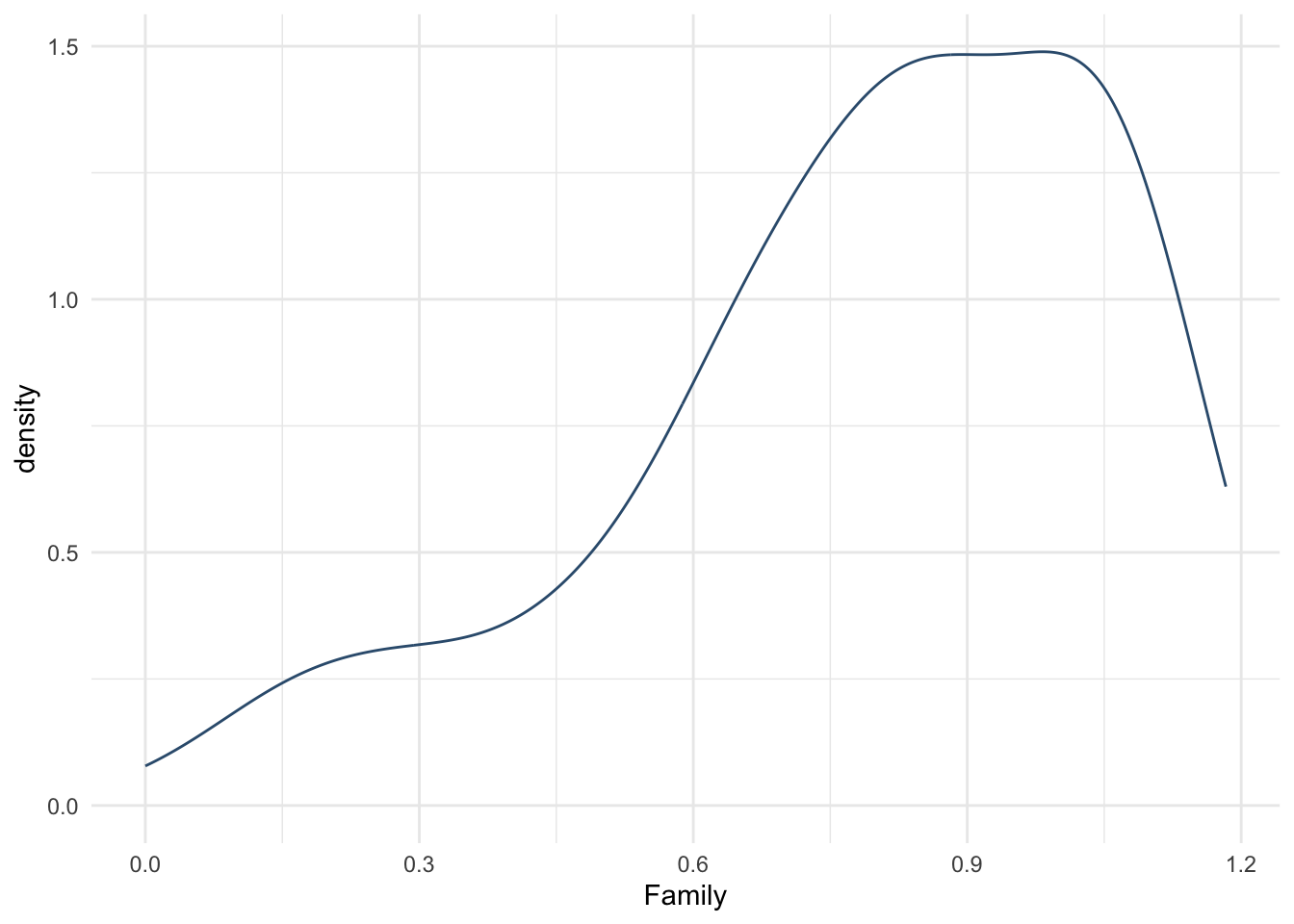
whr_tests %>%
ggplot(aes(sample = Family)) +
stat_qq(color = "#355C7D") +
geom_qq_line() +
theme_minimal()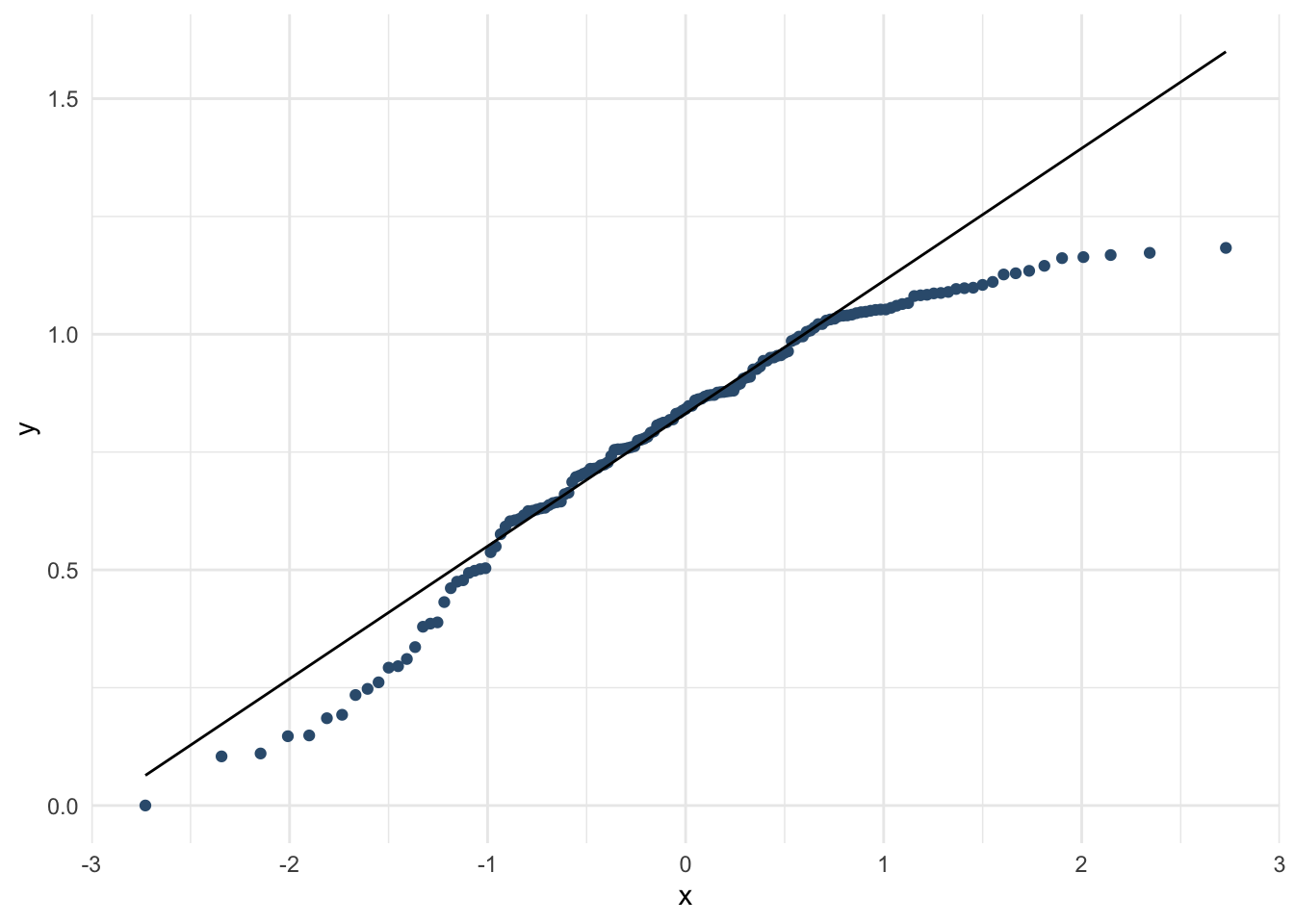
# Видим, что переменная Family распрееделена доволньо сильно отлично от нормального, на всякий случай делаем корреляцию Спирмена вместо Пирсона
cor.test(whr_tests$`Happiness Score`, whr_tests$Family, method = "spearman")## Warning in cor.test.default(whr_tests$`Happiness Score`, whr_tests$Family, :
## Cannot compute exact p-value with ties##
## Spearman's rank correlation rho
##
## data: whr_tests$`Happiness Score` and whr_tests$Family
## S = 153450, p-value < 2.2e-16
## alternative hypothesis: true rho is not equal to 0
## sample estimates:
## rho
## 0.762077whr_tests %>%
ggplot(aes(x = Freedom, y = `Happiness Score`)) +
geom_point(color = "#355C7D") +
theme_minimal()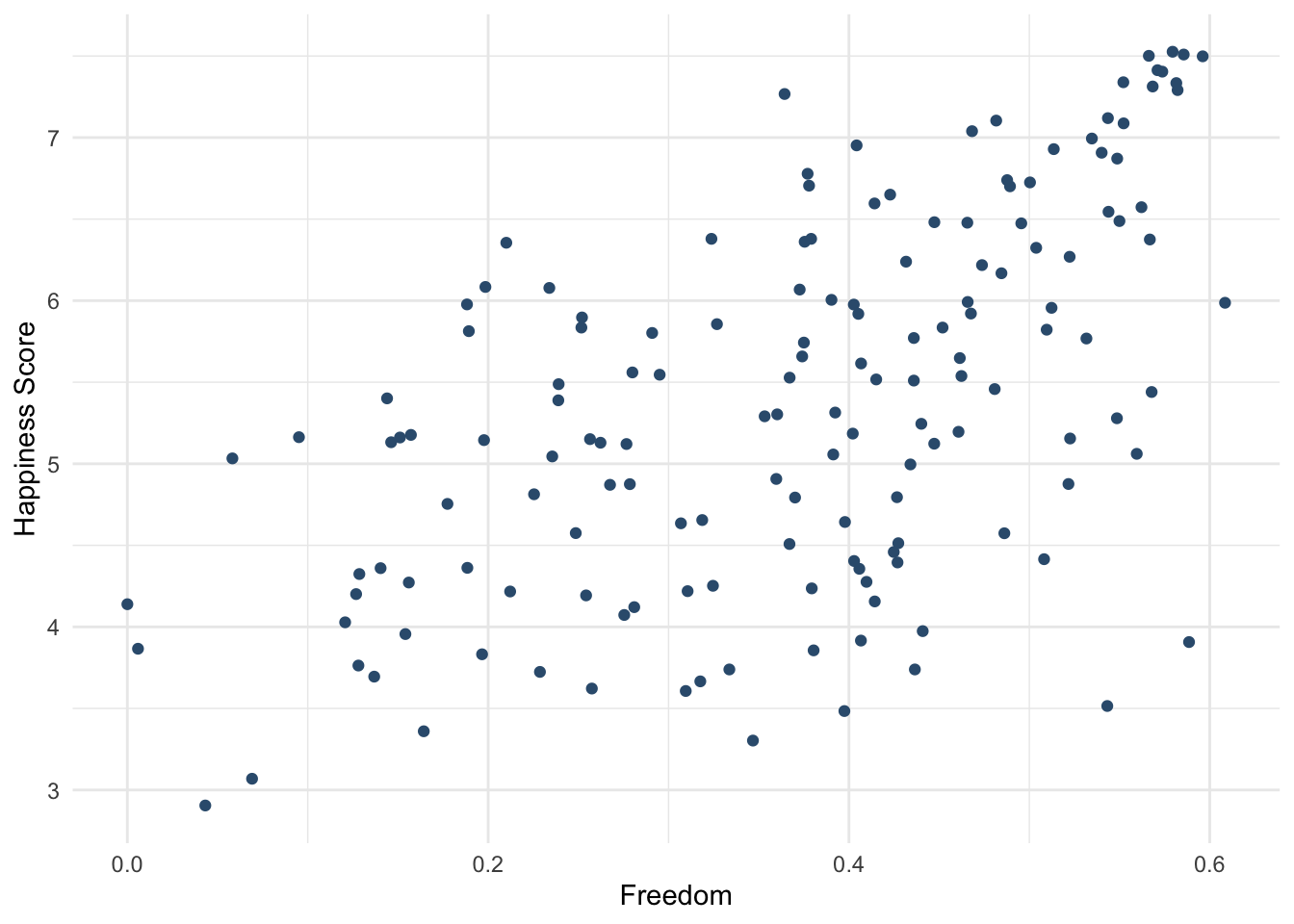
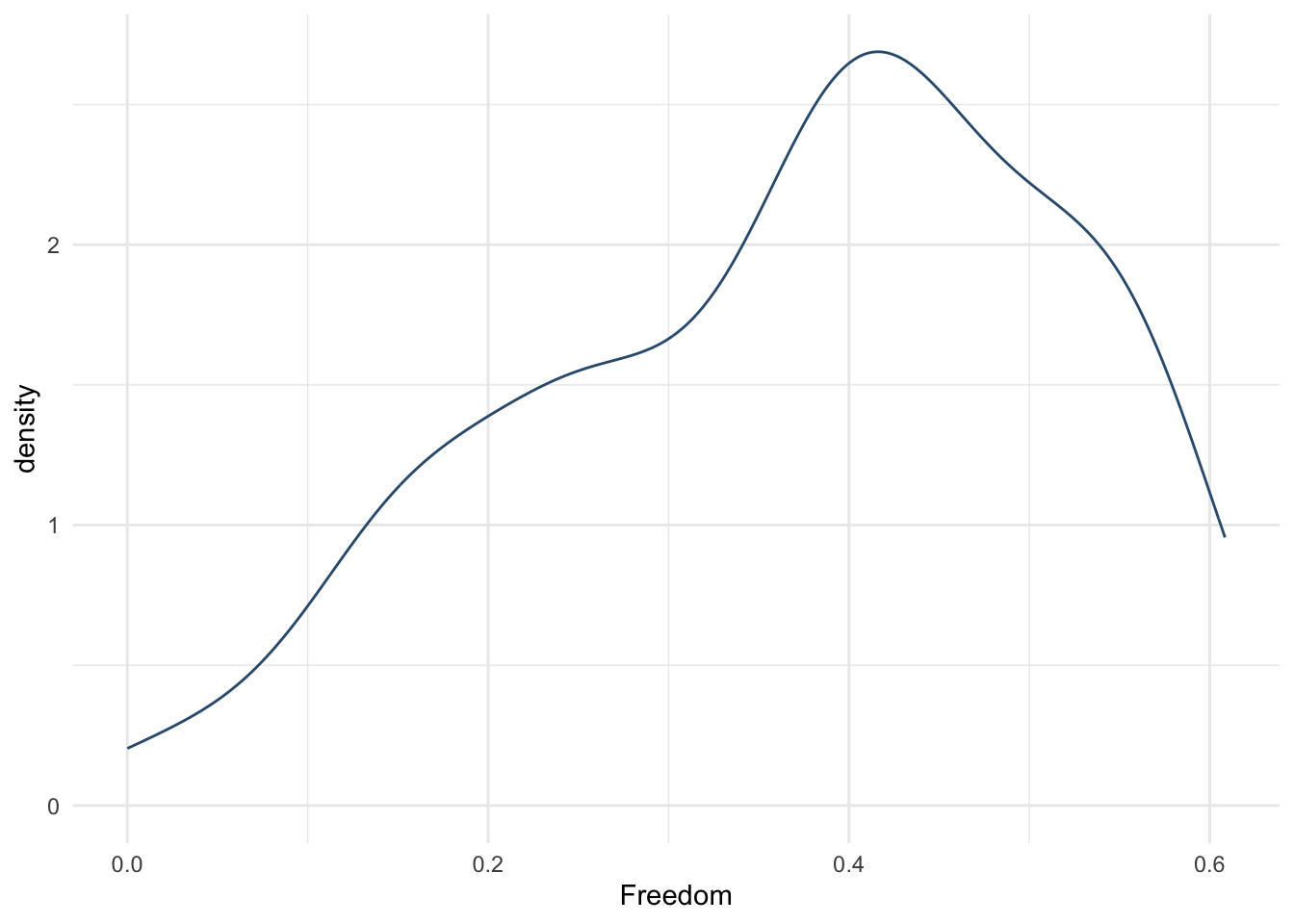
whr_tests %>%
ggplot(aes(sample = Freedom)) +
stat_qq(color = "#355C7D") +
geom_qq_line() +
theme_minimal()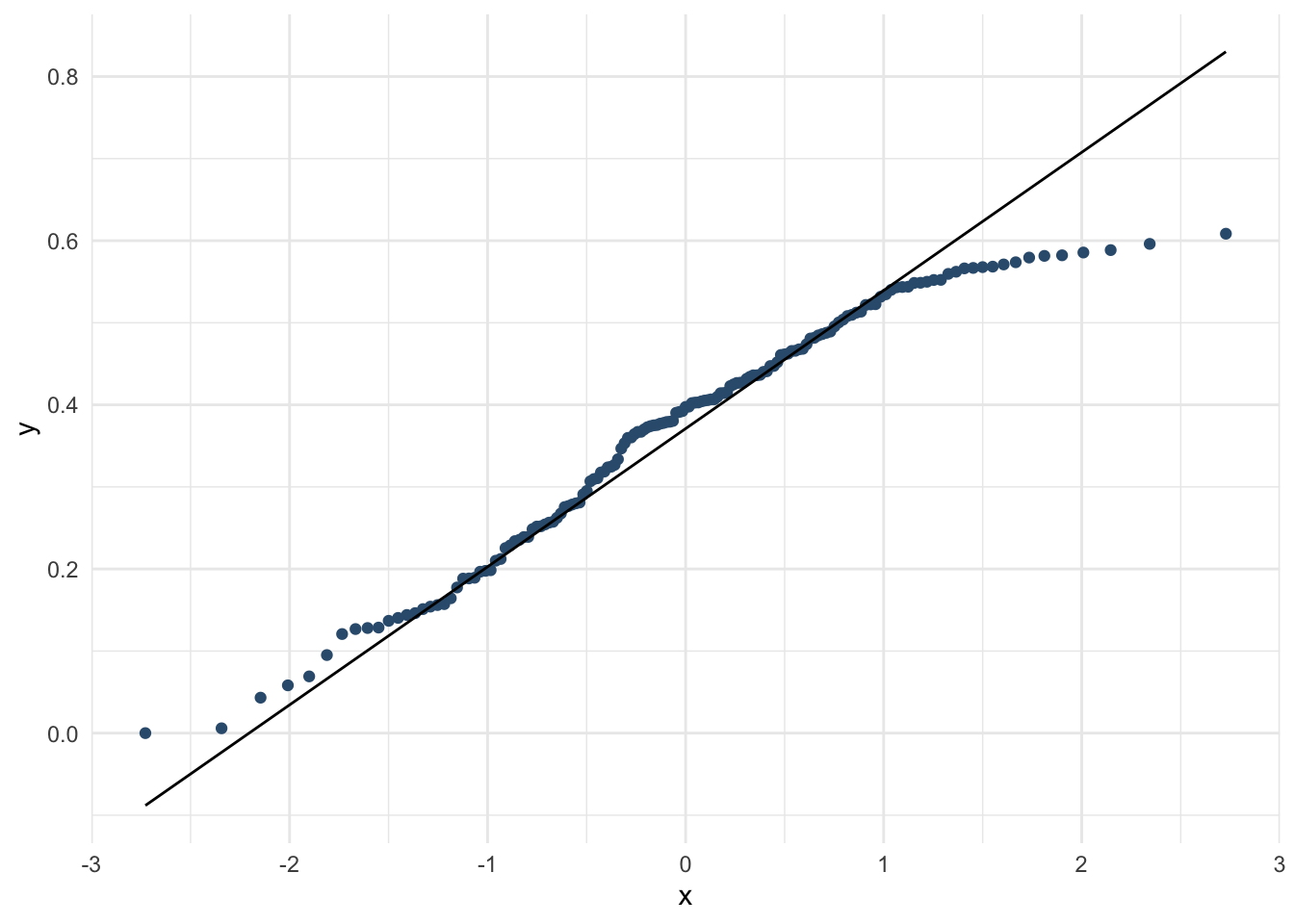
# А здесь можно корреляцию Пирсона
cor.test(whr_tests$`Happiness Score`, whr_tests$Family, method = "pearson")##
## Pearson's product-moment correlation
##
## data: whr_tests$`Happiness Score` and whr_tests$Family
## t = 13.667, df = 155, p-value < 2.2e-16
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.6589122 0.8029161
## sample estimates:
## cor
## 0.7392516Как это проинтепретировать? Вспоминаем все, что мы изучали про статистические критерии в прошлом семестре.
Кстати, в языках программирования числа часто записываются через экспоненциальную нотацию виде \(e^-10\) – это удобно для математического вида, какая цифра идет первой после множества нулей, но неудобно для интерпретации. Чтобы ее убрать, можно в любом месте в Р выполнить операцию
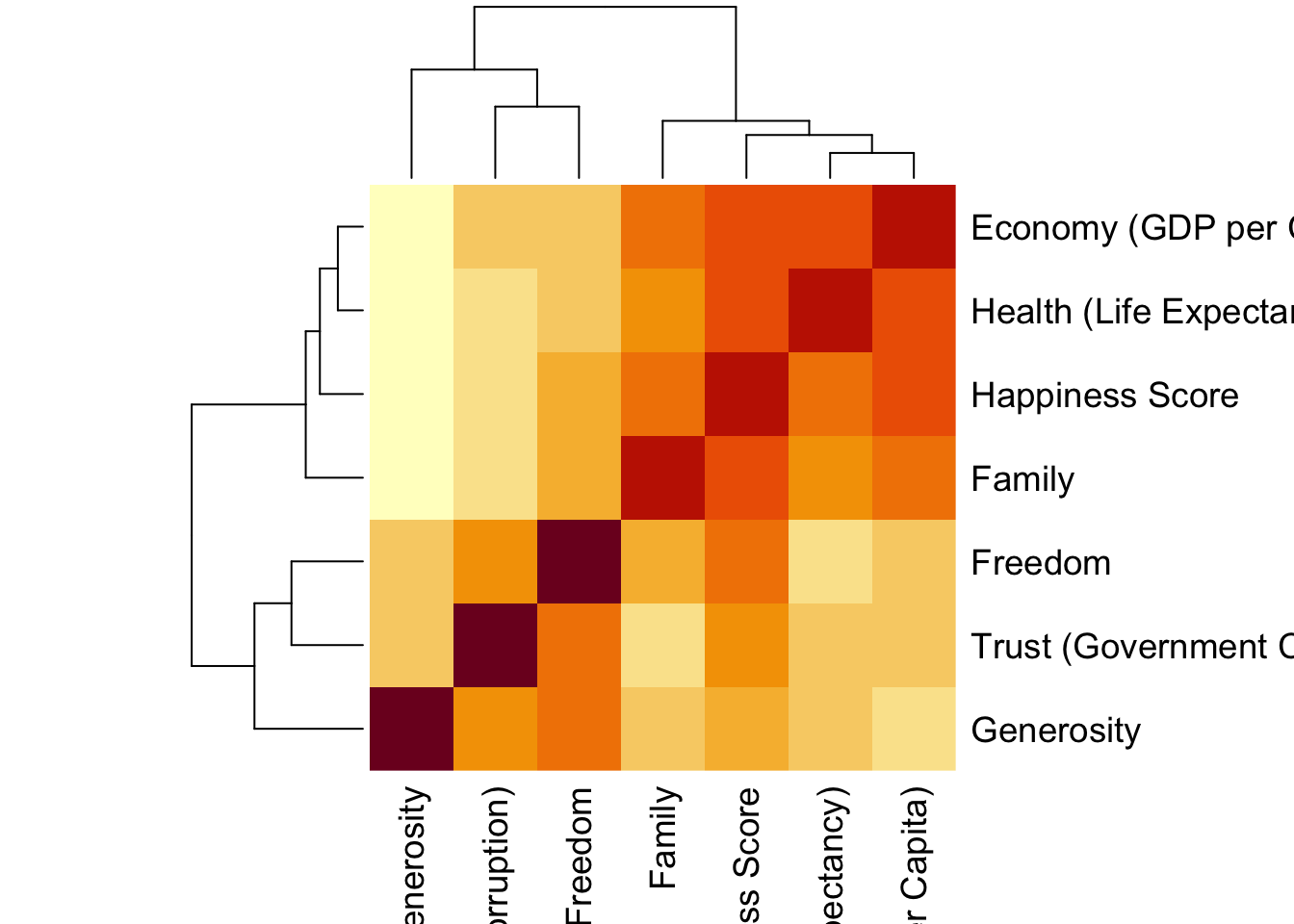
Корреляционные матрицы
# корреляция по простому
whr_tests %>%
select(c(`Happiness Score`:Generosity, -`Upper Confidence Interval`, -`Lower Confidence Interval`)) %>%
cor(method = "spearman") %>%
round(2) ## Happiness Score Economy (GDP per Capita) Family
## Happiness Score 1.00 0.81 0.76
## Economy (GDP per Capita) 0.81 1.00 0.70
## Family 0.76 0.70 1.00
## Health (Life Expectancy) 0.77 0.86 0.62
## Freedom 0.56 0.40 0.51
## Trust (Government Corruption) 0.31 0.22 0.18
## Generosity 0.15 0.00 0.12
## Health (Life Expectancy) Freedom
## Happiness Score 0.77 0.56
## Economy (GDP per Capita) 0.86 0.40
## Family 0.62 0.51
## Health (Life Expectancy) 1.00 0.35
## Freedom 0.35 1.00
## Trust (Government Corruption) 0.17 0.47
## Generosity 0.08 0.40
## Trust (Government Corruption) Generosity
## Happiness Score 0.31 0.15
## Economy (GDP per Capita) 0.22 0.00
## Family 0.18 0.12
## Health (Life Expectancy) 0.17 0.08
## Freedom 0.47 0.40
## Trust (Government Corruption) 1.00 0.25
## Generosity 0.25 1.00library("Hmisc")
whr_tests %>%
select(c(`Happiness Score`:Generosity, -`Upper Confidence Interval`, -`Lower Confidence Interval`)) %>%
as.matrix() %>%
rcorr() -> whr_cor
whr_cor$r## Happiness Score Economy (GDP per Capita)
## Happiness Score 1.0000000 0.79032202
## Economy (GDP per Capita) 0.7903220 1.00000000
## Family 0.7392516 0.66953969
## Health (Life Expectancy) 0.7653843 0.83706723
## Freedom 0.5668267 0.36228285
## Trust (Government Corruption) 0.4020322 0.29418478
## Generosity 0.1568478 -0.02553066
## Family Health (Life Expectancy) Freedom
## Happiness Score 0.73925158 0.76538433 0.5668267
## Economy (GDP per Capita) 0.66953969 0.83706723 0.3622828
## Family 1.00000000 0.58837678 0.4502082
## Health (Life Expectancy) 0.58837678 1.00000000 0.3411993
## Freedom 0.45020820 0.34119929 1.0000000
## Trust (Government Corruption) 0.21356094 0.24958329 0.5020540
## Generosity 0.08962885 0.07598731 0.3617513
## Trust (Government Corruption) Generosity
## Happiness Score 0.4020322 0.15684780
## Economy (GDP per Capita) 0.2941848 -0.02553066
## Family 0.2135609 0.08962885
## Health (Life Expectancy) 0.2495833 0.07598731
## Freedom 0.5020540 0.36175133
## Trust (Government Corruption) 1.0000000 0.30592986
## Generosity 0.3059299 1.00000000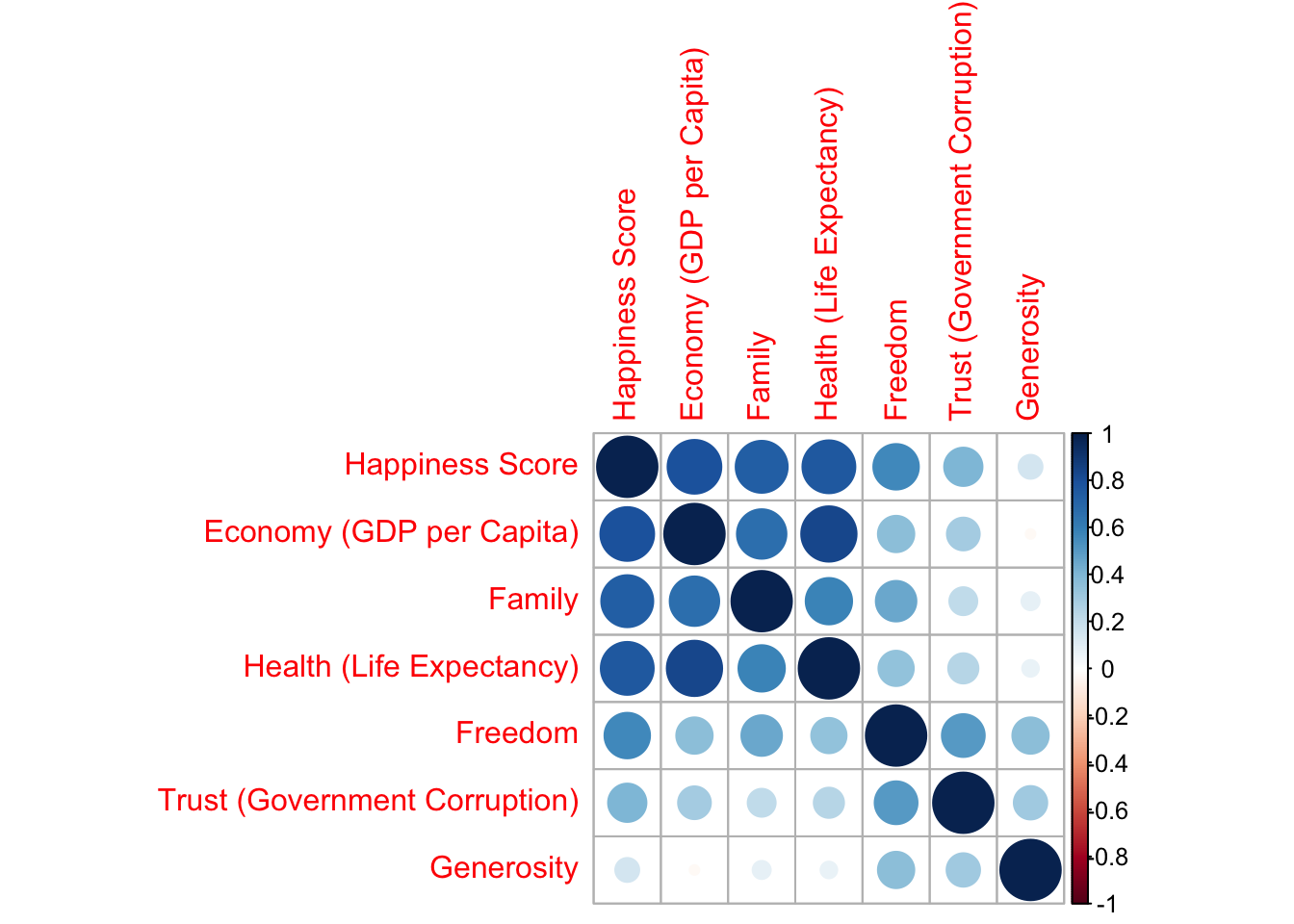
14.11.2 Т-тест
Теперь проверим гипотезу о том, что уровень счастья Happiness Score отличается в Восточной и Западной Европе. Для этого сначала нам нужно отфильтровать только те данные, которые соответствуют регионам Central and Eastern Europe и Western Europe. Это тот самый этап предобработки данных, когда прежде чем применять статистчиеские тесты, нам нужно подготовить данные.
whr_tests %>%
filter(Region == "Central and Eastern Europe" | Region == "Western Europe") -> whr_ttestИдем по алгоритму NHST: фомулируем нулевую и альтернативную гипотезы, выбираем уровень значимости, доходим до выбора статистического теста, и выбираем т-тест. Теперь проверяем допущения для т-теста
Для т-теста нам важно допущение, что ЗП распределена нормально или близко к нормальному (распределение в целом симметрично, нет особых выбросов). Проверим это.
# skimr::skim(whr_tests$`Happiness Score`)
whr_ttest %>%
ggplot(aes(x =`Happiness Score`)) +
geom_density(color = "#355C7D") +
theme_minimal()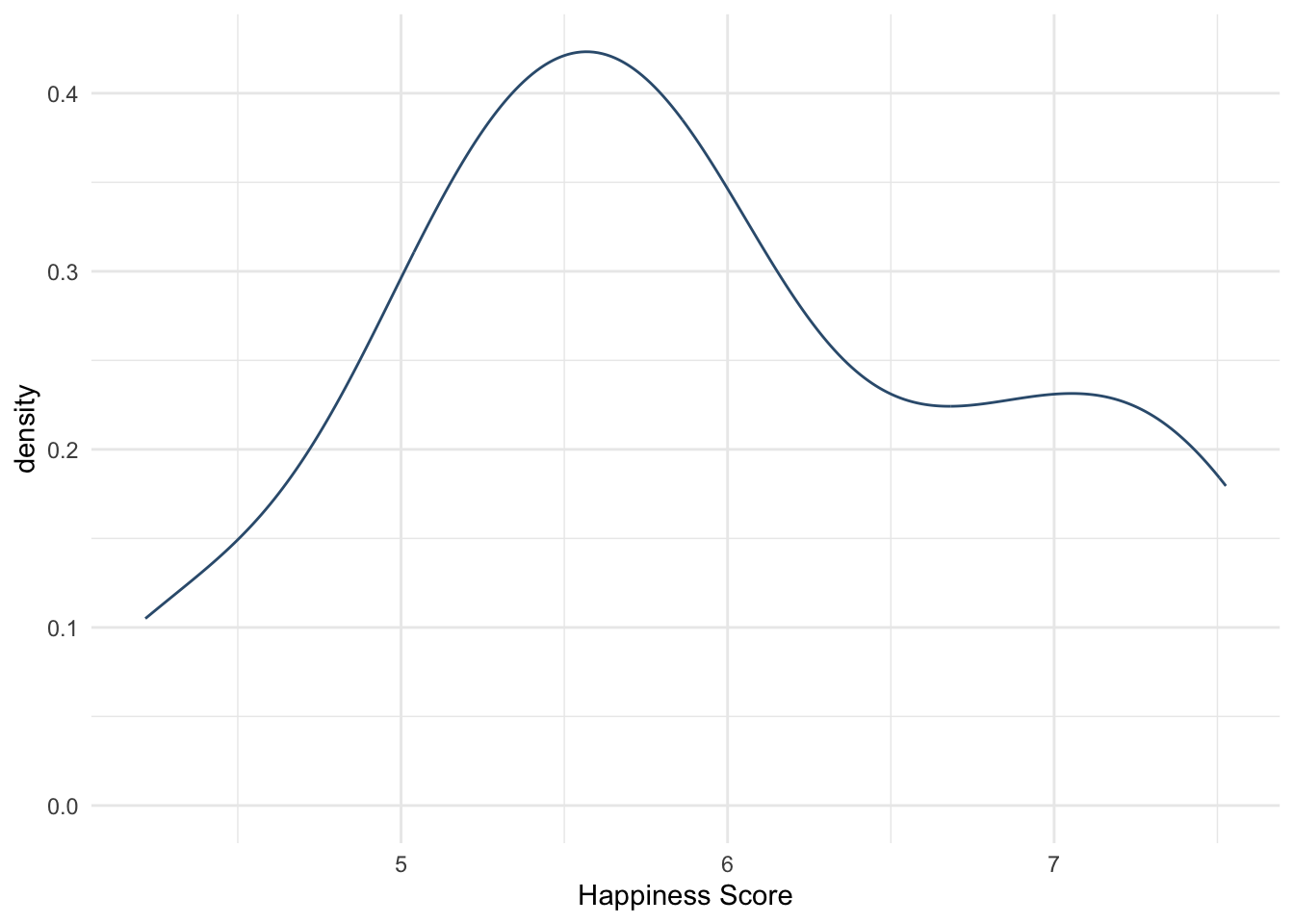
whr_ttest %>%
ggplot(aes(sample = `Happiness Score`)) +
stat_qq(color = "#355C7D") +
geom_qq_line() +
theme_minimal()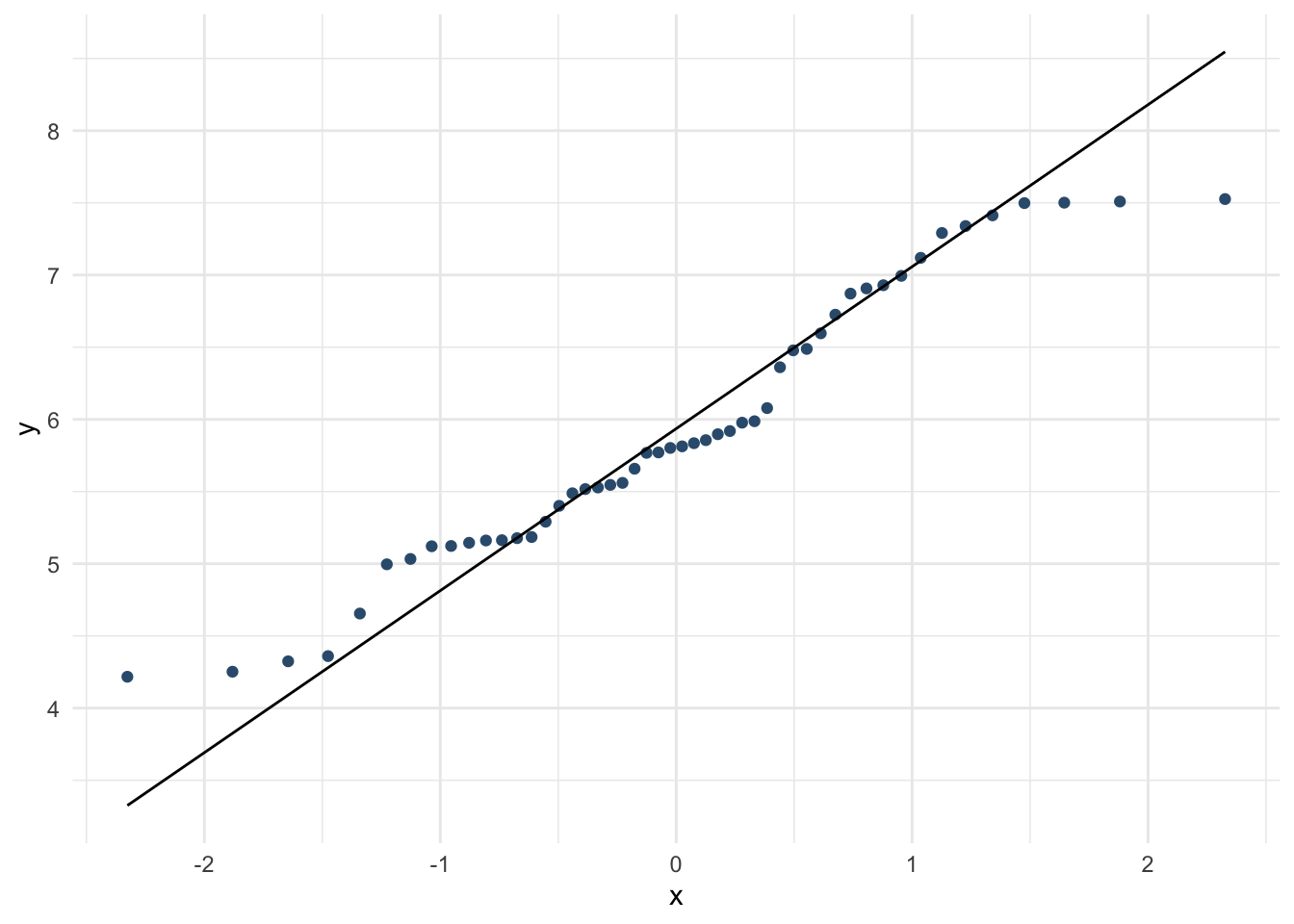
По этой картине в целом можем считать, что ЗП Happiness Score распределена близко к нормальному распределению. Значит, мы можем не использовать непараметрические аналоги т-теста и проводить самый обычный т-тест!
t.test(`Happiness Score` ~ Region, data = whr_ttest, alternative = "less", paired = FALSE, conf.level = 0.95)##
## Welch Two Sample t-test
##
## data: Happiness Score by Region
## t = -6.4412, df = 35.349, p-value = 0.00000009733
## alternative hypothesis: true difference in means between group Central and Eastern Europe and group Western Europe is less than 0
## 95 percent confidence interval:
## -Inf -0.9701413
## sample estimates:
## mean in group Central and Eastern Europe
## 5.370690
## mean in group Western Europe
## 6.685667t.test(`Happiness Score` ~ Region, data = whr_ttest, alternative = "two.sided", paired = FALSE, conf.level = 0.95)##
## Welch Two Sample t-test
##
## data: Happiness Score by Region
## t = -6.4412, df = 35.349, p-value = 0.0000001947
## alternative hypothesis: true difference in means between group Central and Eastern Europe and group Western Europe is not equal to 0
## 95 percent confidence interval:
## -1.7292798 -0.9006742
## sample estimates:
## mean in group Central and Eastern Europe
## 5.370690
## mean in group Western Europe
## 6.685667Аргумент alternative обозначает, какова наша альтернативная гипотеза (противоположная нулевой): что средние в группых просто не равны или что среднее в одной из групп меньше или больше, чем в другой. Аргумент paired указывает, нужно ли проводить зависимый т-тест (когда мы используем одну и ту же выборку и делаем на ней несколько измерений). В данном случае, у нас независимые выборки, и зависимый т-тест не нужен.
Как проинтерпретировать эти результаты? Первое, на что мы смотрим – это p-value (колонка Pr(F)). Если оно меньше установленного уровня \(\alpha\), то мы говорим, что отвергаем нулевую гипотезу, и мы получили статистически значимые резличия. Если p-value больше или равно \(\alpha\) – у нас недостаточно свидетельств в пользу альтернативной гипотезы, и мы говорим, что не отвергаем нулевую гипотезу.
Чем хороша форма записи через %>% – мы можем сразу внутри одного пайпа и отфильтровать данные, и сделать т-тест! На том же самом примере, только теперь сразу отфильтруем данные и сделаем т-тест на отфильтрованных данных, без создания отдельного датасета whr_ttest:
whr_tests %>%
filter(Region == "Central and Eastern Europe" | Region == "Western Europe") %>%
t.test(`Happiness Score` ~ Region, data = ., alternative = "less", paired = FALSE, conf.level = 0.95) # ставим точку вместо названия датасета##
## Welch Two Sample t-test
##
## data: Happiness Score by Region
## t = -6.4412, df = 35.349, p-value = 0.00000009733
## alternative hypothesis: true difference in means between group Central and Eastern Europe and group Western Europe is less than 0
## 95 percent confidence interval:
## -Inf -0.9701413
## sample estimates:
## mean in group Central and Eastern Europe
## 5.370690
## mean in group Western Europe
## 6.685667Обратите внимание – в функции t.test данные стоят не на первом месте, как нам нужно для того, чтобы использовать нотацию пайпа. Но это довольно просто решается: в любой функции, чтобы использовать ее внутри пайпа, нужно поставить точку в том месте, куда мы хотим передать результат выполнения предыдущей строки пайпа.
Иногда бывает проще все-таки сделать больше действий, но последовательно, поэтому может пригодиться знать и другой вариант записи т-теста и его непараметрических аналогов – не через указание переменных из данных (обратите внимание – мы эксплицитно задавали аргумент data), а без указания данных, просто передав ему два вектора (я редко использую такой формат записи, но не потому, что он хуже – я это делаю для экономии времени, и чтобы не запутаться в созданных мной во время работы над учебником переменных):
# Фильтруем только те регионы, которые будем проверять
whr_tests %>%
filter(Region == "Central and Eastern Europe") %>%
select(`Happiness Score`) %>%
pull() -> whr_tests_CEE
whr_tests %>%
filter(Region == "Western Europe") %>%
select(`Happiness Score`) %>%
pull() -> whr_tests_WE
var(whr_tests_CEE)## [1] 0.3485667## [1] 0.6228212##
## Welch Two Sample t-test
##
## data: whr_tests_CEE and whr_tests_WE
## t = -6.4412, df = 35.349, p-value = 0.00000009733
## alternative hypothesis: true difference in means is less than 0
## 95 percent confidence interval:
## -Inf -0.9701413
## sample estimates:
## mean of x mean of y
## 5.370690 6.685667##
## Welch Two Sample t-test
##
## data: whr_tests_CEE and whr_tests_WE
## t = -6.4412, df = 35.349, p-value = 0.00000009733
## alternative hypothesis: true difference in means is less than 0
## 95 percent confidence interval:
## -Inf -0.9701413
## sample estimates:
## mean of x mean of y
## 5.370690 6.685667##
## Welch Two Sample t-test
##
## data: whr_tests_CEE and whr_tests_WE
## t = -6.4412, df = 35.349, p-value = 0.0000001947
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## -1.7292798 -0.9006742
## sample estimates:
## mean of x mean of y
## 5.370690 6.685667Построим визуализации
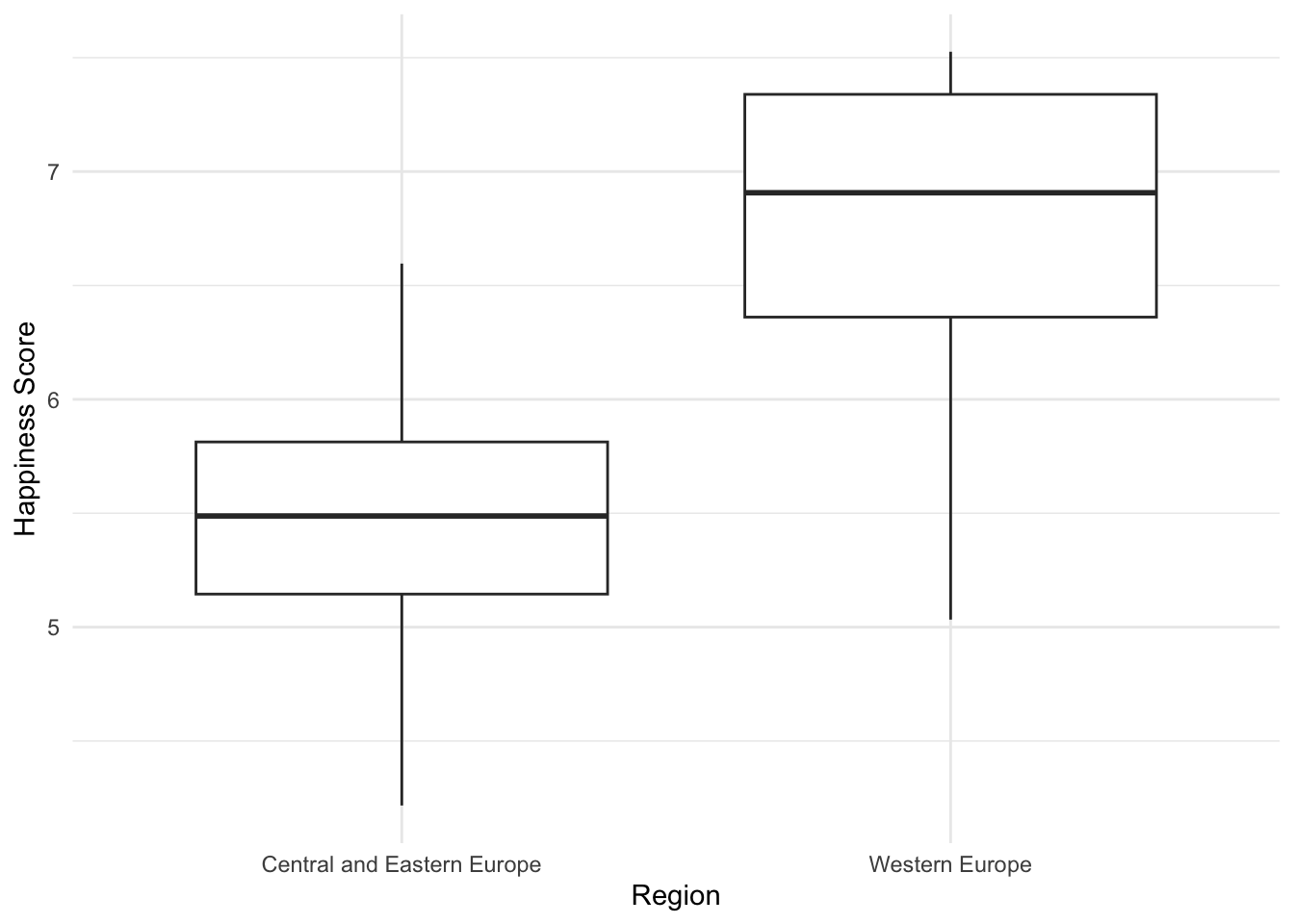
# install.packages("viridis")
# install.packages("wesanderson")
library(viridis)
library(wesanderson)
whr_ttest %>%
ggplot(aes(x=Region, y = `Happiness Score`, fill = Region)) +
geom_boxplot() +
theme_minimal() +
scale_fill_viridis_d()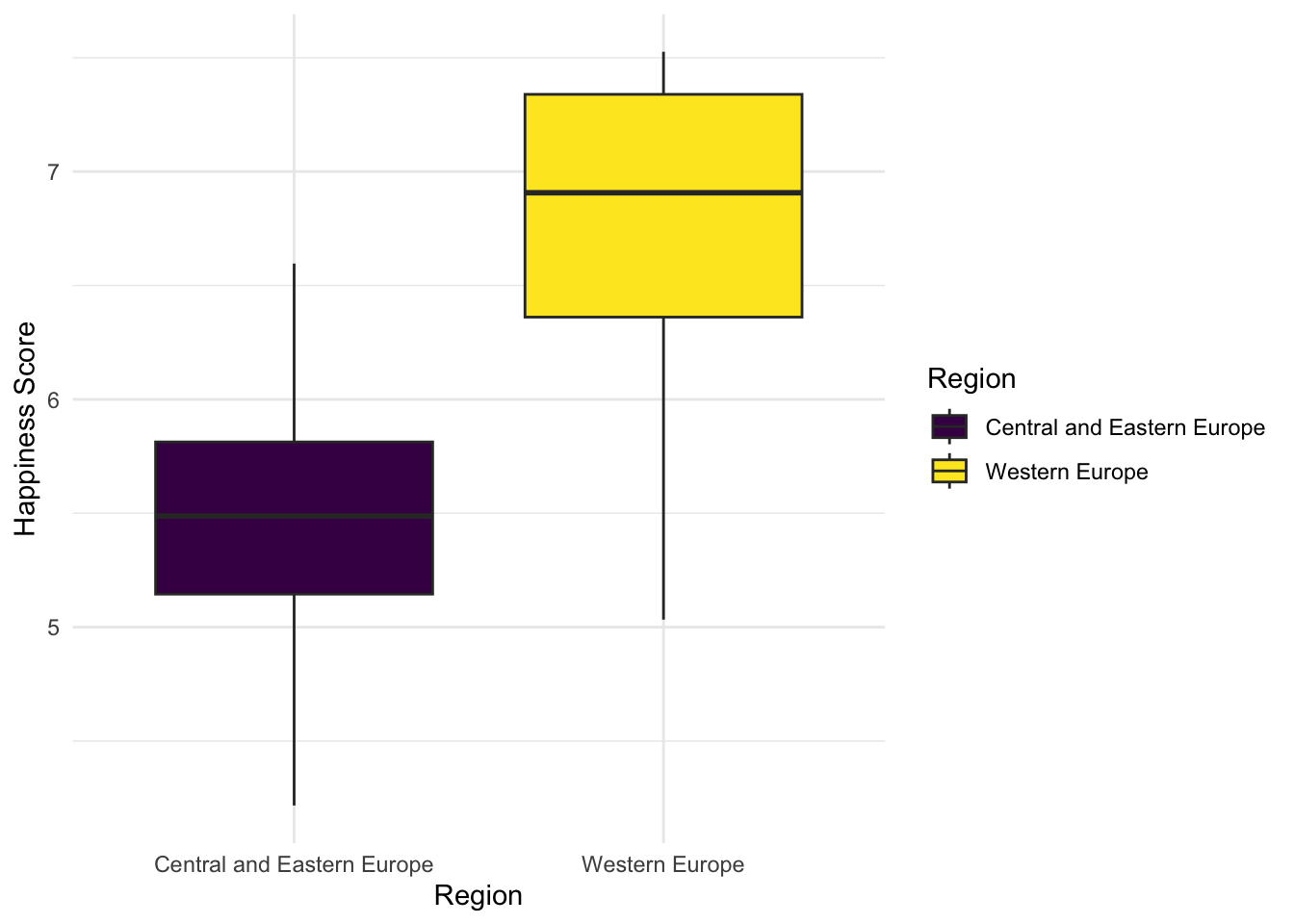
whr_ttest %>%
ggplot(aes(x=Region, y = `Happiness Score`, fill = Region)) +
geom_boxplot() +
theme_minimal() +
scale_fill_manual(values = wes_palette("Moonrise3"))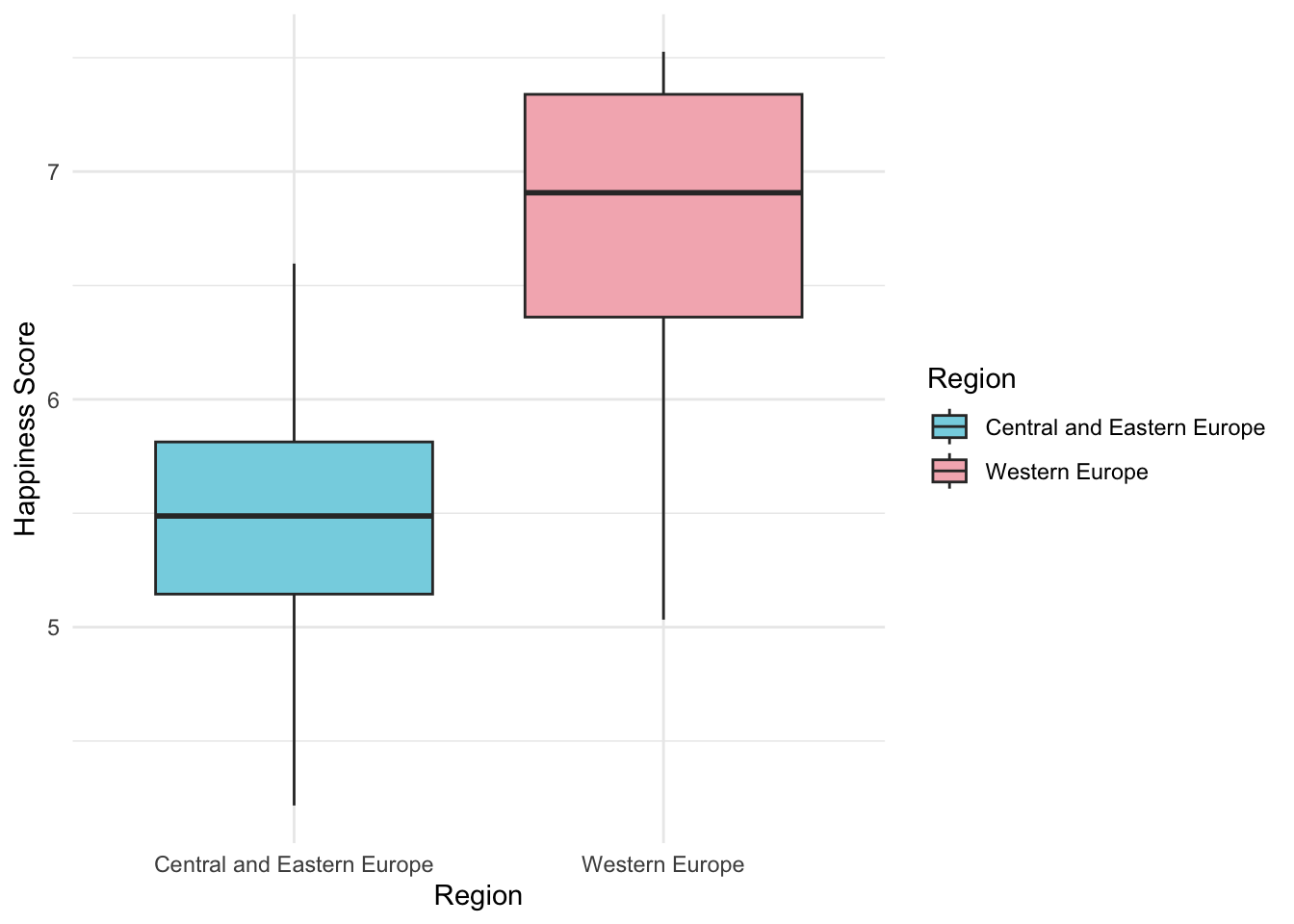
whr_ttest %>%
ggplot(aes(x=Region, y = `Happiness Score`, fill = Region)) +
geom_violin() +
theme_minimal() +
scale_fill_manual(values = wes_palette("Moonrise3"))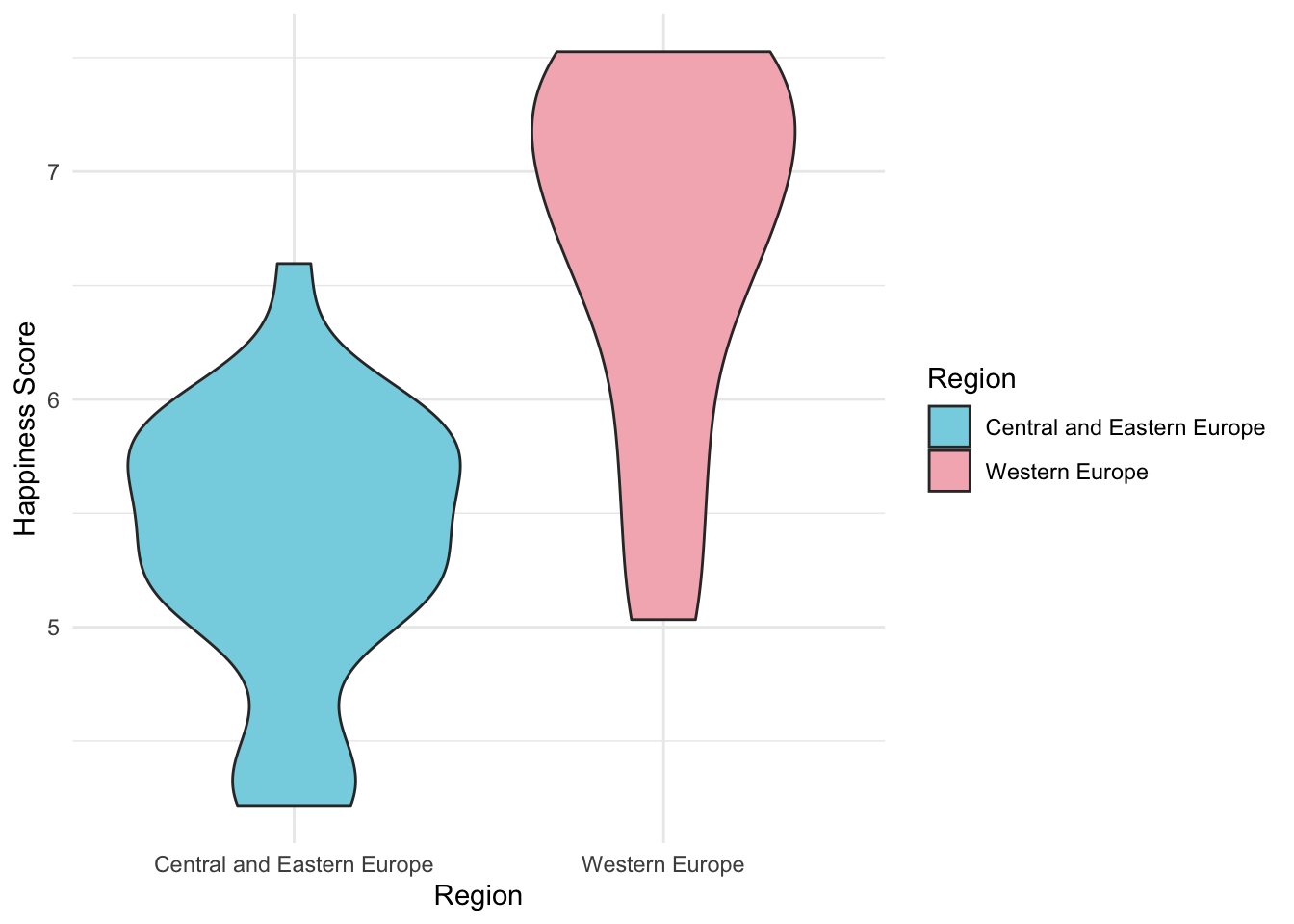
Непараметрические аналоги т-теста
Что делать, если бы наши допущения о предположении нормальности ЗП не оправдались? Если бы в распределении были бы явные выбросы, они было бы сильно не симметричным и скошенным? Тогда нам нужно было бы проводить непараметрические аналоги т-теста – тест Уилкоксона или Манна-Уитни. Разберем их на примере проверки, что показатель социальной поддержки Family отличается в этих регионах (на самом деле, в реальности тут скорее всего вполне можно было бы провести обычный т-тест – но более кривых переменных в этих данных не нашлось, поэтому смотреть использование непараметрических аналогов будем на них.
whr_tests %>%
ggplot(aes(sample = Family)) +
stat_qq(color = "#355C7D") +
geom_qq_line() +
theme_minimal()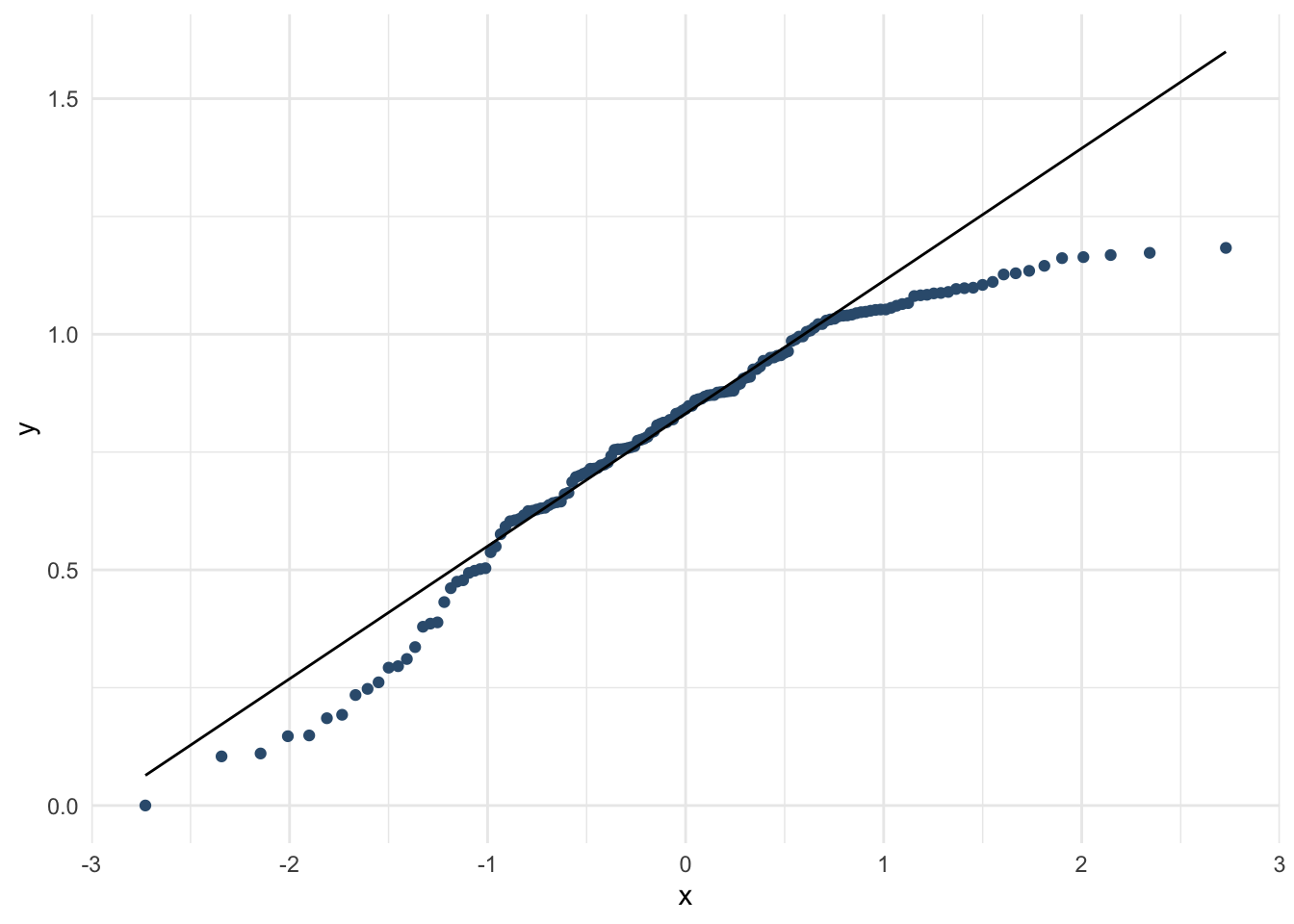
# Все то же самое -- но функция называется не t.test(), a wilcox.test()
wilcox.test(whr_ttest$Family ~ whr_ttest$Region, alternative = "less", paired = FALSE, conf.level = 0.95)##
## Wilcoxon rank sum exact test
##
## data: whr_ttest$Family by whr_ttest$Region
## W = 127, p-value = 0.0001618
## alternative hypothesis: true location shift is less than 0whr_ttest %>%
ggplot(aes(x=Region, y = Family, fill = Region)) +
geom_boxplot() +
theme_minimal() +
scale_fill_manual(values = wes_palette("Moonrise3"))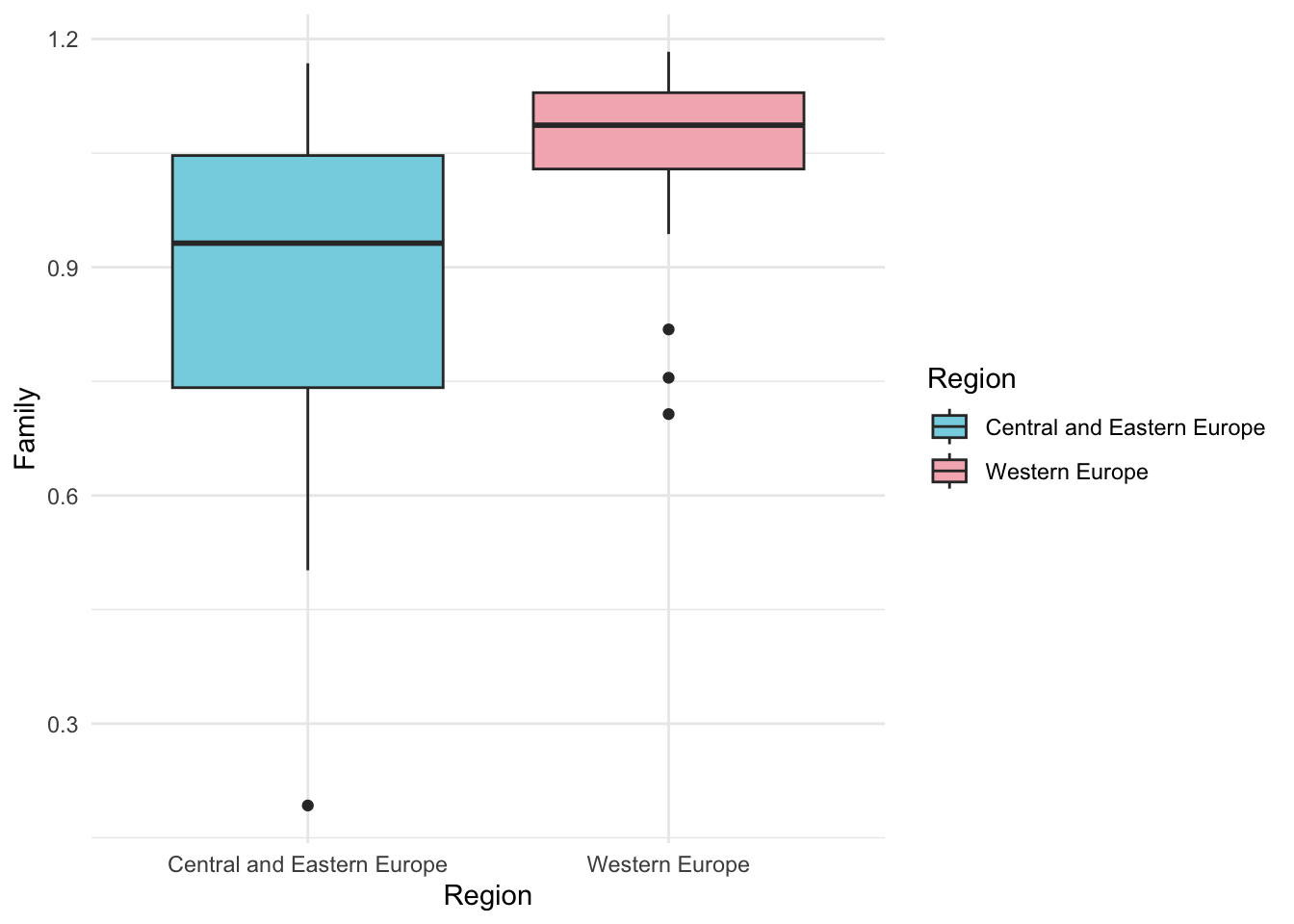
14.12 Задания после семинара 5
Мы уже освоили предобработку данных, и теперь совсем взрослые – можем взять менее чистенький, расширенный датасет того же World Happiness Report за 2019 https://github.com/elenary/StatsForDA/blob/main/Chapter2OnlineData2019.xls?raw=true, а здесь можно почитать пододробнее про данные https://s3.amazonaws.com/happiness-report/2019/WHR19_Ch2A_Appendix1.pdf (кстати, этот док, судя по всему, тоже сверстан в R).
(Если вы работаете в R) Чтобы было удобнее с ним работать для проверки гипотез, я сделала его предобработку – при повторении попробуйте ее разобрать, что делает каждая строчка? Показалось ли что-то новым?
whr <- read_csv("2016.csv")
whr_2019 <- readxl::read_xls("Chapter2OnlineData2019.xls")
whr_2019 %>%
select(`Country name`:`Negative affect`) -> whr_2019
whr %>%
select(Country:`Happiness Score`) %>%
right_join(whr_2019, by = c("Country" = "Country name"), multiple = "last") %>%
mutate("top20" = ifelse(`Happiness Rank`<=20, "hehe", "not hehe"),
"mean_position" = ifelse(`Happiness Score`>= mean(`Happiness Score`, na.rm = TRUE), "upper", "lower")) -> whr_tests_hw
# View(whr_tests)(Если вы работаете в Jamovi, ипользуйте любые данные – старые за 2016 год или новые за 2019)
На полученном датасете
whr_tests_hwпроведите полностью по всему алгоритму NHST хотя бы один корреляционные тест: выберете подходящие переменные, сформулируйте гипотезу, сформулируйте \(H_0\) и \(H_1\), выберете уровень \(\alpha\), предобработайте данные, если нужно, и проведите корреляционный тест на выбранном уровне значимости. Проинтерпретируйте результаты: подтвердилась ли гипотеза?На полученном датасете
whr_tests_hwпроведите полностью по всему алгоритму NHST хотя бы один т-тест или его непараметрический аналог: выберете подходящие переменные, сформулируйте гипотезу, сформулируйте \(H_0\) и \(H_1\), выберете уровень \(\alpha\), определите, зависимые или независимые выборки, предобработайте данные, если нужно, и проведите тест сравнения средних на выбранном уровне значимости. Проинтерпретируйте результаты: подтвердилась ли гипотеза?
14.13 Проверка гипоте-2: ANOVA и линейная регрессия
14.13.1 ANOVA (дисперсионный анализ)
Я хочу внести чуть разнообразия в наши данные, поэтому нашла еще одну табличку, касающуюся World Happiness Report, можно почитать пододробнее здесь (кстати, этот док, судя по всему, тоже сверстан в R).
Примерно так может выглядеть предобработка реальных (не самых чистых и кривых) данных: я объединяю две таблички (табличка за 2016 год и новая табличка за 2019 год) с помощью функции right_join (это значит, что я к правой табличке присоединяю левую, а все то, что осталось в левой не подошедшее к правой – не берется) из семейства join, переименовые колонки и заменяю пробелы на них на нижнее подчеркивание с помощью функции rename_with, отбираю только интересующие меня колонки с помощью функции select, создаю новые переменные, которые мы уже создавали ранее в домашках, с помощью функции mutate и сохраняю результат в новую табличку в датасет whr_tests_hw
whr_2019 <- readxl::read_xls("Chapter2OnlineData2019.xls")
whr <- read_csv("2016.csv")
whr_2019 %>%
rename_with(~ gsub(" ", "_", .), .cols = everything()) %>%
select(Country_name:Negative_affect) %>%
filter(Year <= 2016) -> whr_2019
whr %>%
rename_with(~ gsub(" ", "_", .), .cols = everything()) %>%
select(Country, Happiness_Rank, Happiness_Score) %>%
right_join(whr_2019, by = join_by(Country == Country_name), multiple = "last") -> tmp
whr %>%
select(Country:Region) %>%
right_join(tmp, by = join_by(Country == Country), multiple = "all") %>%
mutate("top20" = ifelse(Happiness_Rank<=20, "hehe", "not hehe"),
"mean_position" = ifelse(Happiness_Score>= mean(Happiness_Score, na.rm = TRUE), "upper", "lower")) -> whr_tests_hwРезультат этой предобраотк я так же с помощью R и функции write_csv() выгрузила в отдельный файл https://raw.githubusercontent.com/elenary/StatsForDA/main/whr_tests_hw.csv
До этого мы проверяли гипотезу о том, что Happiness Score различаеся в двух регионах: Западаной и Восточной и Центральной Европе. А если я хочу проверить, различаются ли статистически значимо уровень счастья в трех регионах – Западаной и Восточной и Центральной Европе и в Латинском Америке? Снова обращаемся к изученным нами в прошлом семестре статистическим критериям, всопминаем каринку с деревом выбора статистических тестов https://miro.com/app/board/uXjVOxmKhr8=/. Если у нас ЗП количественная, НП категориальная / категориальные, и нужно провести 3 сравнения и больше – то мы переходим от т-теста к ANOVA (дисперсионному анализу).
Я буду периодически придерживаться формы записи кода, когда я внутри одного пайпа делаю сразу все – и фильрацию, и построение графиков или расчет теста, но не забывае, что прежде чем писать все вместе, нужно убедиться, что каждая строчка – работает. И может быть удобнее на первых порах создавать побольше переменных и записывать туда результаты фильтрации, а потом уже использовать эту переменную – так будет проще дебажить код. Например, можно сначала отфильтровать данные и записать их в новый датасет (иногда бывает, что без этой формы записи не обойтись)
whr_tests_hw %>%
filter(Region == "Central and Eastern Europe" | Region == "Western Europe" | Region == "Latin America and Caribbean") %>%
filter(Year == "2016") -> whr_anovaВспоминаем допущения для АНОВЫ
Первое – ЗП должна быть распределена близко к нормальному распределению.
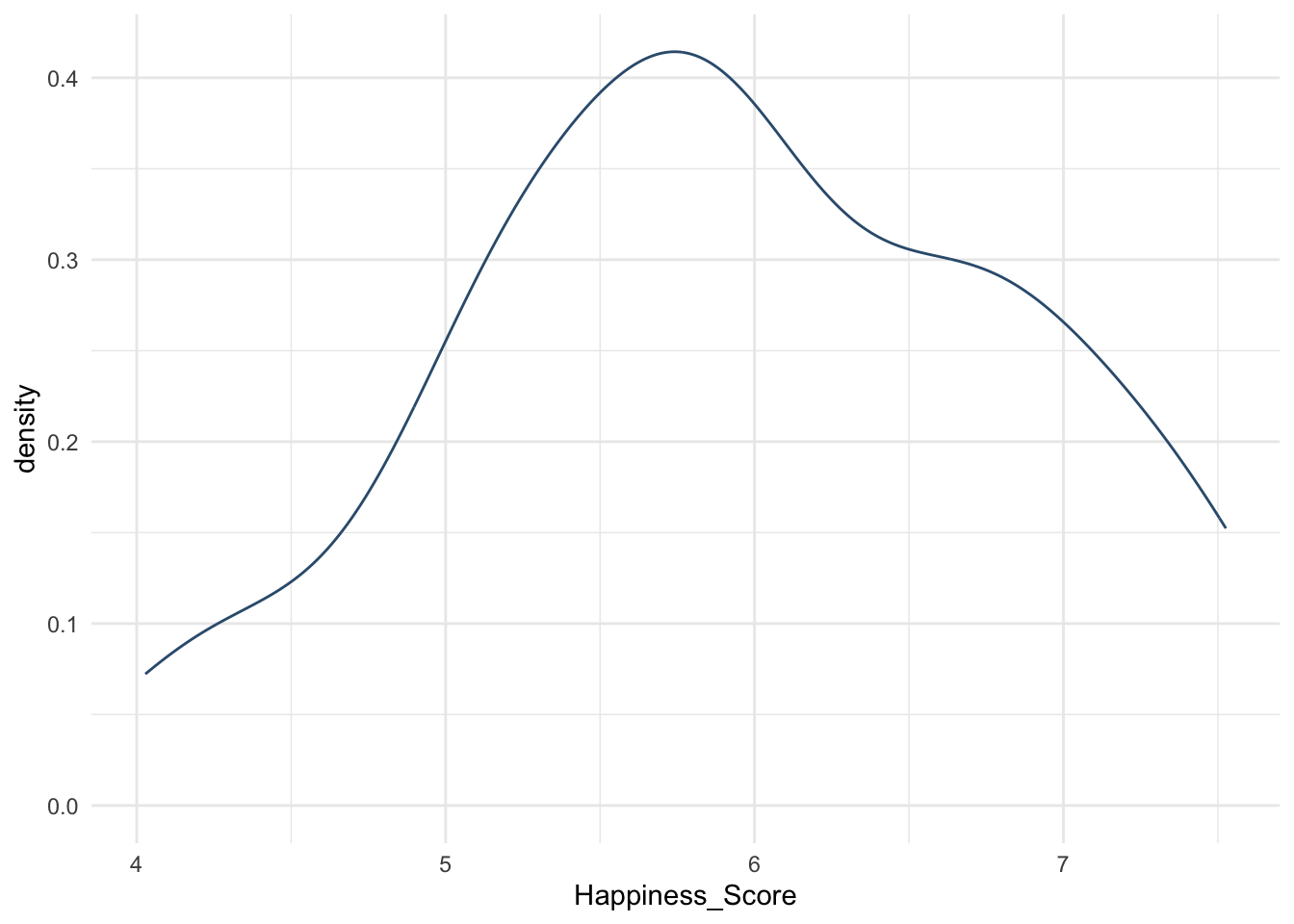
whr_anova %>%
ggplot(aes(sample = Happiness_Score)) +
stat_qq(color = "#355C7D") +
geom_qq_line() +
theme_minimal()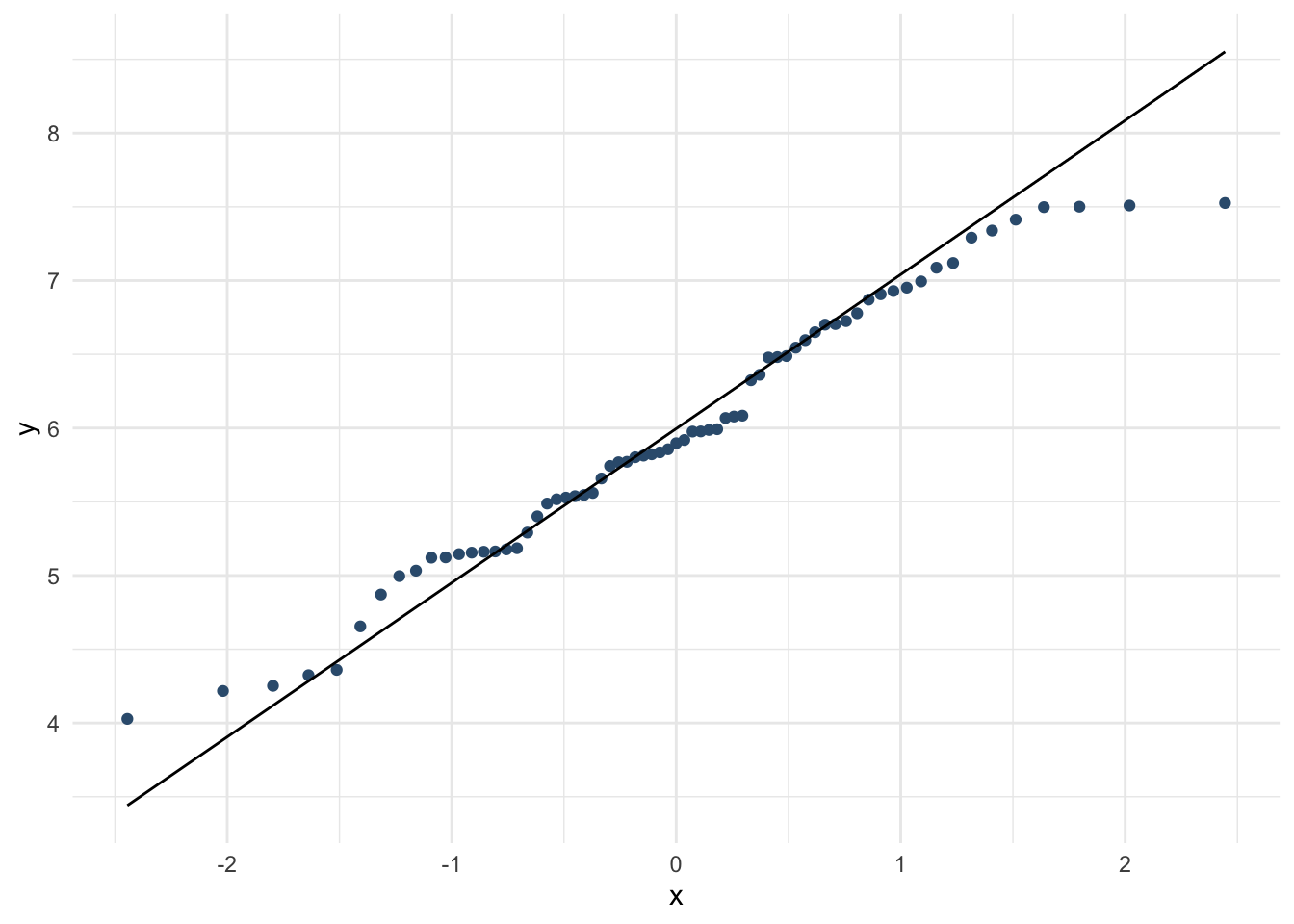
Допустим, это похоже на нормальное распредедление.
Второе допущение – гомогенность (гомоскедастичность) дисперсий. Дисперсии должны быть одинаковы в наших группах. Если они будут разными – это плохо, и нам придется использовать непараметрические аналоги ANOVA. Гомогенность дисперсий проверяется с помощью Levene’s Test. Обратите внимание: здесь мы заинтересованы в получении НЕзначимого результата – потому что если проверка дала значимый результат, то диперсии в группах различаются, а это не ок. Нам понадобится фунция leveneTest из пакета car
options(scipen = 999) # сначала отключим форму записи чисел с большим количество нулей через экспоненту
# install.packages("car")
library(car)
leveneTest(Happiness_Score ~ Region, data = whr_anova)## Warning in leveneTest.default(y = y, group = group, ...): group coerced to
## factor.## Levene's Test for Homogeneity of Variance (center = median)
## Df F value Pr(>F)
## group 2 0.7143 0.4933
## 66Смотрми на p-value: оно не значимо, ура! Значит, мы соблюли все допущения, и можем спокойно использовать анову. Мы попробуем построить ее двумя способами: с помощью стандартной функции aov и с помощью более функции ezANOVA из пакета ez с более понятным синтаксисом, но более придирчивой и менее стабильной.
aov_model1 <- aov(Happiness_Score ~ Region, data = whr_anova) #выполняем АНОВУ
summary(aov_model1) #выводим табличку АНОВЫ## Df Sum Sq Mean Sq F value Pr(>F)
## Region 2 21.40 10.698 21.37 0.0000000697 ***
## Residuals 66 33.04 0.501
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Как проинтерпретировать эти результаты? Первое, на что мы смотрим – это p-value (колонка Pr(F)). Если оно меньше установленного уровня \(\alpha\), то мы говорим, что отвергаем нулевую гипотезу, и мы получили статистически значимые резличия. Если p-value больше или равно \(\alpha\) – у нас недостаточно свидетельств в пользу альтернативной гипотезы, и мы говорим, что не отвергаем нулевую гипотезу.
Второй вариант построения этого же анализа с помощью функции ezANOVA. Она, кстати, сразу делает Levene’s test, поэтому у нас две выдачи.
# install.packages("ez")
library(ez)
whr_anova %>%
ezANOVA(., Happiness_Score, wid = Country, between = Region)## Warning: Converting "Country" to factor for ANOVA.## Warning: Converting "Region" to factor for ANOVA.## Warning: Data is unbalanced (unequal N per group). Make sure you specified a
## well-considered value for the type argument to ezANOVA().## $ANOVA
## Effect DFn DFd F p p<.05 ges
## 1 Region 2 66 21.37266 0.000000069727 * 0.3930773
##
## $`Levene's Test for Homogeneity of Variance`
## DFn DFd SSn SSd F p p<.05
## 1 2 66 0.3066018 14.16483 0.7142945 0.4932823Если мы сравним результаты – они будут точно такими же, только вторая функция в колонке ges выдает еще размер эффекта! Это eta squared \(\eta^2\), метрика размера размера эффекта для ANOVA, которую вы так или иначе использовали в домашнем задании в прошлом курсе. Мы видим, что эффект, который мы получили, довольно большой!
Можем посчитать его и отдельно для предыдущей таблички с помощью функции пакета effectsize
## # Effect Size for ANOVA
##
## Parameter | Eta2 | 95% CI
## -------------------------------
## Region | 0.39 | [0.24, 1.00]
##
## - One-sided CIs: upper bound fixed at [1.00].Значение будет тем же самым, что и в колонке ges вывода ezANOVA.
Визуализируем результаты. Чаще всего для визуализации ANOVA используются боксплоты или вайолин плоты
whr_anova %>%
ggplot(aes(x=Region, y = Happiness_Score, fill = Region)) +
geom_boxplot() +
theme_minimal() +
scale_fill_manual(values = wes_palette("FantasticFox1"))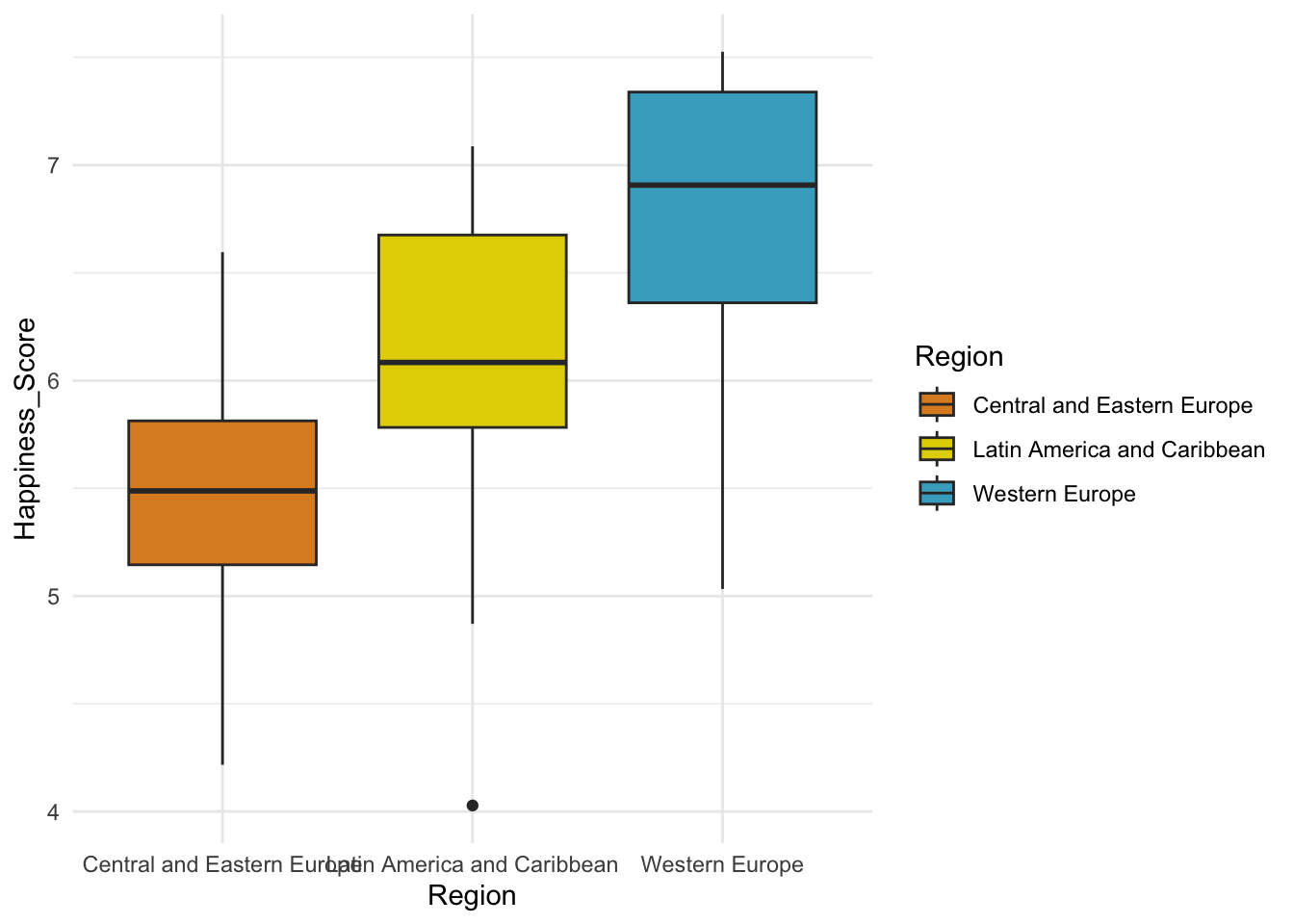 Или же часто можно встретить графики, на которых отображены только средние
Или же часто можно встретить графики, на которых отображены только средние
whr_anova %>%
ggplot(aes(x=Region, y = Happiness_Score, color = Region, group = 1)) +
stat_summary(fun = mean, geom = 'point') +
stat_summary(fun = mean, geom = 'line') +
stat_summary(fun.data = mean_cl_boot, geom = 'errorbar') +
theme_minimal() +
scale_color_manual(values = wes_palette("FantasticFox1"))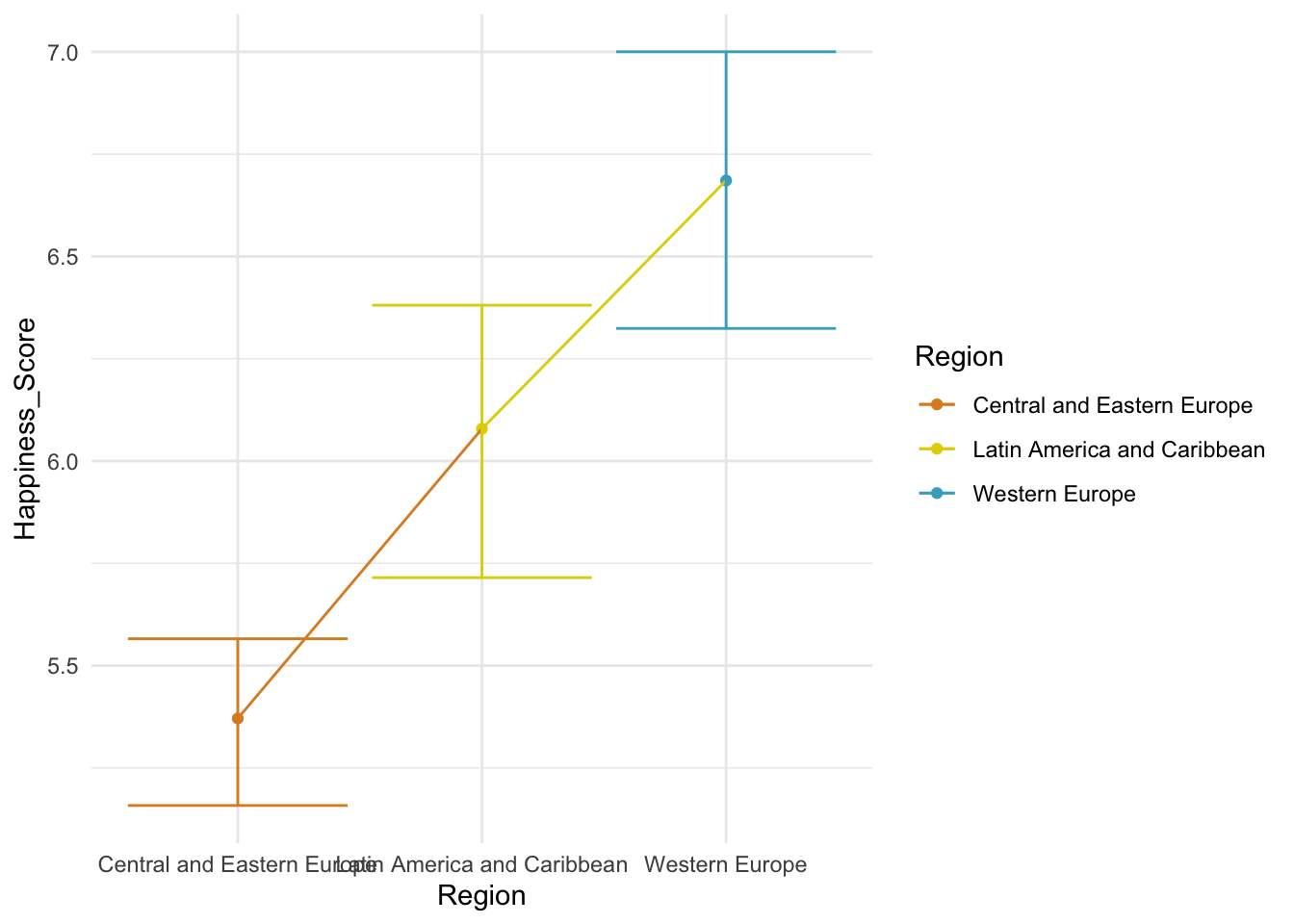
Мы узнали, что ANOVA значима, то есть статистически значимые различия между этими тремя регионами. А как узнать, какие именно регионы вносят значимость? Может ли такое быть, чтоо значимость обеспечивается одним сильно отличающимся от других регионом, в то время как два других не отличаются? Может. Чтобы узнать это, нужно провести пост-хок тесты.
14.13.1.1 Пост-хоки
Пост-хоки представляют собой попарное множественное сравнение всего со всем. Вспоминаем, что когда мы так делаем – мы рикуем получить статистчиески значимый результат чисто по случайности, потому что очень растет вероятность ошибки первого рода, и нужны поправи на множественные сравнения. Сделать пост=хок анализ можно например помощью встроенных функций TukeyHSD или pairwise.t.test
## Tukey multiple comparisons of means
## 95% family-wise confidence level
##
## Fit: aov(formula = Happiness_Score ~ Region, data = whr_anova)
##
## $Region
## diff lwr
## Latin America and Caribbean-Central and Eastern Europe 0.7082577 0.20757381
## Western Europe-Central and Eastern Europe 1.3149770 0.82891110
## Western Europe-Latin America and Caribbean 0.6067193 0.06961039
## upr p adj
## Latin America and Caribbean-Central and Eastern Europe 1.208942 0.0033334
## Western Europe-Central and Eastern Europe 1.801043 0.0000000
## Western Europe-Latin America and Caribbean 1.143828 0.0230915##
## Pairwise comparisons using t tests with pooled SD
##
## data: whr_anova$Happiness_Score and whr_anova$Region
##
## Central and Eastern Europe
## Latin America and Caribbean 0.0035
## Western Europe 0.000000039
## Latin America and Caribbean
## Latin America and Caribbean -
## Western Europe 0.0258
##
## P value adjustment method: bonferroni14.13.1.2 Непераметрические аналоги ANOVA
Если наша переменная имеет значительные выбросы, не прошла проверку на нормальность, и дисперсии в группах оказались статистически значимо разные – значит, мы не можем применять ANOVA. Что делаеть? Проводить аналог ANOVA, тест Краскелла-Уоллиса. Покажу его на тех же данных, которые мы брали для ANOVA, где смотрели разный уровень счастья по регионам.
##
## Kruskal-Wallis rank sum test
##
## data: Happiness_Score by Region
## Kruskal-Wallis chi-squared = 26.36, df = 2, p-value = 0.00000188814.13.1.3 Многофакторная ANOVA
Мы проверили гипотезу с только одной НП – регион. А если моя гипотеза касается нескольких факторов? Например, хочу проверить гипотезу, что на переменную Life_Ladder (аналог Happiness Score, показывает результаты опроса, где находятся респонденты по уровню счастья в виде лестницы, у которой 10 ступенек) влияет и регион, и год.
Я вернусь к изначальному датасету и уберу фильтрацию по году.
Все то же самое – сначала проверим допущения.
whr_tests_hw %>%
filter(Region == "Central and Eastern Europe" |
Region == "Western Europe" |
Region == "Latin America and Caribbean") %>%
ggplot(aes(x = Life_Ladder)) +
geom_density(color = "#355C7D") +
theme_minimal()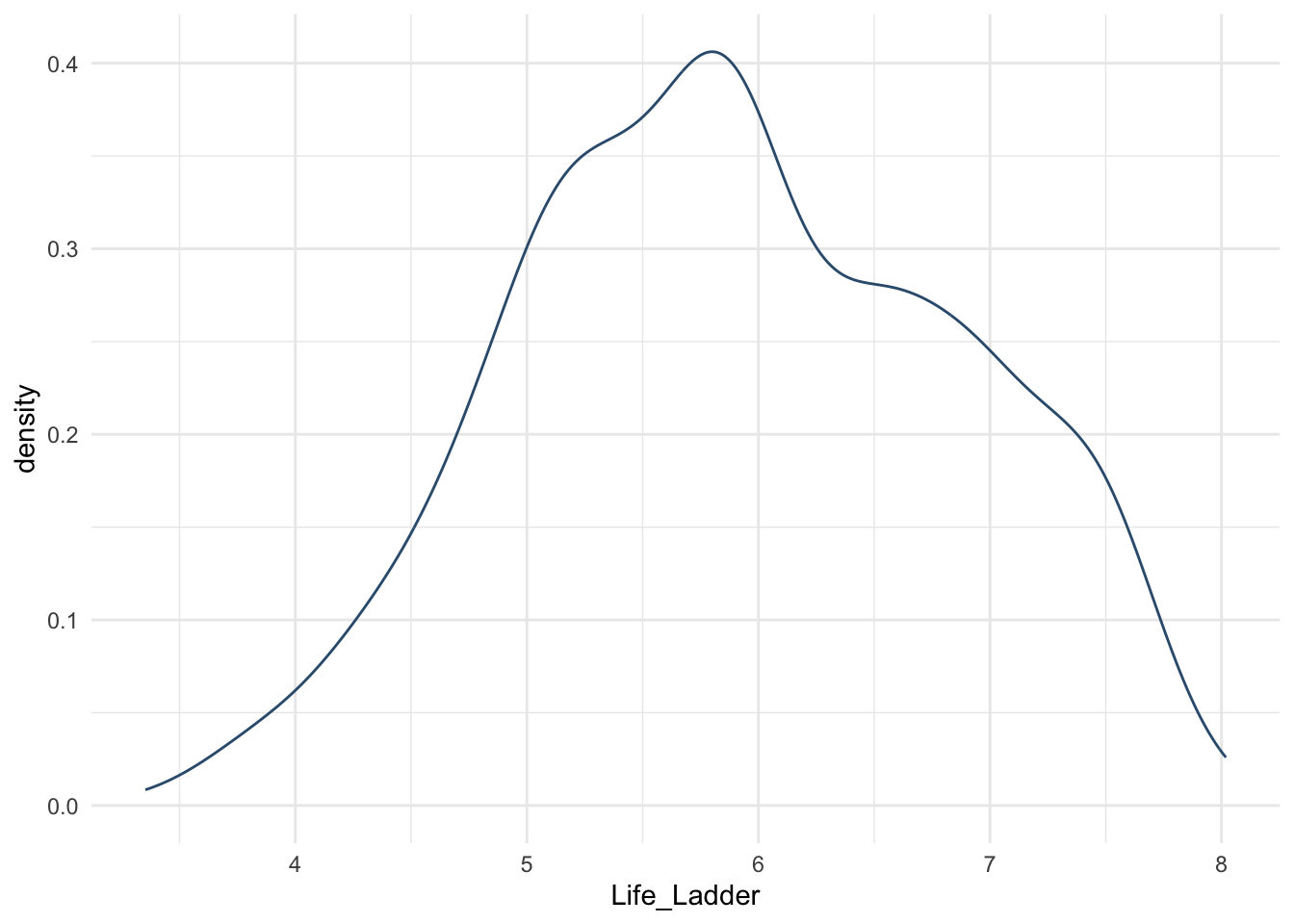
whr_tests_hw %>%
filter(Region == "Central and Eastern Europe" |
Region == "Western Europe" |
Region == "Latin America and Caribbean") %>%
ggplot(aes(sample = Life_Ladder)) +
stat_qq(color = "#355C7D") +
geom_qq_line() +
theme_minimal()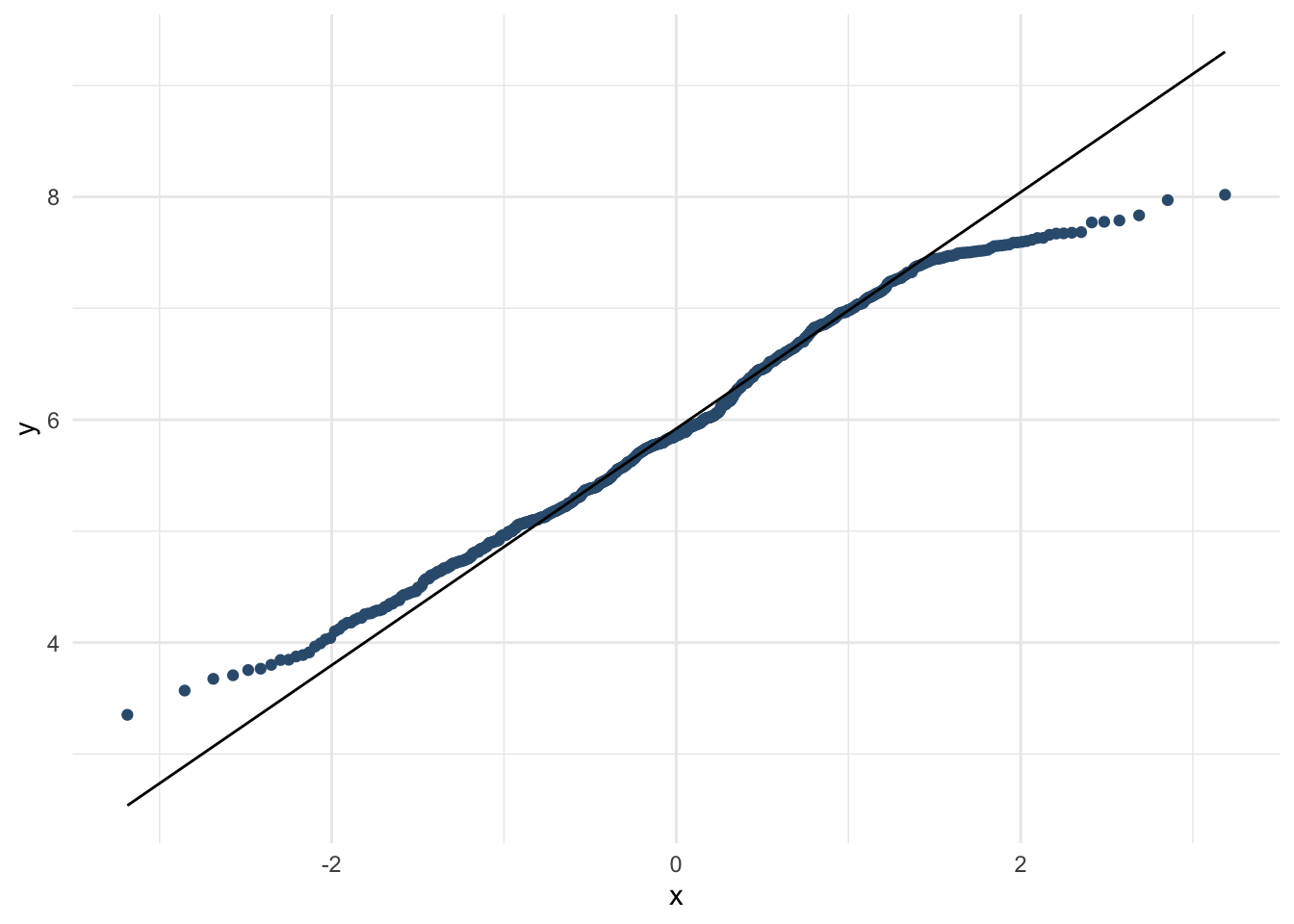
whr_tests_hw %>%
filter(Region == "Central and Eastern Europe" |
Region == "Western Europe" |
Region == "Latin America and Caribbean") %>%
aov(Life_Ladder ~ Region + as.factor(Year), data = .) -> aov_model3
#на всякий случай сделала as.factor(), он просто превращает число в строку. функции бывают не очень умными и думают, что нужнобрать числовую переменную
# как число, даже если задаем ее как группирующую переменную (фактор)
summary(aov_model3)## Df Sum Sq Mean Sq F value Pr(>F)
## Region 2 273.0 136.51 271.048 <0.0000000000000002 ***
## as.factor(Year) 11 6.8 0.62 1.229 0.263
## Residuals 681 343.0 0.50
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Формула записи
dependent var ~ independen var 1 + independent var 2
означает, что я учитываю два фактора независимо друг от друга. Но бывает, что меня интересует взаимодействие факторов: может, в некоторых регионах за эти годы особо ничего не менялось, уровень счастья измеренный как Life_Ladder был постоянным, а в каких-то регионах произошел огромный рост (или огромный отрицательный рост) уровня счастья? Тогда мне нужно будет проверить взаимодействие факторов, и формула будет такая:
dependent var ~ independen var 1 * independent var 2
Везде, где меня интересует взаимодействие, вместо плюсика ставлю звездочку.
whr_tests_hw %>%
filter(Region == "Central and Eastern Europe" |
Region == "Western Europe" |
Region == "Latin America and Caribbean") %>%
aov(Life_Ladder ~ Region * as.factor(Year), data = .) -> aov_model4
summary(aov_model4)## Df Sum Sq Mean Sq F value Pr(>F)
## Region 2 273.0 136.51 274.254 <0.0000000000000002 ***
## as.factor(Year) 11 6.8 0.62 1.244 0.254
## Region:as.factor(Year) 22 15.0 0.68 1.366 0.123
## Residuals 659 328.0 0.50
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Видим, что во втором случае у нас появилась еще одна строчка – Region:Year. Это как раз взаимодействие двух факторов. И оно, между прочим, значимо! То есть предположение о том, что в разных регионах разная динамика изменения уровня счастья по годам – верное.
Далее, чтобы определить, что именно было значимо, делаем пост-хоки.
Я не буду выводить табличку – она получается монструозной из-за того, что мы взяли года, а они начинаются с 2005 года: представьте, сколько там попарных сравнений…
14.13.1.4 ANOVA с повторными измерениями
Вообще-то переменная год – внутригрупповой фактор. И если быть честными, ее не очень хорошо учитывать так же, как и фактор Регион, иначе мы потеряем много информации. В R ANOVA с повторными измерениями можно сделать, задав дополнительные параметры в функции aov(), либо с уже знакомой нам функцией ezANOVA(), либо с помощью очень похожей функции anova_test()
whr_tests_hw %>%
filter(Region == "Central and Eastern Europe" |
Region == "Western Europe" |
Region == "Latin America and Caribbean") %>%
filter(Year > 2010) %>% #возьму года после 2010, чтобы было поменьше
drop_na(Life_Ladder, Year) %>% #удаляю пропущенные значения в интересующих меня колонках
aov(Life_Ladder ~ Year + Error(Country/Year), .) %>%
summary()## Warning in aov(Life_Ladder ~ Year + Error(Country/Year), .): Error() model is
## singular##
## Error: Country
## Df Sum Sq Mean Sq F value Pr(>F)
## Year 1 8.94 8.935 2.095 0.152
## Residuals 71 302.81 4.265
##
## Error: Country:Year
## Df Sum Sq Mean Sq F value Pr(>F)
## Year 1 0.003 0.0027 0.01 0.919
## Residuals 70 18.106 0.2586
##
## Error: Within
## Df Sum Sq Mean Sq F value Pr(>F)
## Residuals 270 12.92 0.04784Как задать эту формулу: если фактор появляется несколько раз для одного и того же испытуемого или страны в данном случае, то формула записи будет такой
dependent var ~ independen var + Error(ID/independen var)
Более человеческий синтаксис у функции anova_test, но она очень чувствительна к данным, и на этих данных, например, не построилась. Позже я поняла, почему: я забыла сделать проверку на идентичность дисперсий, вот модель и не сходится! Но мне уже лень переписывать..
14.13.2 Решейпинг
Бывает так, что для тестов с повторными измерениями некоторые функции принимают на вход данные в другом формате. Например, ровно так произошло в Jamovi. Обратите внимание, как данные о повторных измерениях у нас выглядят сейчас: у нас есть колонка Year, в которой перечислены года, и колонка Life_Ladder, в которой перечислены соответствующие этим годам значения.
whr_tests_hw %>%
select(Country, Year, Life_Ladder) %>%
filter(Year>2010) %>%
head() #выводит заголовок таблички, первые 10 строк## # A tibble: 6 × 3
## Country Year Life_Ladder
## <chr> <dbl> <dbl>
## 1 Denmark 2016 7.56
## 2 Denmark 2011 7.79
## 3 Denmark 2012 7.52
## 4 Denmark 2013 7.59
## 5 Denmark 2014 7.51
## 6 Denmark 2015 7.51Такой формат данных называется длинным (без шуток, так и называется!), потому что данные вытянуты в длину, вместо того, чтобы каждая строка состояла из уникальных данных (обратите внимание на колонку Country – там повторяющие значения, потому что у нас много замеров в разные года для каждой страны). Иногда бывает нужно перевести данные в широкий формат – чтобы значения в строчках не повторялись, но вместо двух колонок у нас появилась по колонке с измерениями Life_Ladder за каждый год. Такое преобразование называется решейпинг данных, как бы изменение их формы. Преобразовать вид данных из длинного в широкий формат или обратно можно с помощью функций pivot_wider pivot_longer. В Jamovi решейпинг, к сожалению, не реализован.
whr_tests_hw %>%
select(Country, Year, Life_Ladder) %>%
filter(Year>2010) %>%
pivot_wider(names_from = Year, values_from = Life_Ladder) %>%
head()## # A tibble: 6 × 7
## Country `2016` `2011` `2012` `2013` `2014` `2015`
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Denmark 7.56 7.79 7.52 7.59 7.51 7.51
## 2 Switzerland 7.46 NA 7.78 NA 7.49 7.57
## 3 Iceland 7.51 NA 7.59 7.50 NA 7.50
## 4 Norway 7.60 NA 7.68 NA 7.44 7.60
## 5 Finland 7.66 7.35 7.42 7.44 7.38 7.45
## 6 Canada 7.24 7.43 7.42 7.59 7.30 7.4114.14 Задания после семинара 6
Проверьте несколько гипотез на датасете whr_tests_hw с помощью ANOVA и линейного регресионного анализа: выберете подходящие для этих тестов переменные, сформулируйте гипотезу, сформулируйте \(H_0\) и \(H_1\), выберете уровень \(\alpha\), (если нужно, предобработайте данные), проверьте допущения для тестов.
- Выберете подходящие переменные, сформулируйте осмысленную гипотезу и проверьте ее с помощью однофакторной ANOVA. Проинтерпретируйте результаты: подвердилась ли гипотеза?
- Выберете подходящие переменные, сформулируйте осмысленную гипотезу и проверьте ее и проверьте ее с многофакторной ANOVA. Проинтерпретируйте результаты: подвердилась ли гипотеза?
- Выберете подходящие переменные, сформулируйте осмысленную гипотезу и проверьте ее с помощью ANOVA c повторными измерениями. Проинтерпретируйте результаты: подвердилась ли гипотеза?
- Проведите те же самые проверки гипотез 1-3 с помощью линейного регрессионного анализа.
14.15 Линейный регрессионный анализ
Теперь перейдем к однму из самых важных методов в анализе данных, в том числе, психологических – линейной регрессии. Первым делом нужно вспомнить, когда используется этот метод – а используется он, когда и ЗП, и НП – количественные. Когда мы говорили про корреляции, мы обсуждали, что это упрощенный вариант линейной регрессии, когда у нас только одна НП. Для однй НП мы можем сделать и корреляционный тест, и регрессионный анализ, а вот когда количественных НП две и более – уже тольк регрессионный. Также мы обсуждали, что ANOVA – на самом деле тоже подвид линейной регрессии, если уходить от количественных НП к категориальным! Но обо всем по порядку, начнем с количественных НП, более классического случая линейной регрессии.
Прежде, чем строить регрессионную модель, нам нужно проверить допущения для линейной регрессии
Обратите внимание – нас тут уже не очень интересует, насколько нормально распределена ЗП! В этом сила линейной реггрессии, что она устойчива к ЗП разных распределений. Но другое допущение, касающееся распределения данных по ЗП – это линейность между НП и ЗП, на которых мы хотим строить модель, нужно убедиться, что между ними есть линейная связь (а не дырка от бублика или сущность в виде гномика). Это первое допущение.
Я выбрала для анализа гипотезу о том, что уровень счастья по субъективному расположению на лестнице Life_Ladder, зависит от параметров Log_GDP_per_capita (покупательская способность, ВВП на душу населения), Social_support, Freedom_to_make_life_choices, Perceptions_of_corruption.
Проверим допущение о линейной связи между ЗП Life_Ladder и нескольких потенциальных переменных, которые я выбрала для анализа.
whr_tests_hw %>%
ggplot(aes(x = Log_GDP_per_capita, y = Life_Ladder)) +
geom_point(color = "#355C7D", size = 1) +
theme_minimal()## Warning: Removed 15 rows containing missing values (`geom_point()`).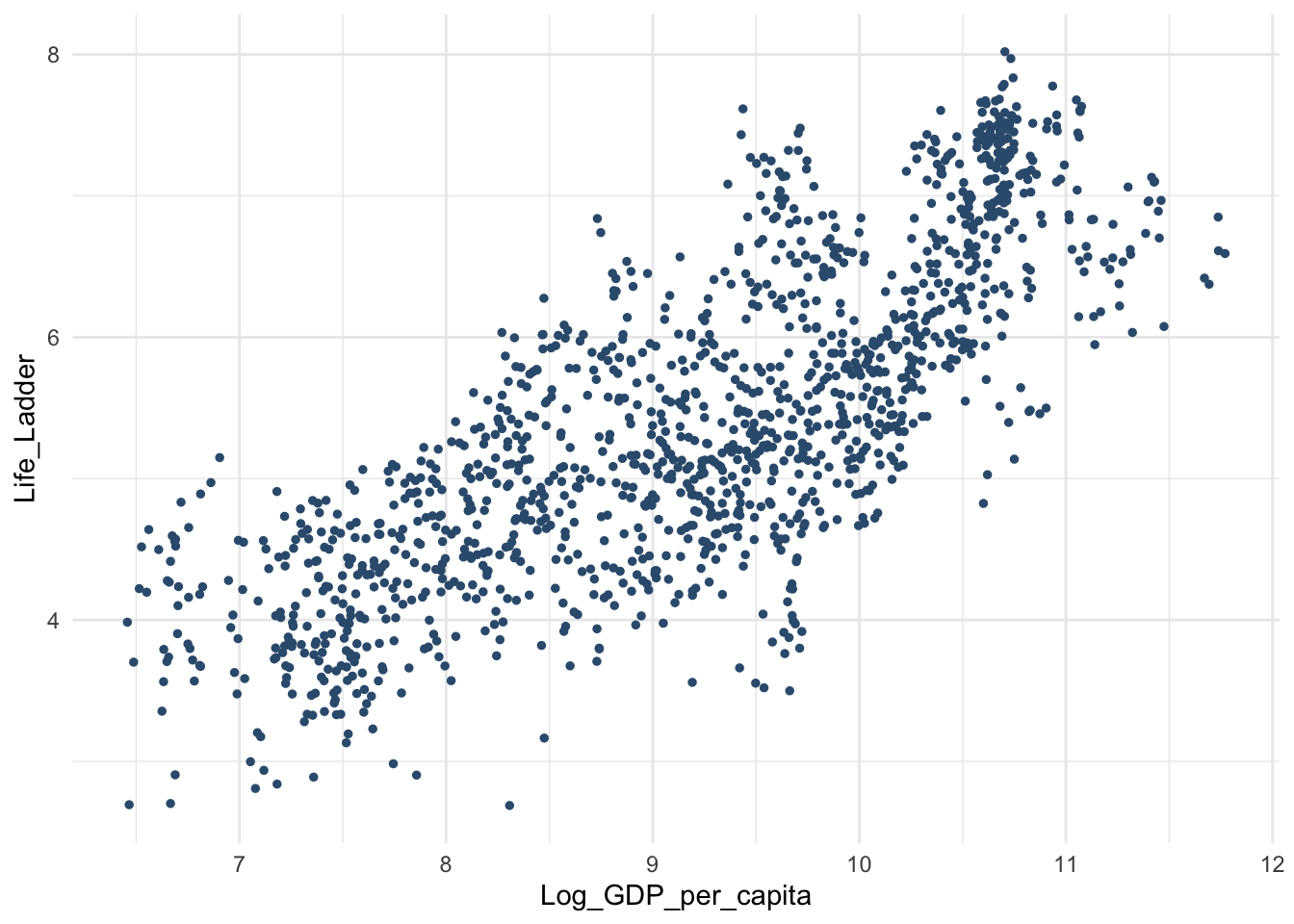
whr_tests_hw %>%
ggplot(aes(x = Social_support, y = Life_Ladder)) +
geom_point(color = "#355C7D", size = 1) +
theme_minimal()## Warning: Removed 12 rows containing missing values (`geom_point()`).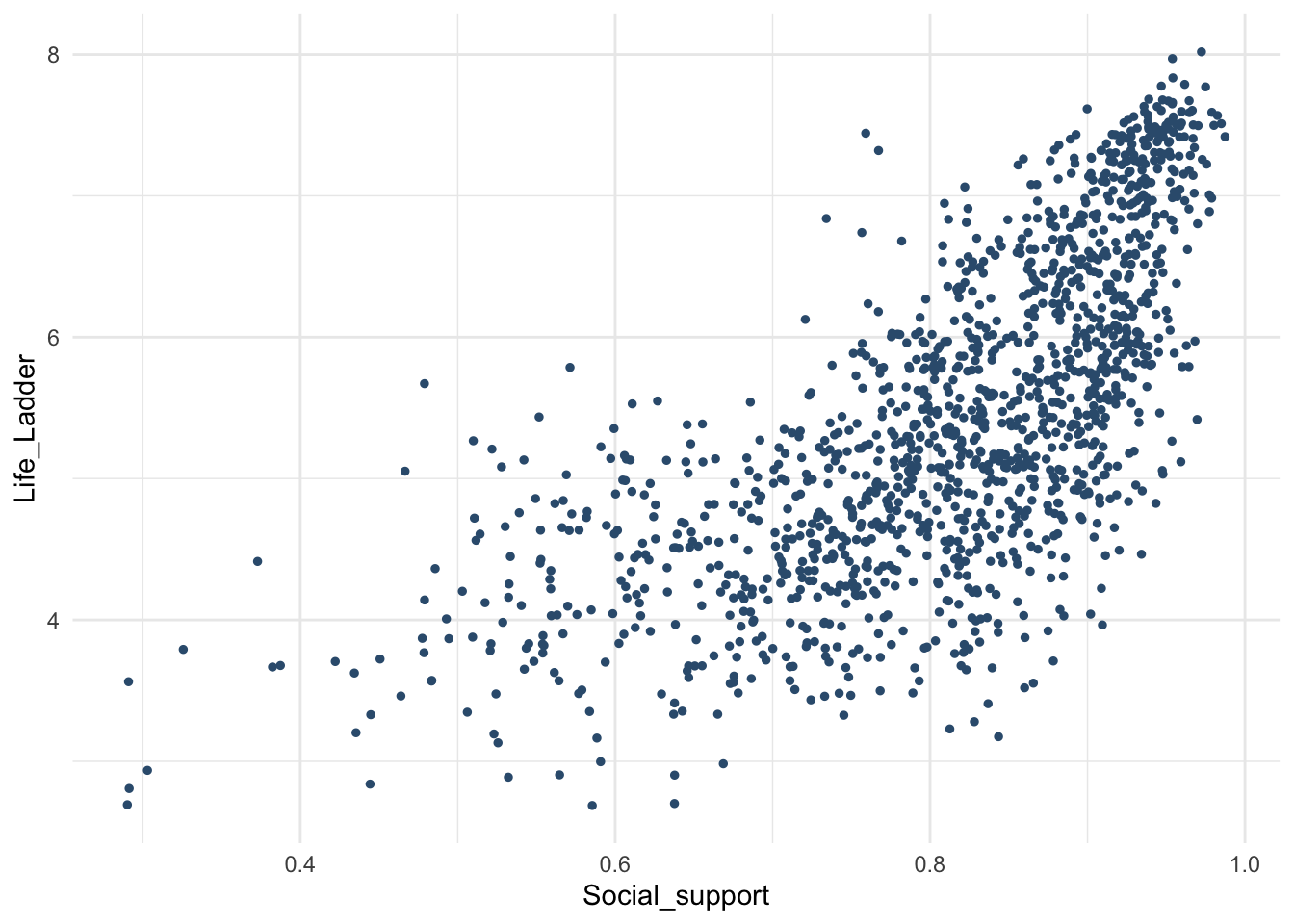
whr_tests_hw %>%
ggplot(aes(x = Freedom_to_make_life_choices, y = Life_Ladder)) +
geom_point(color = "#355C7D", size = 1) +
theme_minimal()## Warning: Removed 28 rows containing missing values (`geom_point()`).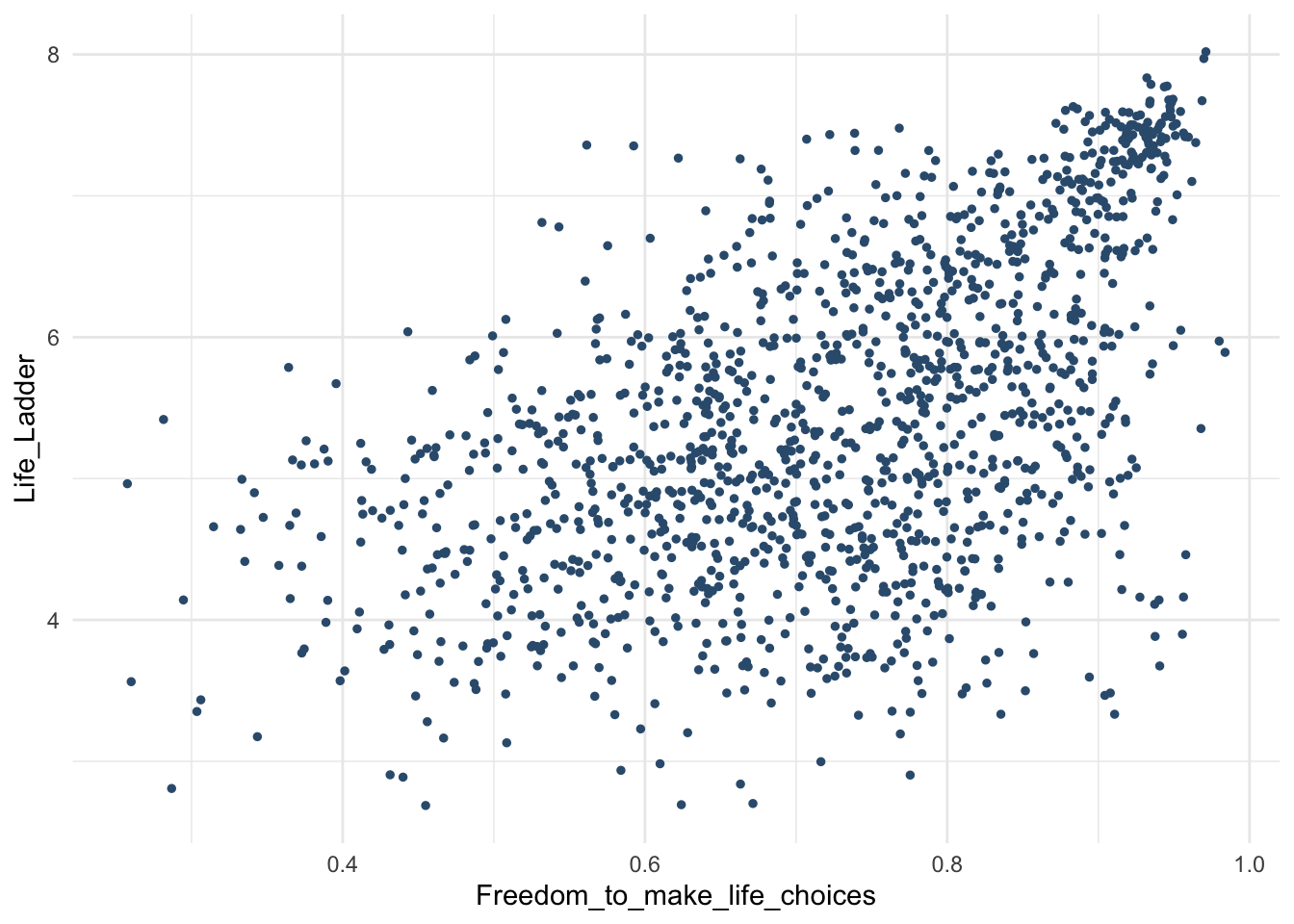
whr_tests_hw %>%
ggplot(aes(x = Perceptions_of_corruption, y = Life_Ladder)) +
geom_point(color = "#355C7D", size = 1) +
theme_minimal()## Warning: Removed 78 rows containing missing values (`geom_point()`).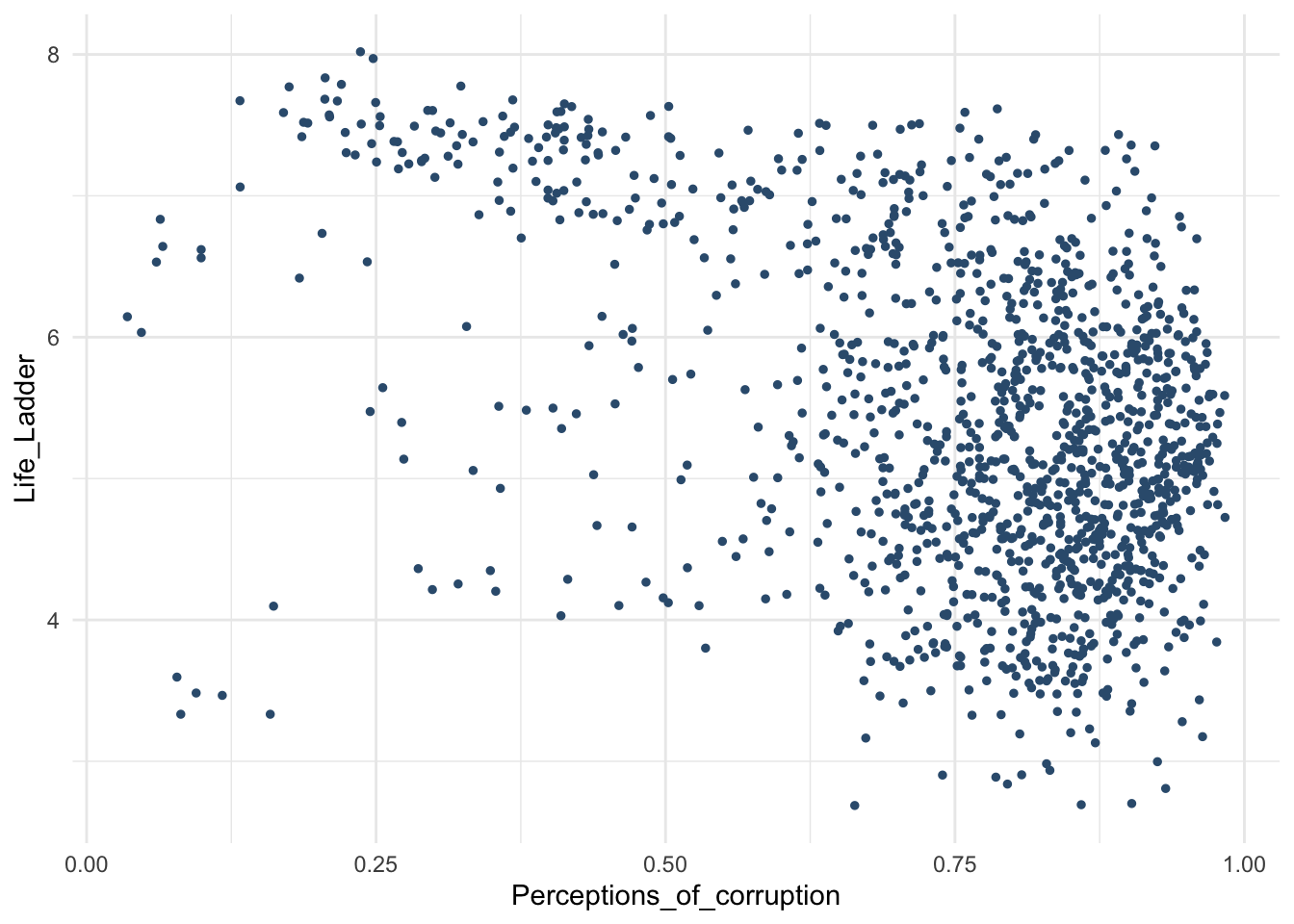
Вижу, что переменная Log_GDP_per_capita показывает очень хорошую линейную связь, близко к этому переменная Freedom_to_make_life_choices. Переменная Social_support мне не очень нравится, но я могу попробовать ее преобразовать в процессе, а вот переменная Perceptions_of_corruption выглядит откровенно плохо, возьму ее в качестве антипримера.
14.15.1 Линейная регрессия с одним предиктором (фактором)
Построю для начала модель с одним факторов – Log_GDP_per_capita. Модель строится помощью функции lm(), чтобы вывести основную информацию о модели нужно вывести summary(). Еще, кстати, можно вывести эти результаты сразу в виде ANOVA – это все потому, что, по сути, это подвид той же линейной регрессии, и если нам мила сердцу табличка вида ANOVA, можно ее получить просто применив функции к модели anova()
whr_tests_hw %>%
lm(Life_Ladder ~ Log_GDP_per_capita, .) -> lm_model1
# напомнию, что точка означает, что именно в этом месте нужно передать в функцию данные
# полученные на предыдущей строчке пайпа. Посмотрите структуру функции lm() в справке,
# на этом находится аргумент `data = `
lm_model1##
## Call:
## lm(formula = Life_Ladder ~ Log_GDP_per_capita, data = .)
##
## Coefficients:
## (Intercept) Log_GDP_per_capita
## -1.4066 0.7421##
## Call:
## lm(formula = Life_Ladder ~ Log_GDP_per_capita, data = .)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.26515 -0.47805 -0.04913 0.54993 2.01866
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -1.4066 0.1467 -9.587 <0.0000000000000002 ***
## Log_GDP_per_capita 0.7421 0.0158 46.973 <0.0000000000000002 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.7016 on 1404 degrees of freedom
## (15 observations deleted due to missingness)
## Multiple R-squared: 0.6111, Adjusted R-squared: 0.6109
## F-statistic: 2206 on 1 and 1404 DF, p-value: < 0.00000000000000022## Analysis of Variance Table
##
## Response: Life_Ladder
## Df Sum Sq Mean Sq F value Pr(>F)
## Log_GDP_per_capita 1 1086.07 1086.07 2206.5 < 0.00000000000000022 ***
## Residuals 1404 691.07 0.49
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1В целом, мы можем уже начать интерпретировать результаты модели, но пока рановато – сначаоа нужно убедиться в равенстве дисперсий остатков, то есть выполнении допущения о гомоскедастичности (гомогенности) дисперсий. Это проще всего проверить, выведя первый из четырех график, которые выводятся, если передать линейную модель в базовую функцию plot()
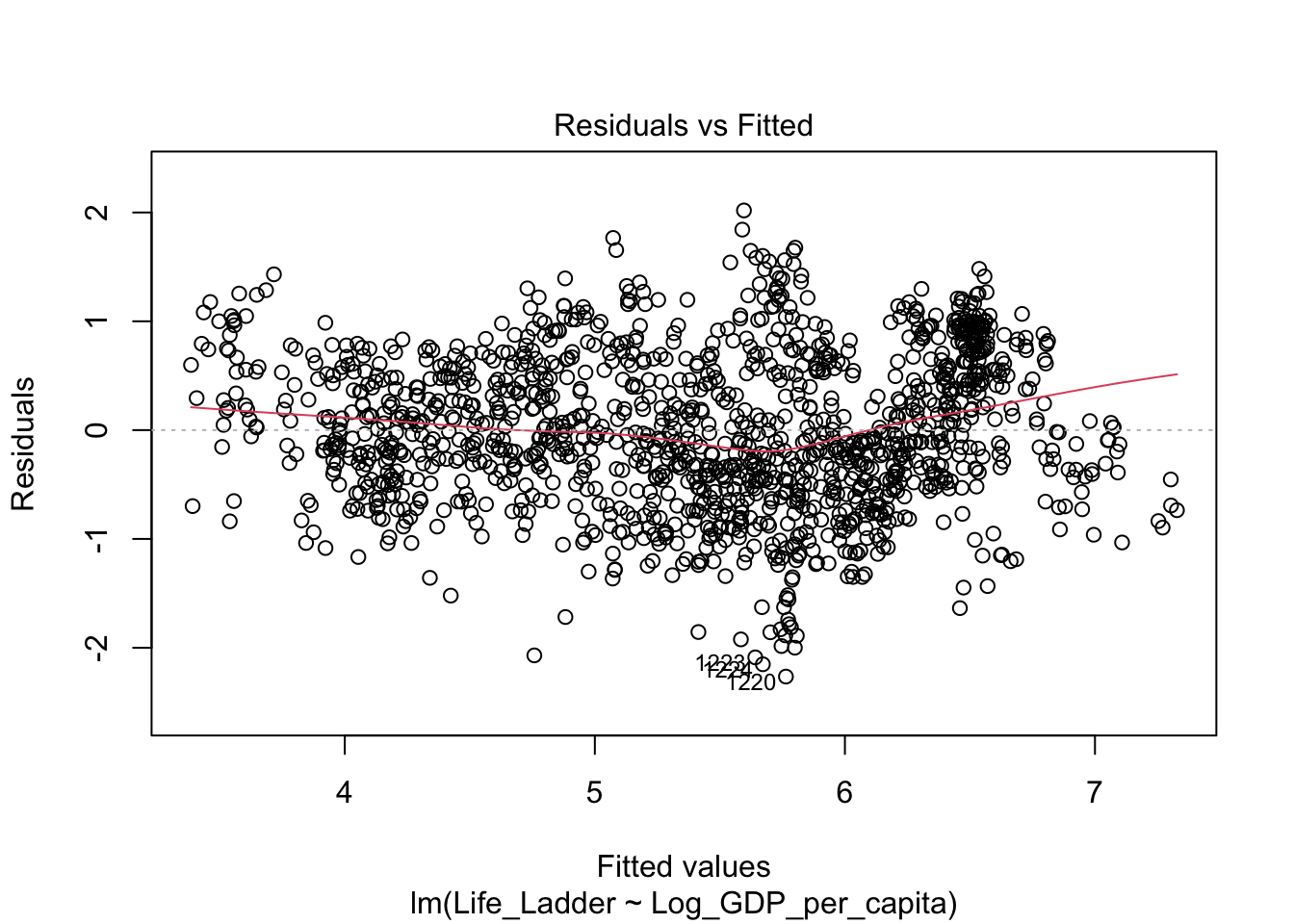
Можем сделать график покрасивее через ggplot(). Для этого воспользуемся тем, что результат выполнения lm() – это список, в котором содержится много разныз данных, в том числе, и остатки модели, и предсказанные значения отдельно.
## 1 2 3 4 5 6
## 0.9974072 1.4818864 1.2677150 1.4125433 1.1663137 1.2430108## 1 2 3 4 5 6
## 6.560375 6.537048 6.566518 6.558349 6.517045 6.527505ggplot(lm_model1, aes(x = lm_model1$fitted.values, y = lm_model1$residuals)) +
geom_point(color = "#355C7D", size = 1) +
theme_minimal()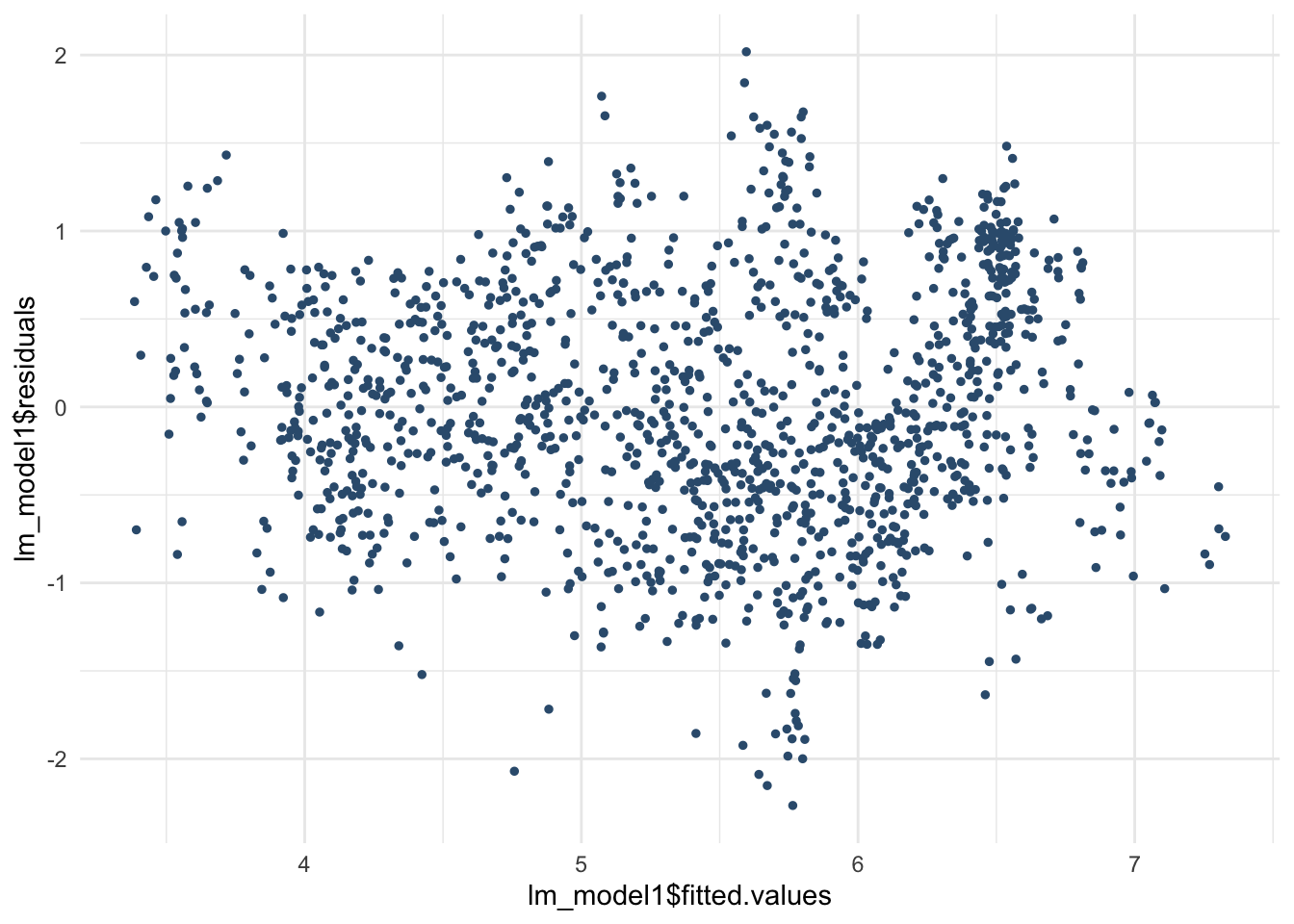 Вспомним примеры диагностических графиков, которые мы разбирали в прошлом семестре Примеры диагностических графиков для остатков: https://gallery.shinyapps.io/slr_diag/ Хорошим счтается график, если при движении слева на право все точки распределены примерно равномерно. А вот есть у нас вылез веник, что с одной стороны данные скукожились в одну точку, а дальше пошли расходиться веником – это означает, что в данных наблюдается гетероскедастичность, они не однородны, и результаты такой модели будут не очень достоверны. В нашем случае графико выглядит хорошо и проходит проверку.
Вспомним примеры диагностических графиков, которые мы разбирали в прошлом семестре Примеры диагностических графиков для остатков: https://gallery.shinyapps.io/slr_diag/ Хорошим счтается график, если при движении слева на право все точки распределены примерно равномерно. А вот есть у нас вылез веник, что с одной стороны данные скукожились в одну точку, а дальше пошли расходиться веником – это означает, что в данных наблюдается гетероскедастичность, они не однородны, и результаты такой модели будут не очень достоверны. В нашем случае графико выглядит хорошо и проходит проверку.
А теперь давайте возьмем антипример и посмотрим, что будет с распределением остатков.
whr_tests_hw %>%
lm(Life_Ladder ~ Perceptions_of_corruption, .) -> lm_model2_anti
plot(lm_model2_anti, 1)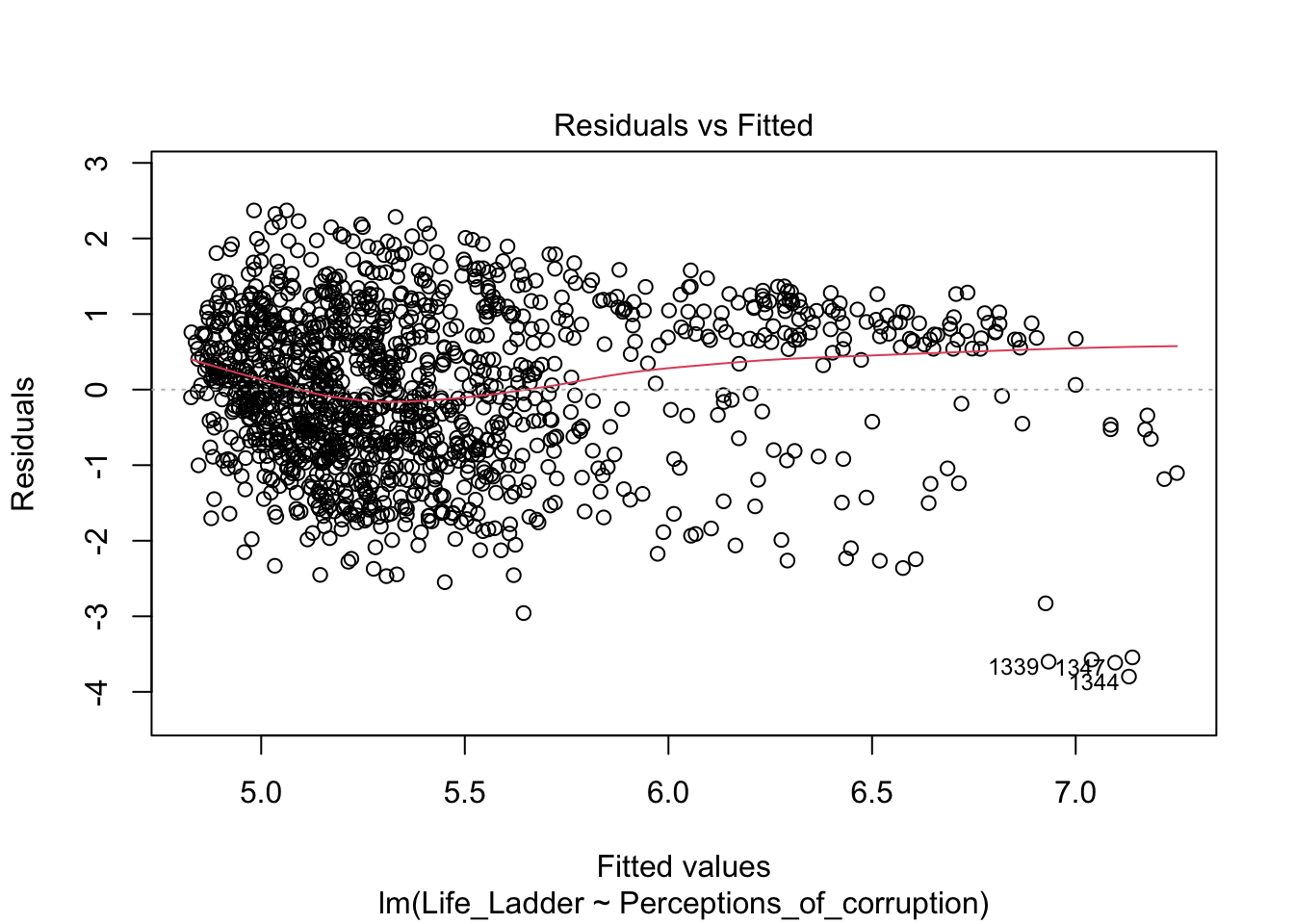
Тут что-то пошло не так, поэтому опираться на такую модель мы бы не стали.
Следующее допущение – остатки должны быть нормально распределены. Да, мы не проверяем на нормальность распределения ЗП, но вот остатки нужно проверить – иначе мы не сможем провести линия с расчетом метода нименьших квадратов, то есть пытаясь приблизиться ко всем нашим точкам сразу. Проверим это допущения, выведя второй график стандартной функции plot()
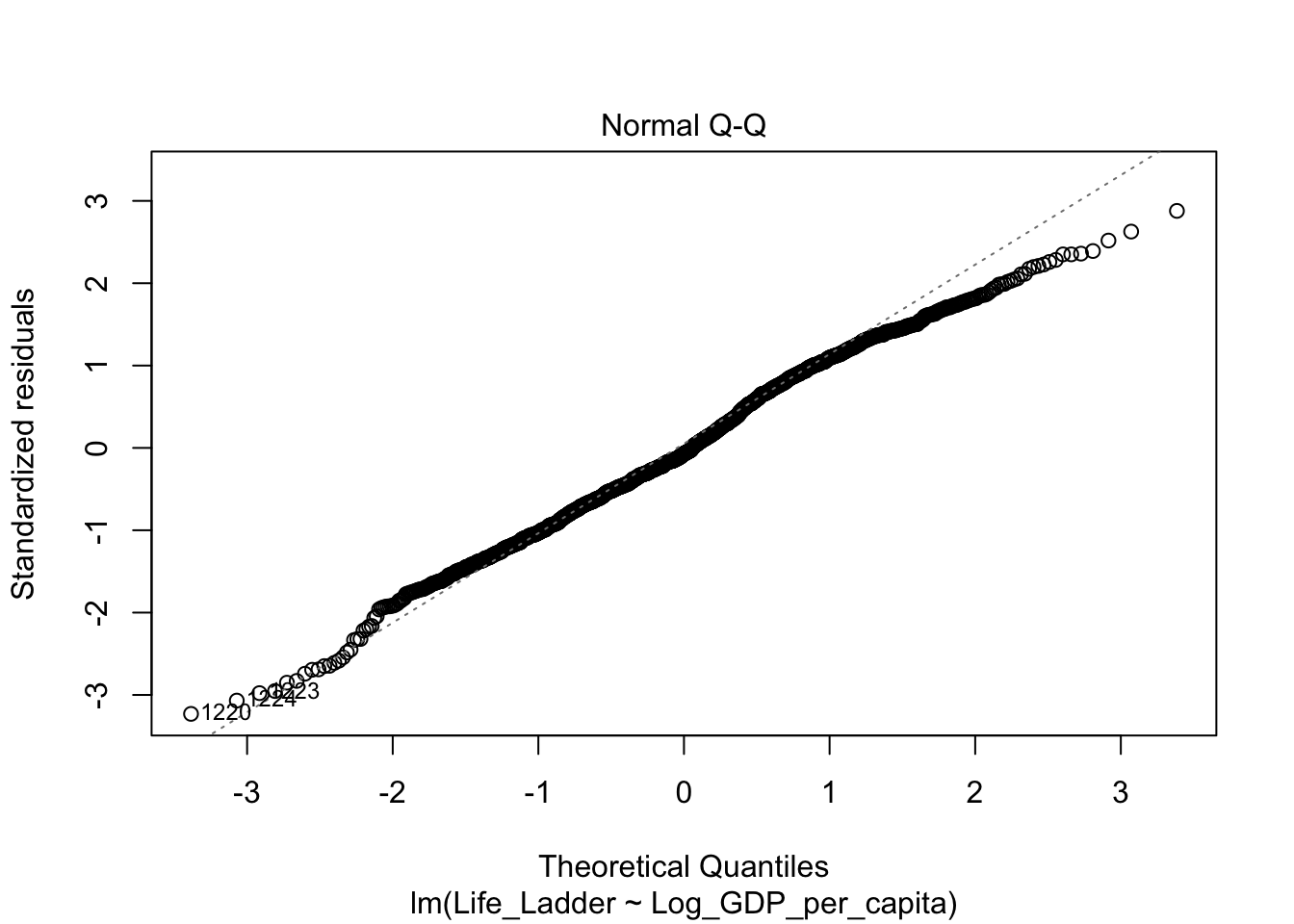 Или, как мы уже строили красивые графики для проверки нормальнсти через ggplot
Или, как мы уже строили красивые графики для проверки нормальнсти через ggplot
ggplot(data = lm_model1, aes(x = lm_model1$residuals)) +
geom_density(color = "#355C7D") +
theme_minimal()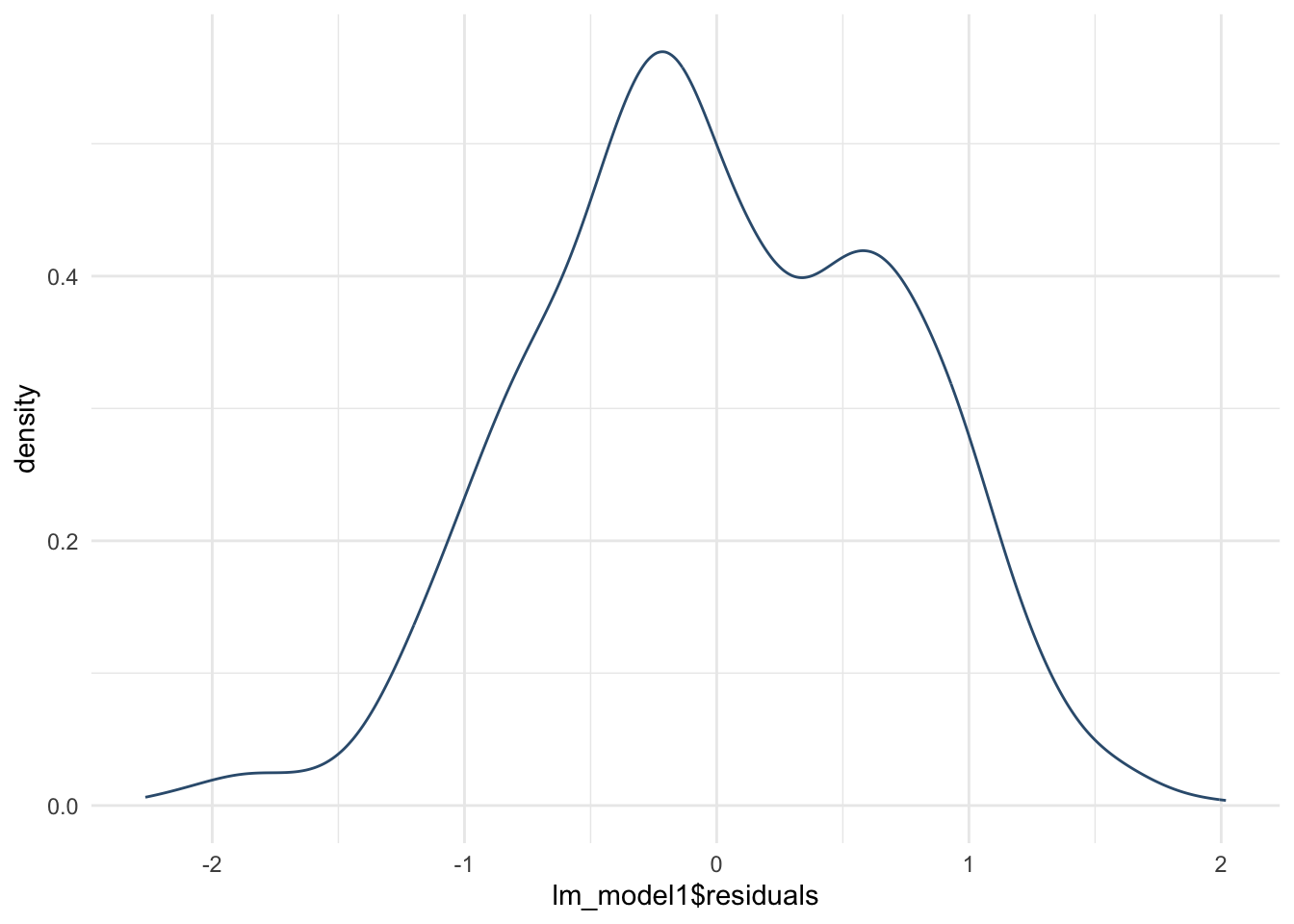
ggplot(data = lm_model1, aes(sample = lm_model1$residuals)) +
stat_qq(color = "#355C7D") +
geom_qq_line() +
theme_minimal()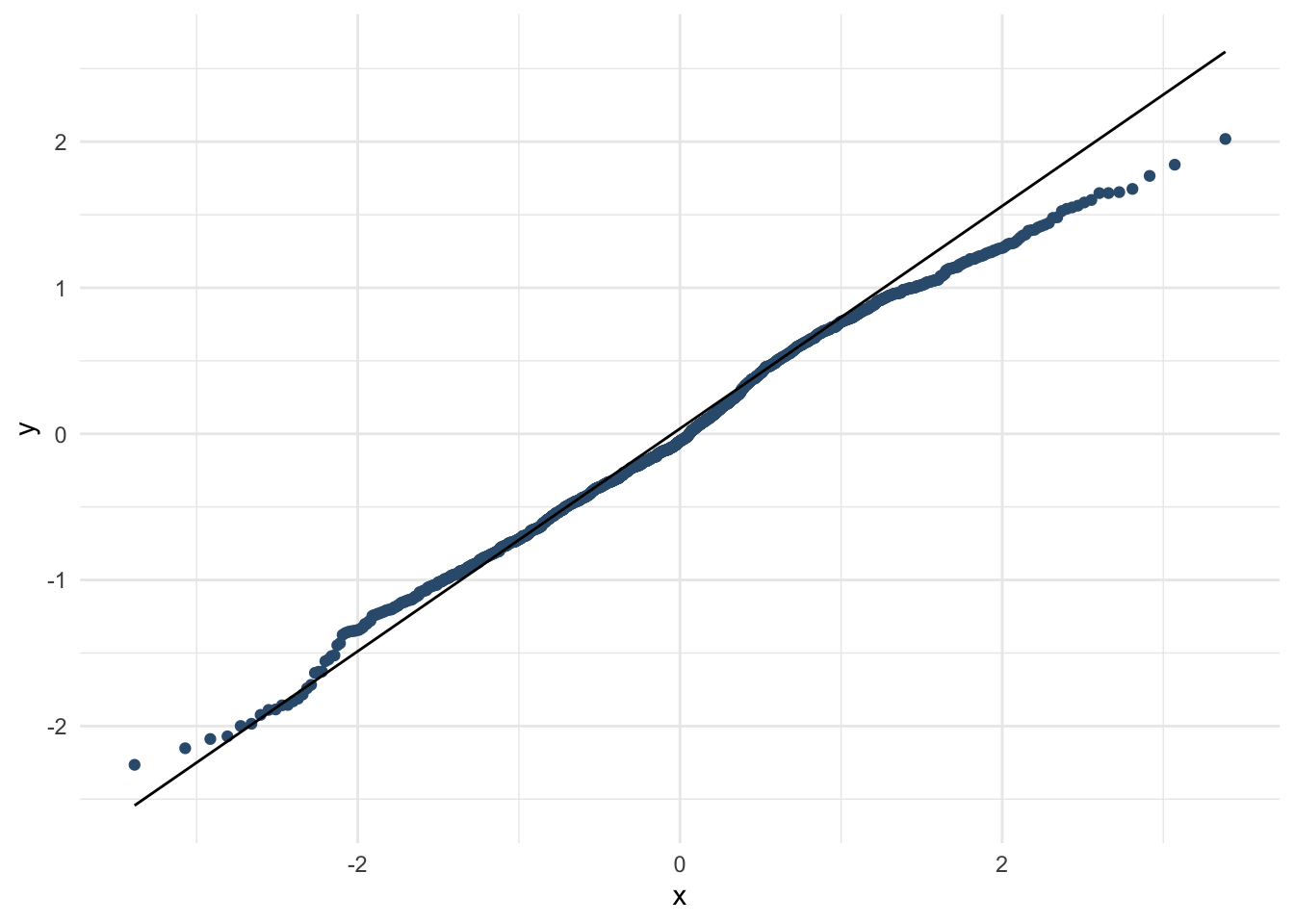
И так, мы соблюли все допущения для модели с одним предиктором! У нас осталось только допущения отсутствия мультиколлинеарности, но оно не применимо на модели с одним предиктором.
Теперь давайте еще раз посмотрим на результаты модели и вспомним, как их интерпретировать. Ключевое, что нас интересует – это коэффициенты линейной регрессии, \(b_0\), интерцепт, место пересечения регрессионной прямой с осью y, и \(b_1\), слоуп, угол наклона прямой – так как нулевая гипотеза для линейной регрессии заключается в равенстве их нулю. Еще одна не менее важная штука – \(R^2\), коэффициент детерминации и процент объясненной дисперсии.
##
## Call:
## lm(formula = Life_Ladder ~ Log_GDP_per_capita, data = .)
##
## Coefficients:
## (Intercept) Log_GDP_per_capita
## -1.4066 0.7421##
## Call:
## lm(formula = Life_Ladder ~ Log_GDP_per_capita, data = .)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.26515 -0.47805 -0.04913 0.54993 2.01866
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -1.4066 0.1467 -9.587 <0.0000000000000002 ***
## Log_GDP_per_capita 0.7421 0.0158 46.973 <0.0000000000000002 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.7016 on 1404 degrees of freedom
## (15 observations deleted due to missingness)
## Multiple R-squared: 0.6111, Adjusted R-squared: 0.6109
## F-statistic: 2206 on 1 and 1404 DF, p-value: < 0.00000000000000022Как обычно, смотрим на p-value у каждого коэффициента (и еще можем посмотреть на p-value всей модели: тут та же итория, как и с ANOVA – вся модель значима, когда значим хотя бы один из коэффициентов, и не значима, когда все коэффициенты не отличаются статистически значимо от нуля). Если коэффициент значим, значит, мы можем сказать, что он значимо вкладывается в объяснение дисперсии. \(b_0\), интерцепт, значимо отличен от нуля, поэтому можем заявить, что наша прямая будет начинаться не в начале координат, а смещена на -1.4 по оси y. \(b_1\) у Log_GDP_per_capita значимо отличен от нуля, пэтому наша прямая будет иметь наклон – а это значит, что с увеличением Log_GDP_per_capita на 1 зависимая переменная Life_Ladder будет увеличиваться на 0.74!
Чему равен \(R^2\)? Он равен 0.61, что очень хороший результат. То есть, 61% изменчивости наших данных по уровню стастья Life_Ladder определяются уровнем покупапательской способнсти Log_GDP_per_capita!
Уравнение регрессионной прямой я теперь могу записать так:
\(\hat Life\_Ladder = -1.4 + 0.74 \times Log\_GDP\_per\_capita\)
Давайте теперь визуалзируем нашу регрессионную прямую
whr_tests_hw %>%
ggplot(aes(x = Log_GDP_per_capita, y = Life_Ladder)) +
geom_point(color = "#355C7D", size = 1, alpha = 0.5) +
geom_smooth(method = 'lm', color = "violet") +
theme_minimal()## Warning: Removed 15 rows containing non-finite values (`stat_smooth()`).## Warning: Removed 15 rows containing missing values (`geom_point()`).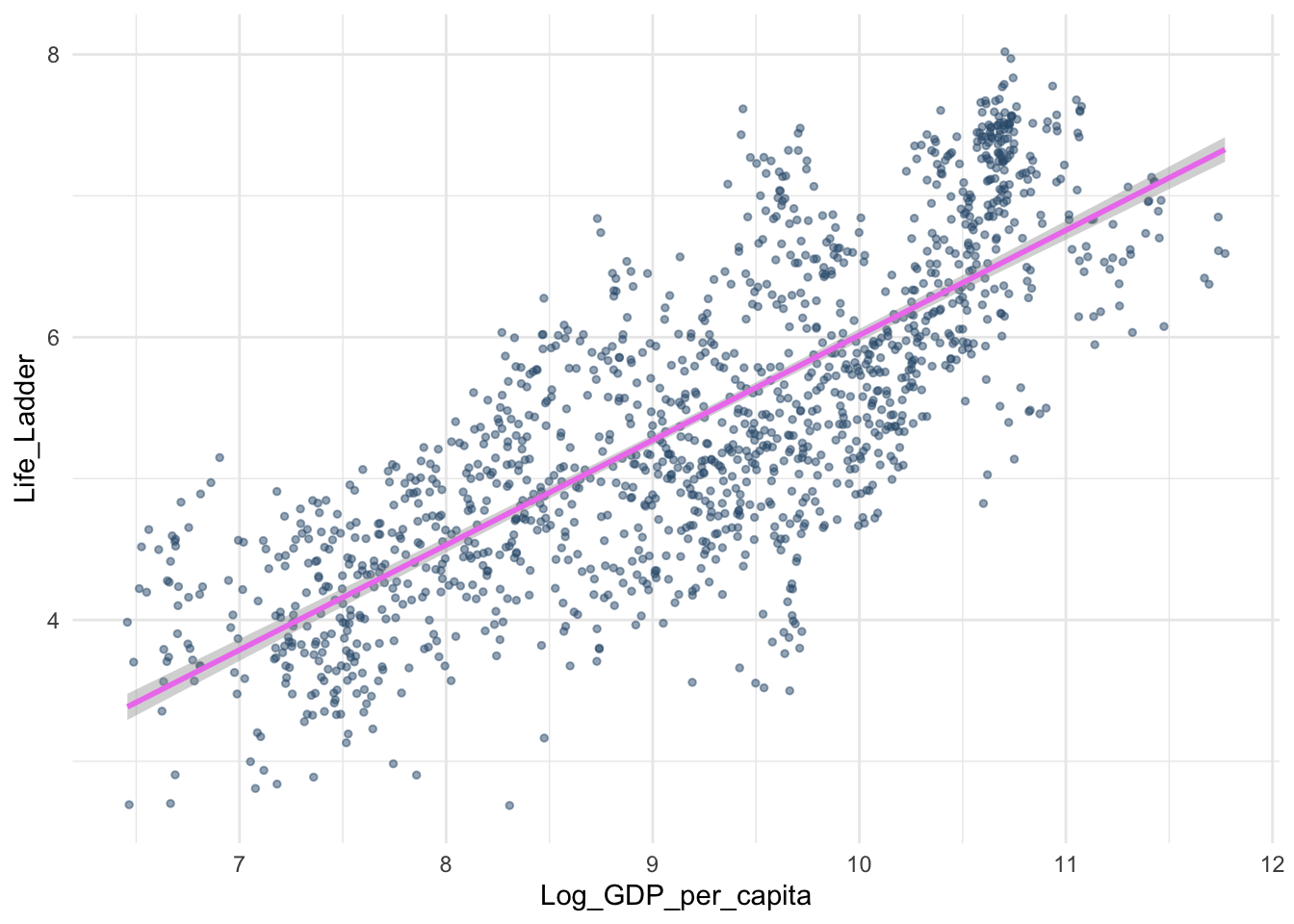
Красота!
14.15.2 Линейная регрессия с несколькими предикторами (факторами)
Все то же самое, но теперь возьмем в модель второй предиктор – Freedom_to_make_life_choices.
whr_tests_hw %>%
lm(Life_Ladder ~ Log_GDP_per_capita + Freedom_to_make_life_choices, .) -> lm_model3_multy
lm_model3_multy##
## Call:
## lm(formula = Life_Ladder ~ Log_GDP_per_capita + Freedom_to_make_life_choices,
## data = .)
##
## Coefficients:
## (Intercept) Log_GDP_per_capita
## -2.0948 0.6478
## Freedom_to_make_life_choices
## 2.1544##
## Call:
## lm(formula = Life_Ladder ~ Log_GDP_per_capita + Freedom_to_make_life_choices,
## data = .)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.50100 -0.43131 0.02093 0.44158 1.83176
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -2.09478 0.14063 -14.90 <0.0000000000000002
## Log_GDP_per_capita 0.64781 0.01562 41.46 <0.0000000000000002
## Freedom_to_make_life_choices 2.15438 0.12663 17.01 <0.0000000000000002
##
## (Intercept) ***
## Log_GDP_per_capita ***
## Freedom_to_make_life_choices ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.6403 on 1375 degrees of freedom
## (43 observations deleted due to missingness)
## Multiple R-squared: 0.6791, Adjusted R-squared: 0.6787
## F-statistic: 1455 on 2 and 1375 DF, p-value: < 0.00000000000000022Проверка допущений
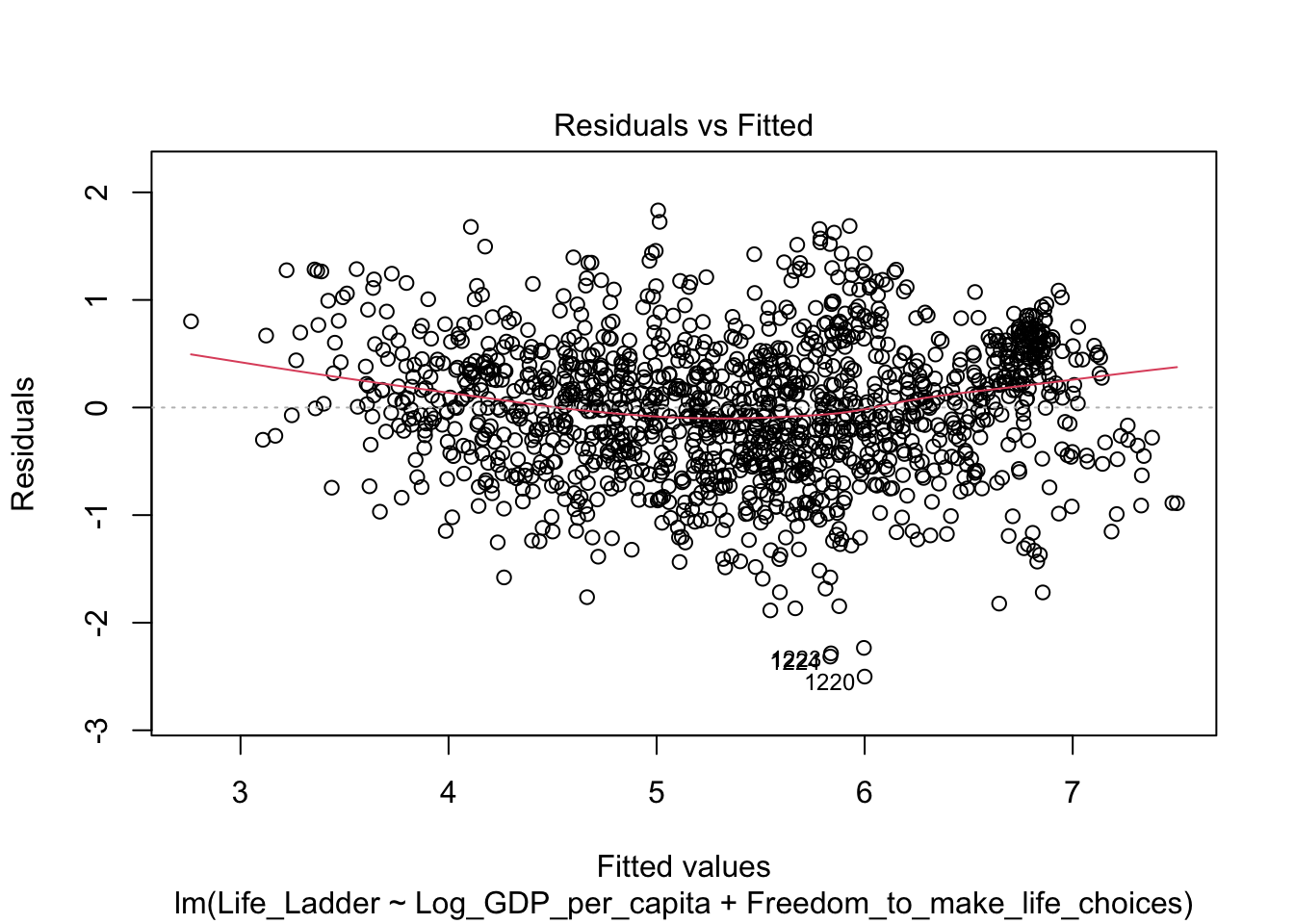
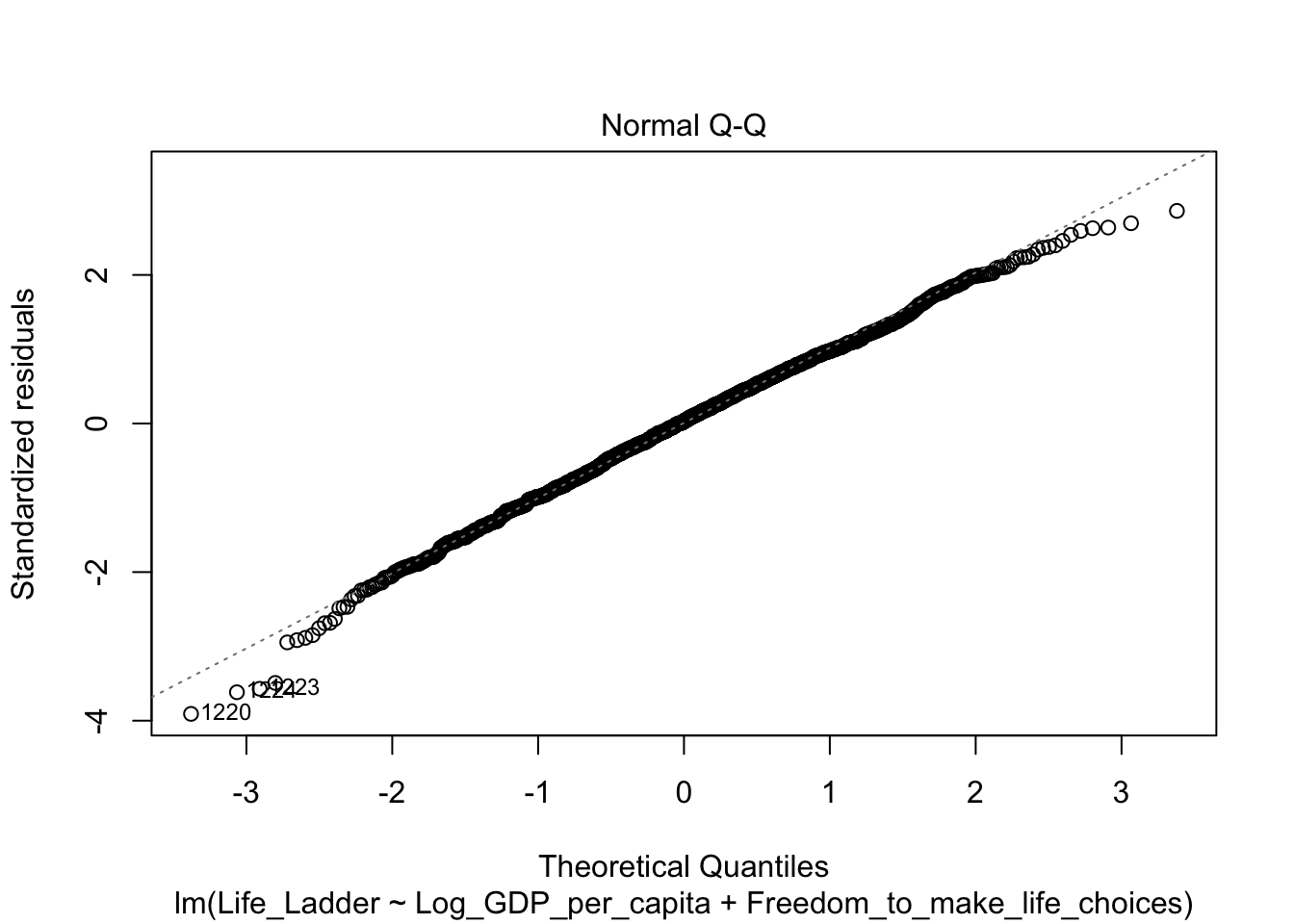
Теперь нужно проверить еще допущение об отсутствии мультиколлинеарности – что среди предикторов (НП) нет сильной корреляции друг с другом, иначе наша модель будет немного бессмысленна. Проверять будем с помощью функции vif(), коэффициента вздутия дисперсии. Показатели довольно условные, но считается, если значения больше 5 – то это очень сильная корреляция между переменными, и нужно удалить сильно коррелирующую переменную.
## Log_GDP_per_capita Freedom_to_make_life_choices
## 1.153419 1.153419У нас показания vif довольно низкие, поэтому ничего не будем менять.
Далее можем проинтерпретировать результаты (все коэффициенты значимы) и записать уравнение регрессионной прямой.
\(\hat Life\_Ladder = -2.09 + 0.64 \times Log\_GDP\_per\_capita + 2.15 \times Freedom\_to\_make\_life\_choices\)
14.16 Задания после семинара 7
- Отберите переменные, подходящие для построения линейной регрессии, в данных
whr_tests_hw.csv - Постройте линейную регрессию на этих переменных, с одним фактором (НП)
- Постройте линейную регрессию на этих переменных, но уже хотя бы с двумя факторами (НП)
- Постройте диагностические графики для каждой модели: насколько равной получилась дисперсия остатков для этих моделей? Можно ли доверять результатом этих моделей?
- Определеите, какая модель лучше объясняет данные (то есть вариативность ЗП)?
- Запишите уравнение линейной регрессии для обеих моделей.
14.17 Логистическая регрессия
Перейдем от линейной регрессии к логистической. Сначала вспомним, что это за метод, и когда используется – он используется, когда ЗП не количественная, а категориальная, и, как правило, имеет две градации. Это самый классический случай логистической регрессии, хотя ЗП в ней может иметь и большее количество градаций, чем две – тогда это будет уже мультиномиальная логистическая регрессия. На лог регрессии построено все машинное обучение – задачи, в которых нужно определить, относится ли изображение к определенному шаблону (например, распознавание текста), является ли кредитный заемщик благонадежным для выдачи кредиты (скоринговые модели в банках) и тд используют именно этот метод.
Мы рассмотрим его на все том же примере наших данных с World Happiness Report. Они не очень подходят для этого метода, поэтому задача будет немного искусственной – попроуем предсказать, будет ли попадать страна в первую или вторую половину рейтнга по уровню счастья (мы создавали специальную переменную для этого). Сначала я перекодирую эту переменную в 1 и 0, так как лог регрессия работает с численными значениями 0 и 1.
Сначала построим самую простую модель, в которую будет входить только интерцепт. Эта модель, по сути, аналог хи квадрата – не имея никаких предикторов оценить, попадет ли страна в первую или вторую половину рейтинга, чисто на основании частоты встречаемости стран из первой и второй половины? Конкретно в этом примере частоты будут примерно одинаковыми, но прицнип работы этой модели примерно такой.
##
## lower upper
## 78 75whr_tests_hw %>%
glm(mean_position_bi ~ 1, data = ., family = binomial) -> lm_model_log1
summary(lm_model_log1)##
## Call:
## glm(formula = mean_position_bi ~ 1, family = binomial, data = .)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.161 -1.161 -1.161 1.194 1.194
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -0.03922 0.16172 -0.243 0.808
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 212.04 on 152 degrees of freedom
## Residual deviance: 212.04 on 152 degrees of freedom
## (1268 observations deleted due to missingness)
## AIC: 214.04
##
## Number of Fisher Scoring iterations: 3## [1] -0.03922071Усложним модель и добавим в нее ВВП на душу населения в качестве предиктора
whr_tests_hw %>%
glm(mean_position_bi ~ Log_GDP_per_capita, ., family = binomial) -> lm_model_log2
summary(lm_model_log2)##
## Call:
## glm(formula = mean_position_bi ~ Log_GDP_per_capita, family = binomial,
## data = .)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.9946 -0.4687 -0.0601 0.5165 2.1031
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -21.8266 3.5703 -6.113 0.000000000976 ***
## Log_GDP_per_capita 2.3186 0.3758 6.169 0.000000000685 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 207.84 on 149 degrees of freedom
## Residual deviance: 109.90 on 148 degrees of freedom
## (1271 observations deleted due to missingness)
## AIC: 113.9
##
## Number of Fisher Scoring iterations: 6